
Wprowadzenie do SQL-a i baz danych

Bazy danych są wszędzie, niezależnie czy zdajesz sobie z tego sprawę czy nie. Czytając artykuł na swojej ulubionej stronie internetowej możesz mieć niemal 100% pewność, że jest on zapisany w jakiejś bazie danych. Wśród stron internetowych niekwestionowanym liderem jest MySQL. To nie znaczy, że jest to jedyny wybór. Mamy jeszcze takie silniki bazodanowe jak PostgreSQL, SQLite, MSSQL, Oracle i wiele więcej.
Wszystkie wymienione wcześniej silniki są oparte o model relacyjny. A różnica pomiędzy nimi polega na wewnętrznej implementacji. Co przekłada się na przykład na wydajność. Pomimo różnic implementacyjnych jest jedna rzecz, która łączy wszystkie wymienione silniki. Tą rzeczą jest sposób dostępu czyli SQL (ang. Structured Query Language). Choć i na tym poziomie występują pewne różnice.
Czym jest język SQL ?
SQL (ang. Structured Query Language) jest standardem, który powinien nam pozwolić na pracę z dowolnym silnikiem bazodanowym implementującym ten standard.
Wszystkie wymienione silniki zaimplementowały standard SQL wprowadzając drobne modyfikacje. Przez te modyfikacje mówimy o dialektach SQL-a, ale o tym porozmawiamy sobie w osobnym wpisie.
Środowisko pracy
Chcąc się uczyć jak najbardziej efektywnie potrzebowali będziemy środowiska do nauki. Opcji mamy sporo i wszystko jest uzależnione od bazy z jaką chcemy prasować. Ja ze względu na popularność wybrałem bazę MariaDB, która pod kątem dialektu SQL-a jest identyczna jak MySQL.
Dodatkowym atutem MySQL / MariaDB jest dostępność. Ten silnik bazodanowy znajdziecie praktycznie na każdym hostingu, niezależnie czy jest płatny czy darmowy.
Online
Narzędzia udostępniane on-line są alternatywą dla instalowania lokalnie silnika bazodanowego, czy też wykorzystywania hostingu. Jednak ja ze swojej strony nie polecę Ci tego rozwiązania, gdyż ma ono w większości wypadków sporo ograniczeń. A kluczowym ograniczeniem jest brak możliwości zapisu pracy i powrót do niego. Co będzie potrzebne w kolejnych wpisach z tego cyklu.
Poniżej dwa narzędzia, które wydają się dość przyjazne dla użytkownika.
- https://www.w3schools.com/sql/trysql.asp?filename=trysql_select_all
- http://sqlfiddle.com/
Hosting
Opcja numer dwa, czyli wykorzystamy hosting do nauki. Jeśli nie macie dostępu do żadnego hostingu to zapraszam do kolejnego punktu ;)
Tutaj nie ma znaczenia z jakiego hostingu korzystacie, może to być home.pl, zenbox.pl, kei.pl czy inny. Każdy hosting udostępnia wam możliwość założenia bazy danych i zalogowania się do phpMyAdmin-a.
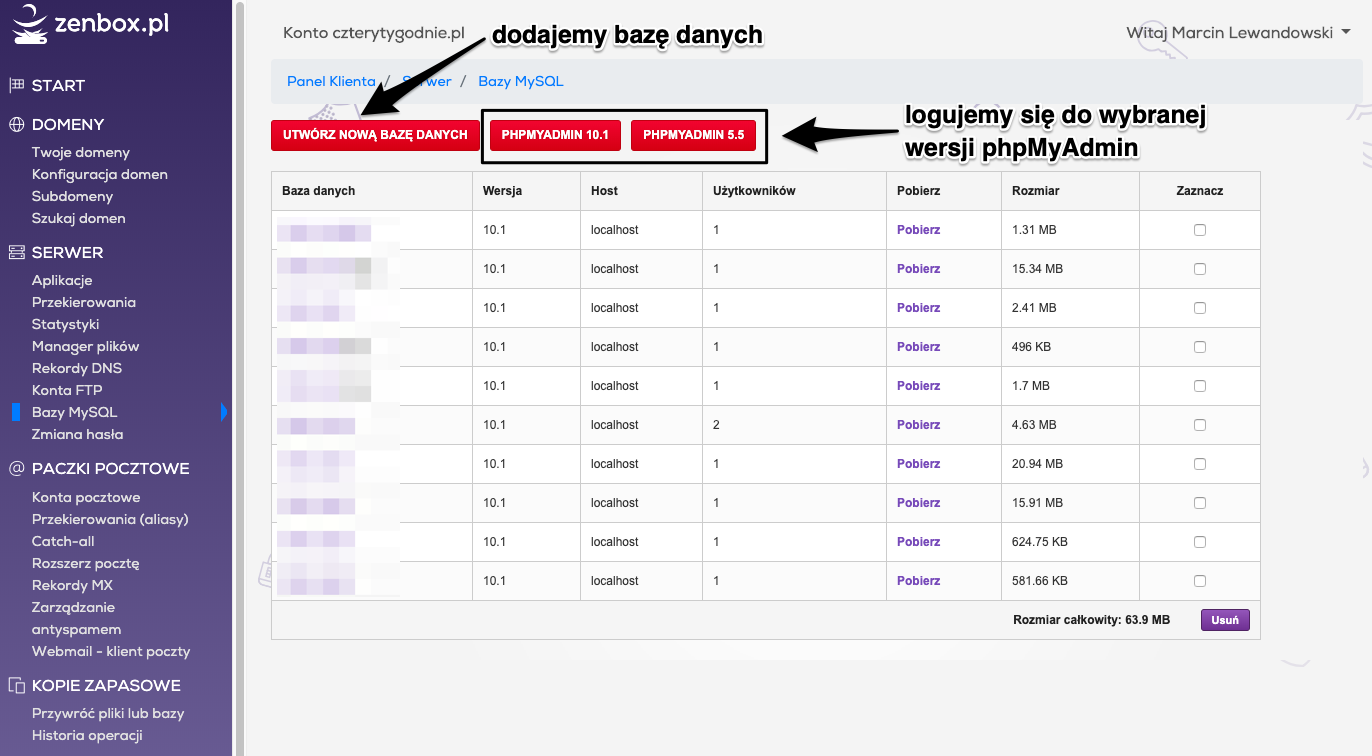
Po utworzeniu bazy testowej logujemy się wybierając wersję phpMyAdmin-a, która nam najbardziej odpowiada. Polecam najnowszą ;)
Praca na lokalnej bazie danych
Osobiście uważam, że najwygodniej pracuje się mając zainstalowany dany silnik bazodanowy. Dlatego u mnie na maszynie znajdziecie silnik MariaDB, który jest kompatybilny z MySQL-em pod kątem dialektu SQL.
Rozumiem że możecie nie chcieć instalować kolejnej aplikacji, dlatego jak zawsze polecę wam Docker-a ;) Mając to rozwiązanie możemy testować różne aplikacje bez potrzeby zaśmiecania systemu. Nie chcecie korzystać z silnika MariaDB, usuwacie kontener, obraz i zapominacie o nieudanej przygodzie.
Docker
Do pracy będziemy potrzebowali Docker-a, którego możecie pobrać i zainstalować z oficjalnej strony lub linii poleceń jeśli pracujecie w linuksie.
Kiedy macie już zainstalowanego i uruchomionego Docker-a to możemy przejść do pobrania niezbędnych obrazów. Zaczynamy od bazy MariaDB.
docker run -d --name 4t-mariadb -e MYSQL_ROOT_PASSWORD=qwerty -p 3307:3306 mariadb
Powyższe polecenie uruchamia nam kontener o nazwie 4t-mariadb na bazie obrazu mariadb. Dodatkowo ustawiliśmy zmienną środowiskową MYSQL_ROOT_PASSWORD, która ustawia hasło do serwera w tym przypadku na qwerty. Jako że w moim przypadku mam zainstalowany lokalnie serwer MariaDB w związku z czym musiałem dodać przekierowanie portów -p 3307:3306. Ustawienie to przekierowuje port 3307 na mojej maszynie na port 3306 w kontenerze.
Mając serwer potrzebny będzie nam klient, a w przypadku MySQL-a i MariaDB najlepszym rozwiązaniem jest phpMyAdmin.
docker run -d --name 4t-phpmyadmin --link 4t-mariadb:db -e PMA_PORT=3307 -p 8888:80 phpmyadmin/phpmyadmin
Nowy kontener został nazwany 4t-phpmyadmin i potrzebuje być połączony z kontenerem serwera bazodanowym. Dlatego dodaliśmy --link 4t-mariadb:db, gdzie musimy podać nazwę kontenera z serwerem baz danych. W związku ze zmianą domyślnego portu 3306 konieczne było odpowiednie ustawienie zmiennej środowiskowej PMA_PORT. Na koniec podajemy na jakim porcie ma być widoczny phpMyAdmin, tutaj został wybrany port 8888 i przekierowany na port 80 kontenera. Po uruchomieniu kontenera możemy przejść do przeglądarki i pod adresem localhost:8888 znajdziemy panel logowania.
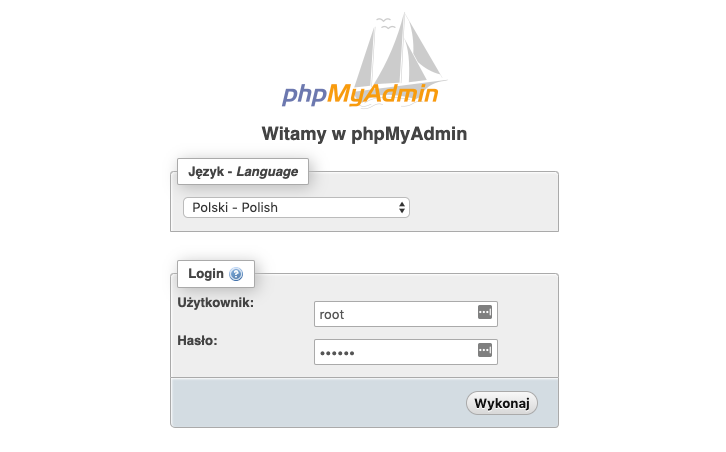
Do panelu logujemy się za pomocą loginu root oraz ustawionego hasła w zmiennej środowiskowej MYSQL_ROOT_PASSWORD, czyli qwerty.
Konsola czy GUI ?
Silnik bazodanowy to aplikacja, która przetwarza przesyłane instrukcje SQL. Jednak nie jest to aplikacja, która umożliwia w jakikolwiek sposób wizualizację przechowywanych danych. To co w większości przypadków widzimy jako “bazę danych” jest klientem. Najczęściej wykorzystujemy aplikacje klienckie posiadające GUI (ang. graphical user interface), czyli graficzny interfejs użytkownika. Przykładem takiej aplikacji jest np. phpMyAdmin czy bardziej rozbudowany MySQL Workbench. Alternatywą dla takich rozwiązań są aplikacje klienckie dostępne z poziomu konsoli. W większości przypadków są one dostarczone z silnikiem bazy danych. Przyjrzyjmy się, obu rozwiązaniom i zobaczmy, które podejście sprawdzi się lepiej.
Klient z GUI
Aplikacje z graficznym interfejsem użytkownika w odróżnieniu od aplikacji konsolowych są bardzo wygodne w użytkowaniu. Jako przykład posłużę się tutaj phpMyAdmin-em, który na tym etapie powinniśmy mieć już pod ręką.
Logowanie
Każdy serwer bazodanowy wymaga od nas zalogowania się na jakiegoś użytkownika. Na tej podstawie jest on w stanie stwierdzić jakie posiadamy uprawnienia i czy w ogóle możemy się zalogować. W przypadku klientów z interfejsem mamy po prostu okienko logowania.
Podajemy login i hasło i jesteśmy zalogowani.
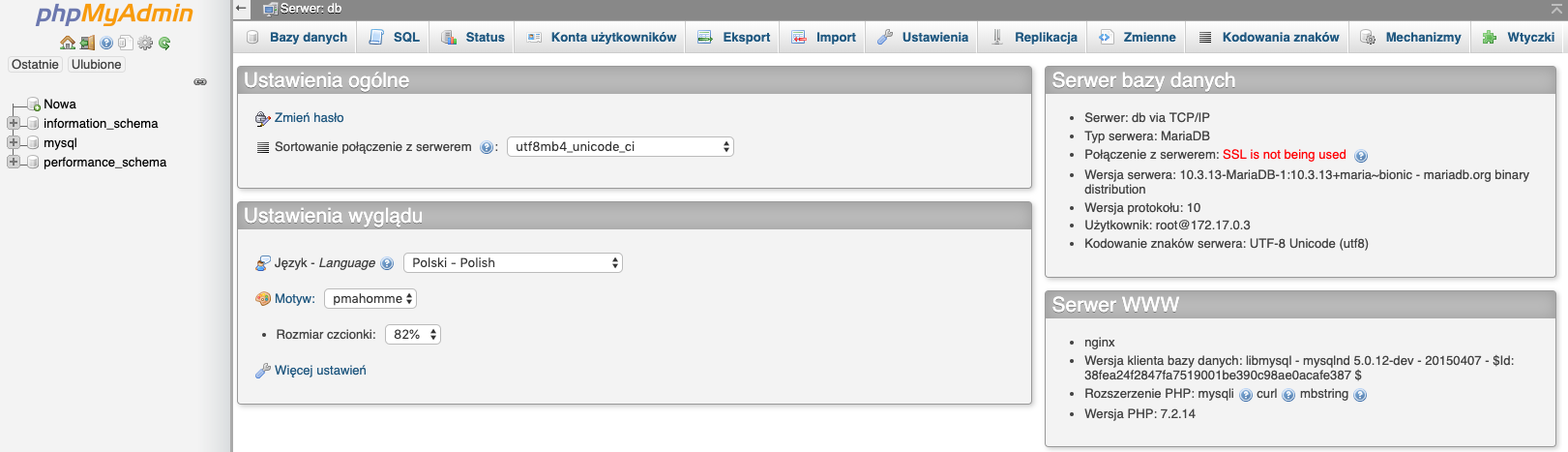
Zarządzanie bazami danych
Serwer bazodanowy może przechowywać wiele baz danych z różnymi uprawnieniami i ustawieniami. Większość klientów stara się pokryć wszystkie możliwości jakie dostarcza dany serwer. Dlatego oprócz operacji dodawania, edycji czy usuwania baz danych możemy także ustawiać ich parametry.
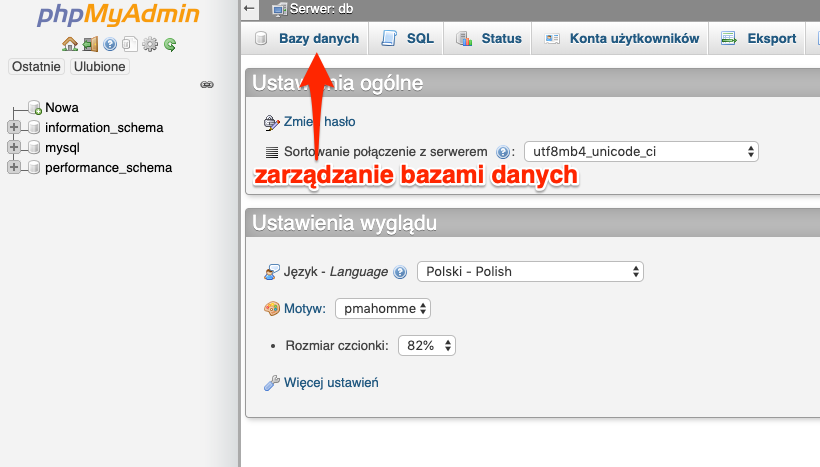
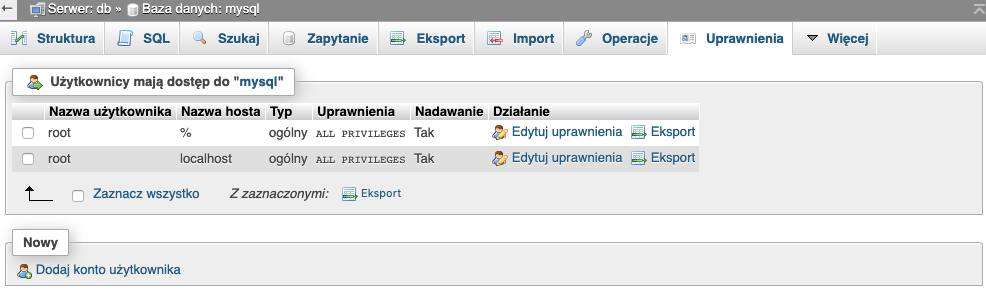
W zakładce znajdziemy listę baz danych oraz możliwość ich edycji, usunięcia oraz założenia nowej bazy.
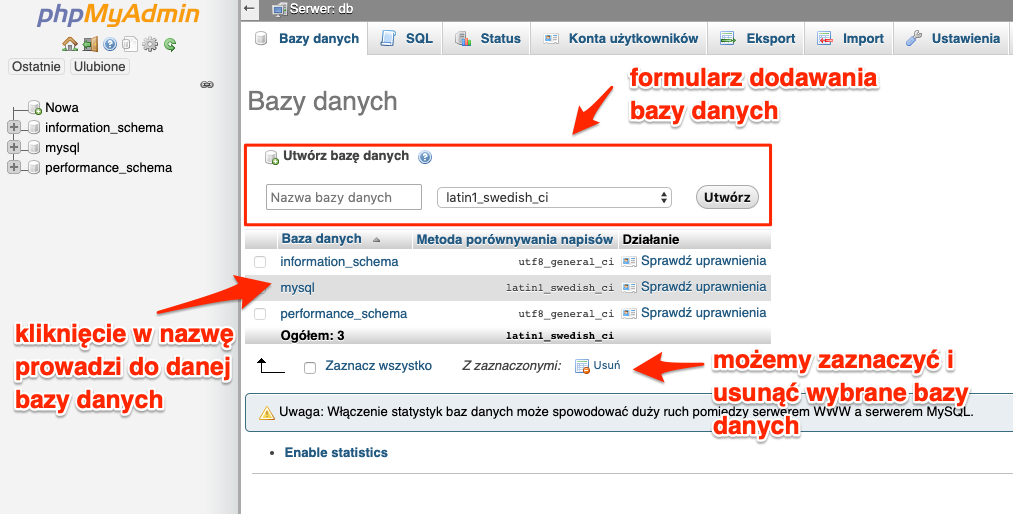
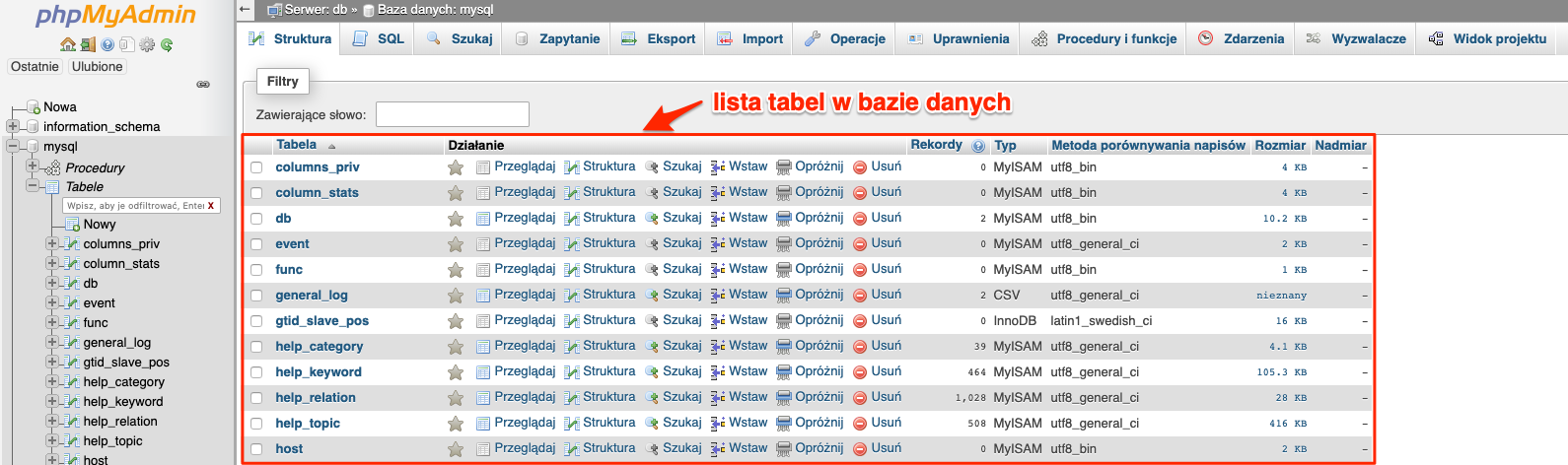
Po przejściu do wybranej bazy danych, widzimy od razu listę tabel w niej zawartych. Jednak nas bardziej w tym momencie interesują zakładki znajdujące się na samej górze.
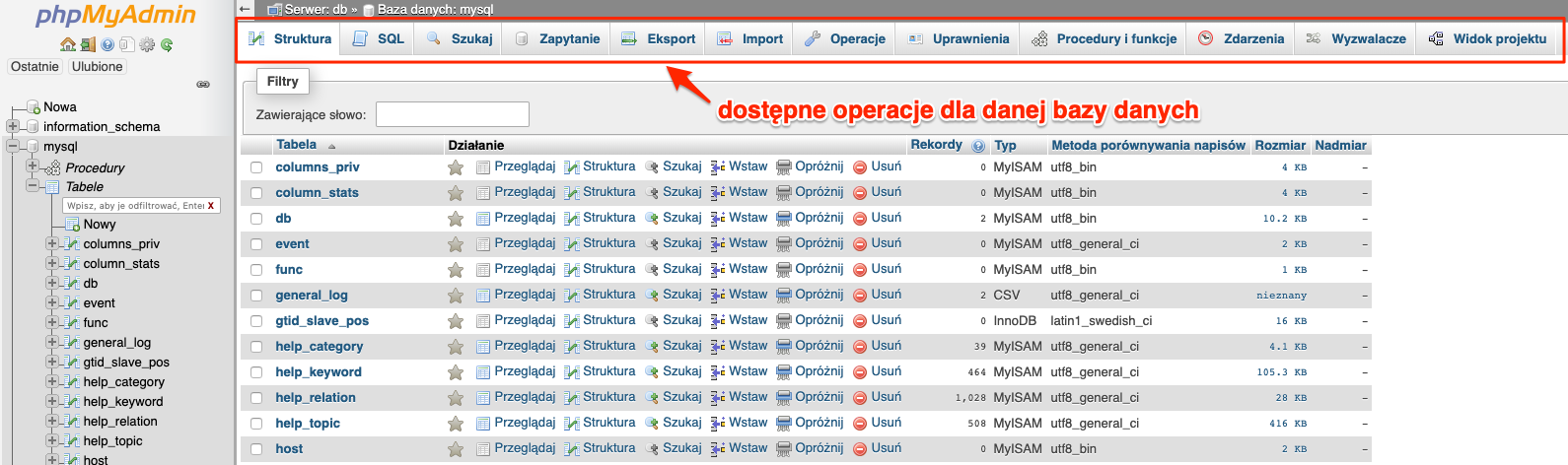
Najbardziej interesują nas zakładki Import, Eksport, Operacje oraz Uprawnienia. Pozostałe omówimy sobie przy omawianiu określonych zagadnień.
Eksport, dzięki tej zakładce możemy wyeksportować całą bazę. Lub tylko wybrane jej elementy.
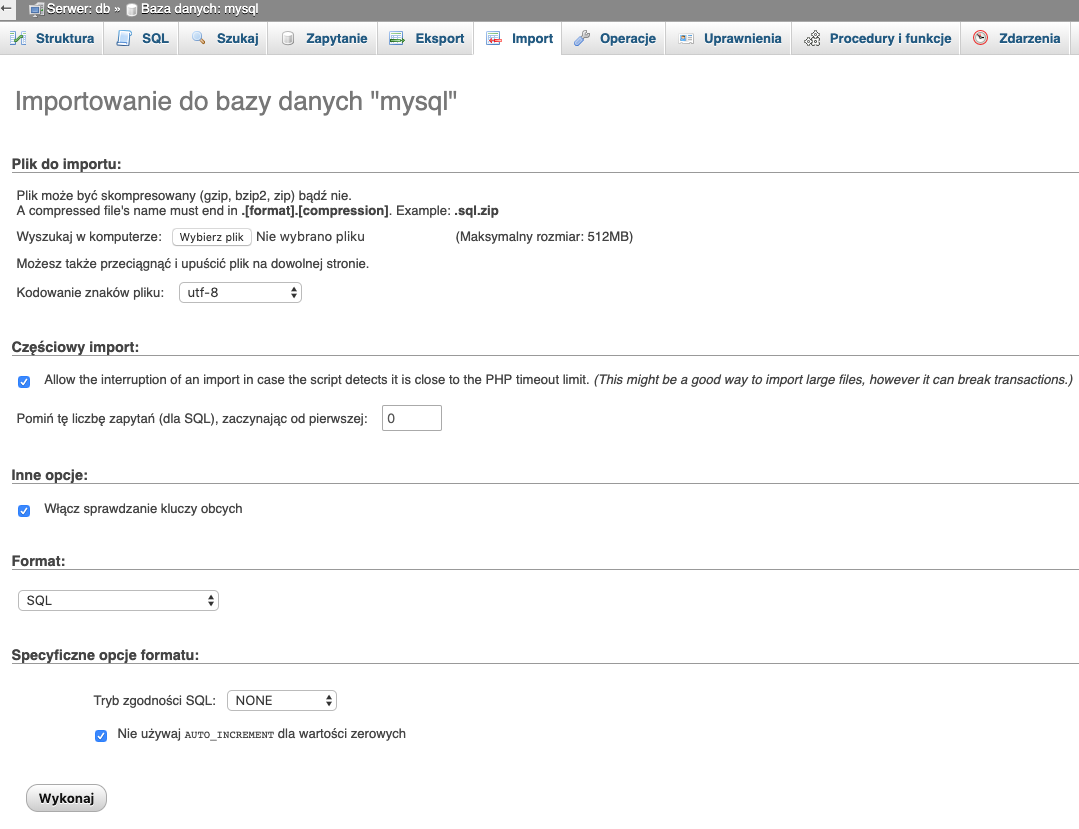
Import, pozwala nam zaimportować do bazy danych tabele, dane czy inne elementy.
Operacje, gdzie możemy zmienić nazwę czy kodowanie naszej bazy danych.
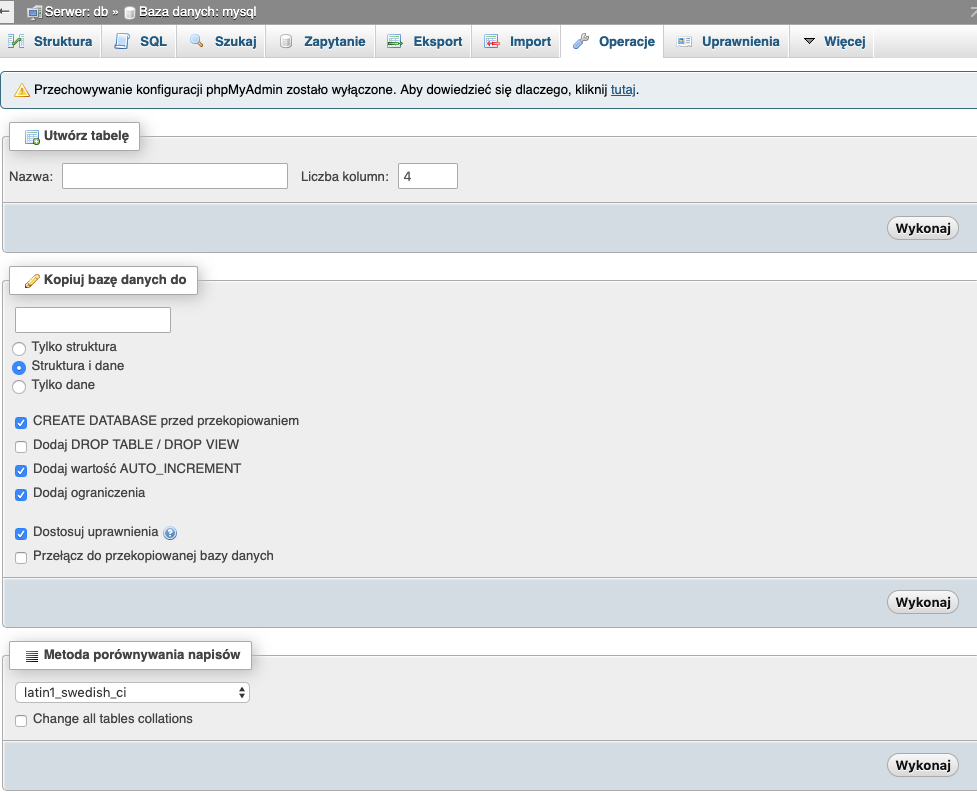
Uprawnienia, gdzie możemy zobaczyć listę użytkowników i uprawnień. A także dodać użytkownika z określonymi uprawnieniami do bazy.
Zarządzanie tabelami
Po przejściu do bazy danych otrzymaliśmy listę tabel znajdujących się w niej.
Na tych tabelach możemy wykonywać różne operacje. Od przeglądania ich zawartości czy struktury, przez usuwanie całej zawartości na usuwaniu tabel kończąc.
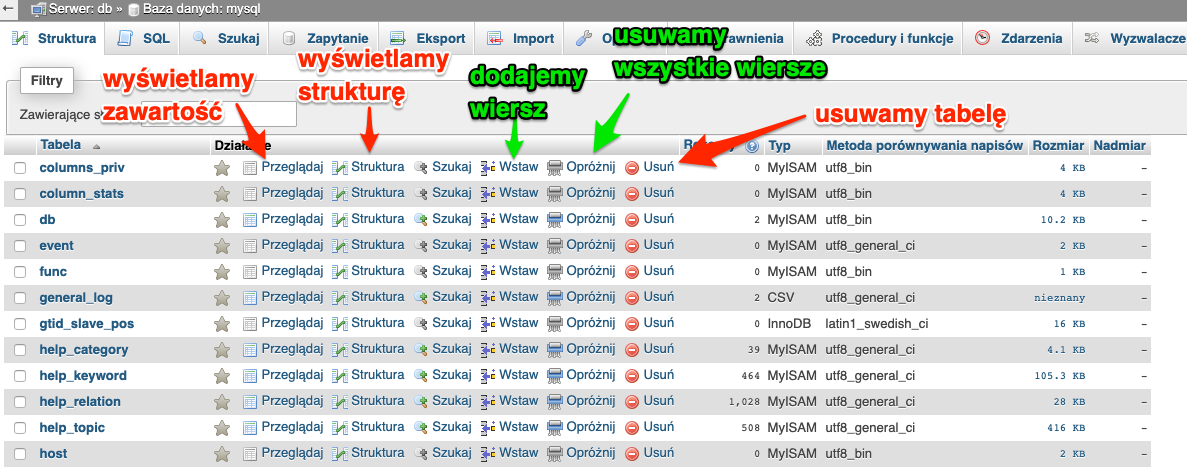
Oczywiście jest także udostępniony prosty sposób tworzenia nowej tabeli.

Wystarczy podać nazwę oraz ilość kolumn jaką planujemy dodać. Przy czym ilość tę zawszę możemy dodać lub zmniejszyć podczas dodawania. Kiedy klikniemy Wykonaj zostaniemy przeniesieni do kolejnego kroku.
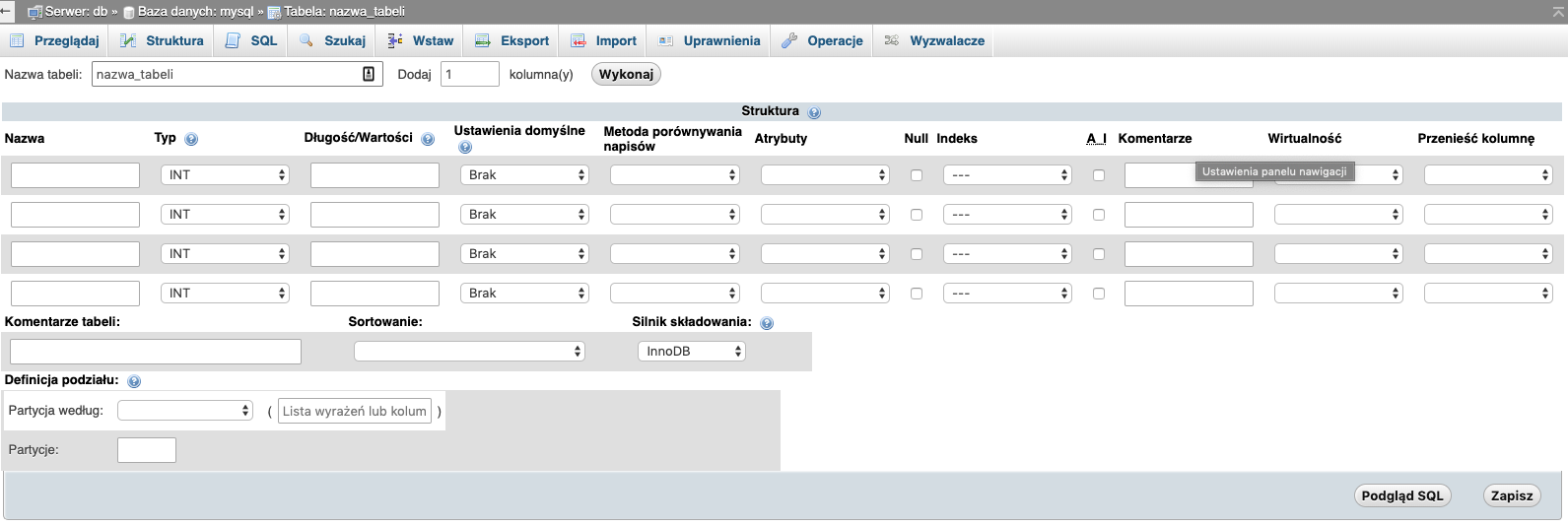
W kroku tym definiujemy kolumny danej tabeli. A kiedy skończymy klikamy przycisk Zapisz, co spowoduje utworzenie nowej tabeli.
Zarządzanie danymi
Jak już widzieliśmy po przejściu do bazy danych mamy listę tabel. Na liście tej jest możliwość przejścia do podglądu danych w danej tabeli. Ale nie jest to jedyny sposób.
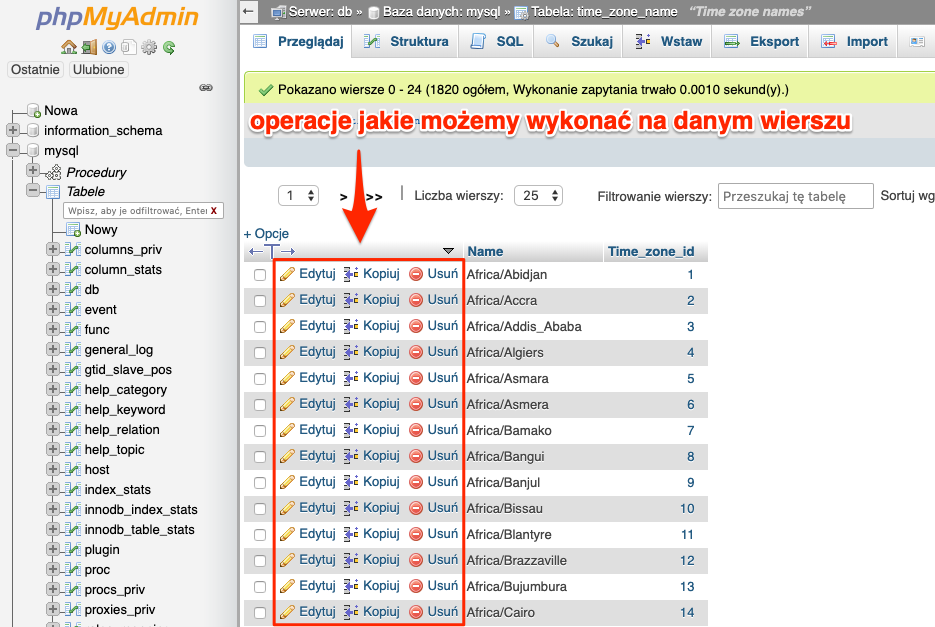
Niezależnie od wybranego sposobu przejścia do tabeli zostanie nam wyświetlona lista wierszy.
Przy każdym wierszu znajdziemy dostępne operacje jakie możemy wykonać na nim.
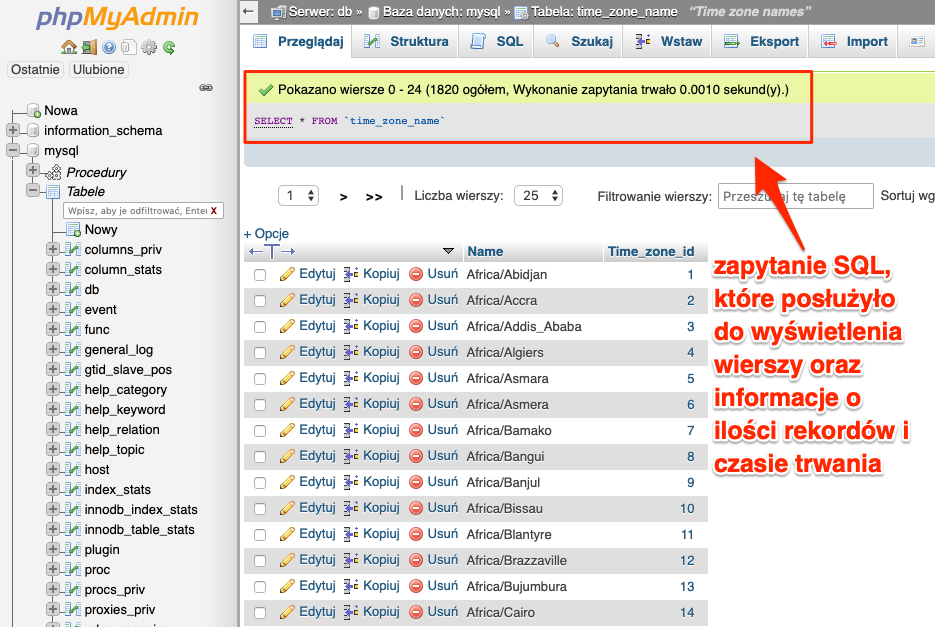
Dodatkowo nad listą znajdziemy zapytanie SQL, które zostało użyte do wyświetlenia danej listy. Poza samym zapytaniem dostajemy także informację o łącznej ilości rekordów i czasie wykonania samego zapytania.
Do pełni szczęścia brakuje nam tylko możliwości dodawania nowych wierszy. Możliwość tą znajdziemy w górnym pasku zakładek pod nazwą Wstaw.
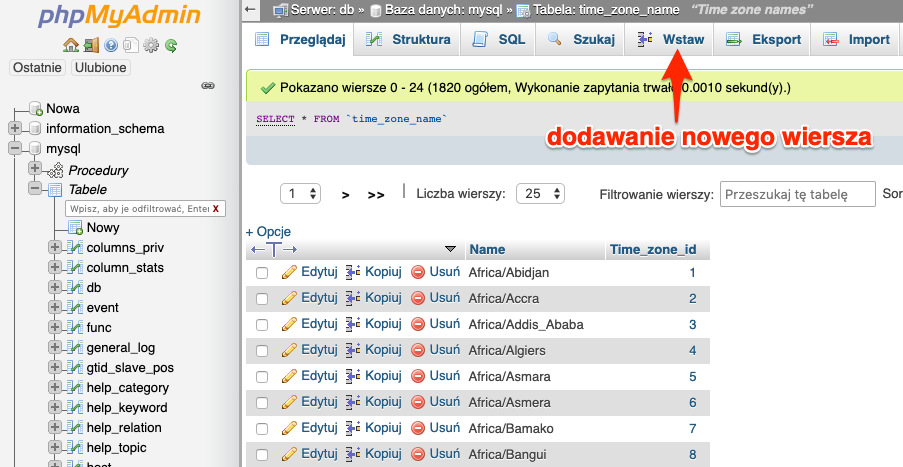
Po kliknięciu naszym oczą ukaże się na pierwszy rzut oka skomplikowany formularz. Jednak po chwili nie powinien być on już taki straszny.
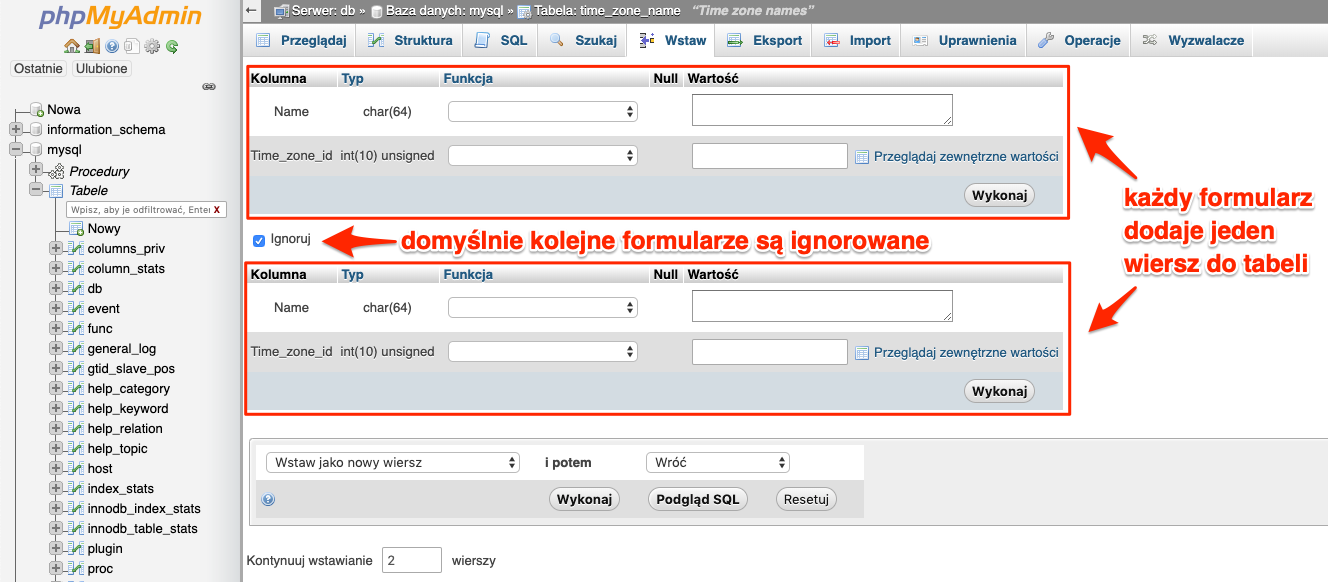
Po wypełnieniu wszystkich wymaganych pól potwierdzamy zapis klikając Wykonaj. A nowy wiersz powinien zostać dodany do tabeli.
Podsumowanie pracy z klientem GUI
Przedstawione powyżej przykłady nie muszą się w stu procentach pokrywać z innymi rozwiązaniami tego typu. Jednak chodziło tutaj o oddanie idei, którą mam nadzieję udało się dostrzec.
Do stworzenia czy zarządzania bazą danych nie potrzebujemy napisać ani jednej linijki SQL-a.
Czy to dobrze ? Odpowiedź jak zawsze jest prosta: “To zależy”. Jeśli potrzebujemy na szybko przepiąć relację, zmodyfikować dane trudno dostępne z poziomu interfejsu jakiejś aplikacji, to jest to świetne rozwiązanie. Jednak tworzenie i zarządzanie bazą, tylko z poziomu takiego klienta. Może odbić się negatywnie na działaniu aplikacji, zwłaszcza gdy używamy ORM-a (ang. Object-Relational Mapping).
Konsola
Alternatywą dla klientów posiadających GUI, są aplikacje klienckie dostępne z poziomu konsoli. Większość silników bazodanowych dostarcza takiego klienta i my właśnie takim się posłużymy.
Zanim jednak przejdziemy do wykorzystania klienta konsolowego. Musimy pamiętać, że nasz serwer bazodanowy znajduje się w kontenerze. Także w kontenerze mamy aplikację kliencką, w związku z czym musimy zalogować się do kontenera.
docker exec -it 4t-mariadb /bin/bash
Po zalogowaniu możemy uruchomić klienta konsolowego naszego silnika bazodanowego. W przypadku silnika MySQL i MariaDB klienta uruchamiamy poleceniem mysql.
mysql -u root -p
Flaga -u oznacza tutaj użytkownika na którego chcemy się zalogować. Jako że mamy użytkownika root to podaliśmy jego nazwę. Flaga -p oznacza że użytkownik ma zdefiniowane hasło i chcemy je podać przy logowaniu. W odpowiedzi na taką komendę powinniśmy otrzymać zapytanie o hasło.
Po podaniu hasła qwerty powinniśmy zostać zalogowani, a następnie powinien zostać nam wyświetlony ekran powitalny.
Teraz możemy rozpocząć pracę z bazą danych. Jednak, aby to zrobić konieczna jest znajomość SQL-a. I tego już nie przeskoczymy, bez jego znajomości możemy jedynie się wylogować wpisując polecenie exit.
Jednak żebyście mieli świadomość jak wygląda praca z konsolą poniżej znajdziecie screeny z konsoli.
Lista baz danych dostępnych na serwerze.
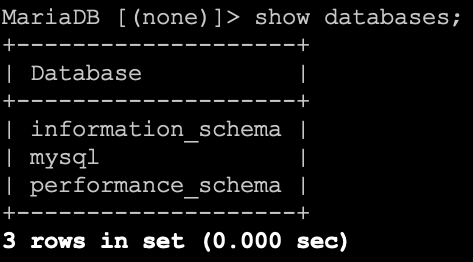
Kiedy chcemy się przełączyć na daną bazę danych informacja o tym na jakiej bazie pracujemy pokazuje się w wierszu wpisywania zapytania.

Widok listy tabel w bazie mysql jest niemal identyczny jak listy baz danych.
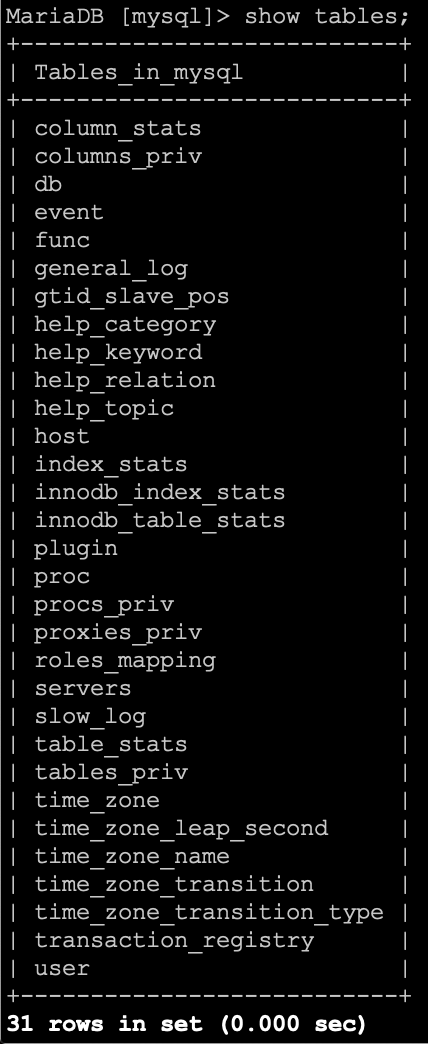
I dokładnie taki sam widok będzie, gdy wyświetlimy zawartość tabeli.
W tym momencie zapytania, które znajdują się na zrzutach z konsoli nie mają żadnego znaczenia. Więc nimi się nie przejmujcie ;) Ważne jest to, że korzystać z konsoli raczej nie będziecie, chyba że sytuacja was do tego zmusi. Warto wiedzieć, że zawsze jest dostępne takie rozwiązanie i konieczna jest tutaj znajomość SQL-a. Bo nie możecie liczyć na podpowiadanie składni czy inne rzeczy ułatwiające życie.
Baza danych
Baza danych jest to struktura odpowiedzialna za przechowywanie tabel. Jeśli miałbym to do czegoś porównywać to byłby plik Excel-a. W pliku takim znajdziemy arkusze, które będą odpowiednikami tabel w bazie danych. Zaś w arkuszach znajdują się wiersze, czyli tak samo jak w tabelach bazodanowych.
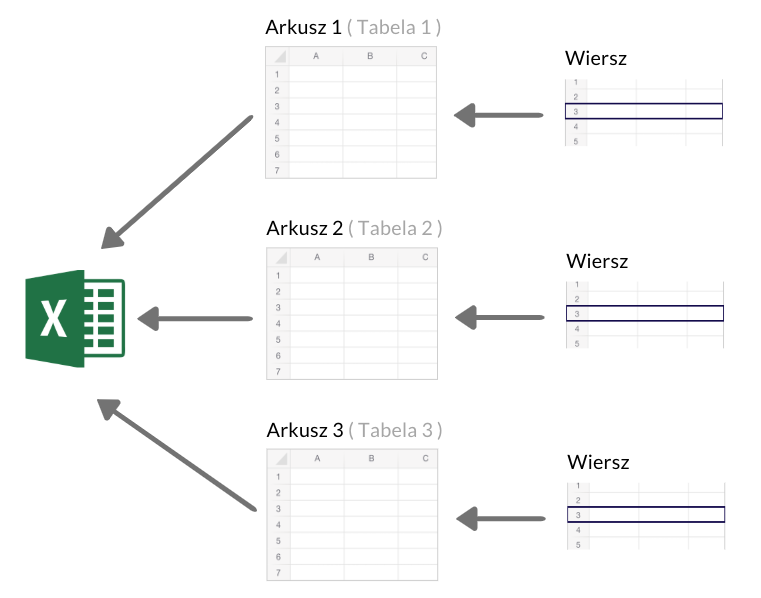
Oczywiście jest to pewne uproszczenie mające na celu zobrazowanie struktur znajdujących się na serwerze baz danych.
Tworzenie nowej bazy danych
Przygodę z SQL-em zaczniemy od operacji dotyczących bazy danych. Są to operacje które wykonuje się dość rzadko, a w przypadku, gdy serwer bazodanowy znajduje się na jakimś hostingu. To z reguły bazę tworzymy z poziomu panelu administracyjnego. W naszym przypadku mamy pełen dostęp do serwera i możemy go obsługiwać z poziomu konsoli lub phpMyAdmin-a. Dlatego możemy pobawić się z operacjami na bazie danych.
Zanim wykonamy pierwsze polecenie musimy wiedzieć, że każde polecenie ma elementy wymagane oraz opcjonalne. Co w odpowiedni sposób zapisuje się w schemacie polecenia SQL.
Poniżej przykładowy zapis polecenia tworzącego bazę danych z dokumentacji.
CREATE [OR REPLACE] {DATABASE | SCHEMA} [IF NOT EXISTS] db_name
[create_specification] ...
create_specification:
[DEFAULT] CHARACTER SET [=] charset_name |
[DEFAULT] COLLATE [=] collation_name
Na początku może nieco przerażać, jednak nie martw się, powoli wszystko sobie wyjaśnimy. Zacznijmy od samego końca, czyli create_specification ujętego w nawiasy kwadratowe. Element ten możemy zastąpić strukturą znajdującą się poniżej samego zapytania.

Zabieg ten ma na celu ułatwić nam czytanie bardziej złożonych konstrukcji SQL. Rozwiązanie to nie musi być wspólne dla wszystkich dokumentacji, jednak można się z nim spotkać dość często.
Kolejny ważny element to zapisywanie niektórych konstrukcji w nawiasach kwadratowych []. Oznacza to, że elementy te są opcjonalne.
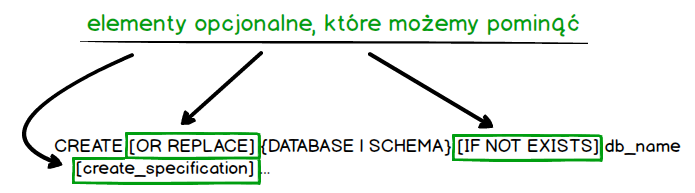
Czyli jeśli je wyrzucimy to polecenie dalej zadziała. Zobaczmy jak będzie wyglądała uproszczona wersja.
CREATE {DATABASE | SCHEMA} db_name
Dużo prościej prawda ;) Kolejne nawiasy klamrowe {} oznaczają, że musimy wybrać z nich jeden element.
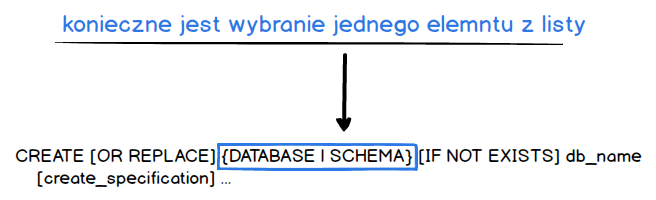
Jako że my chcemy utworzyć bazę danych to wybieramy DATABASE i nasze zapytanie będzie wyglądało następująco.
CREATE DATABASE db_name
Teraz wystarczy zastąpić db_name nazwą naszej bazy danych i wykonać polecenie np. w zakładce SQL phpMyAdmin-a. Moje polecenie będzie wyglądało następująco.
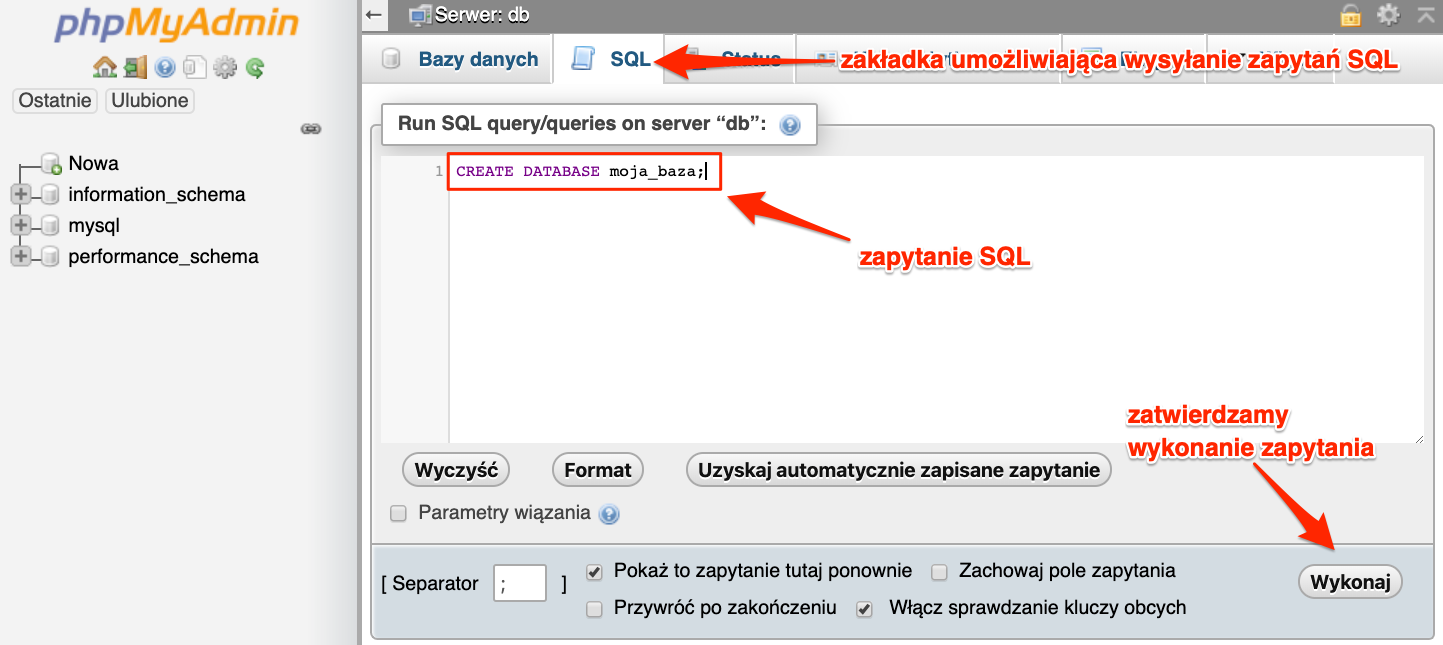
I w rezultacie zostanie utworzona baza danych.
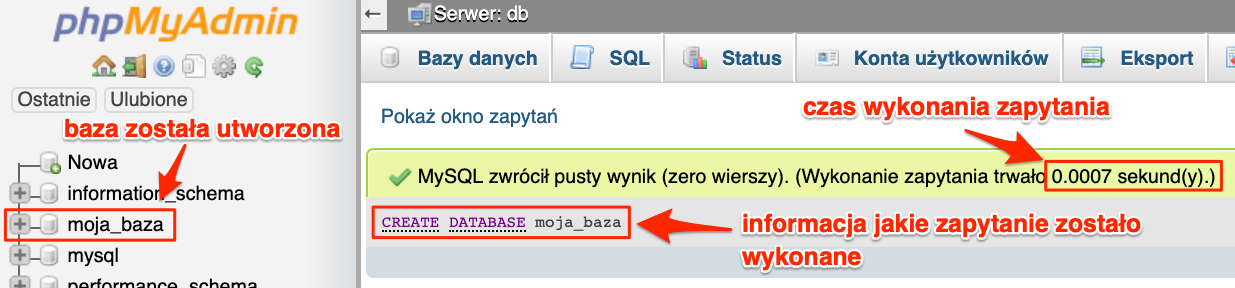
A dla lubiących konsolę, po wykonaniu polecenia zobaczymy poniższy rezultat.
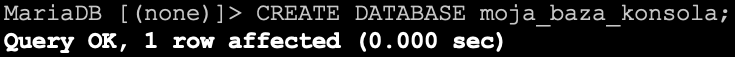
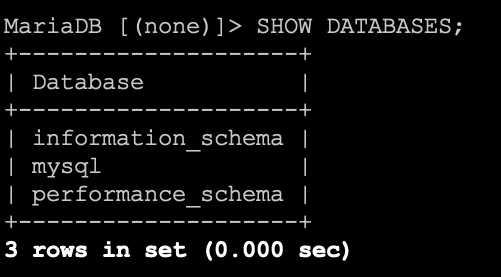
Z poziomu phpMyAdmin-a od razu widać, że dana baza danych została utworzona, gdyż mamy do niej dostęp z panelu znajdującego się z lewej strony. W przypadku konsoli nie mamy widocznej pełnej listy baz danych, ale zawsze możemy posłużyć się prostym zapytaniem listującym wszystkie dostępne bazy danych.
SHOW DATABASES;
Rezultat działania zapytania będzie następujący.
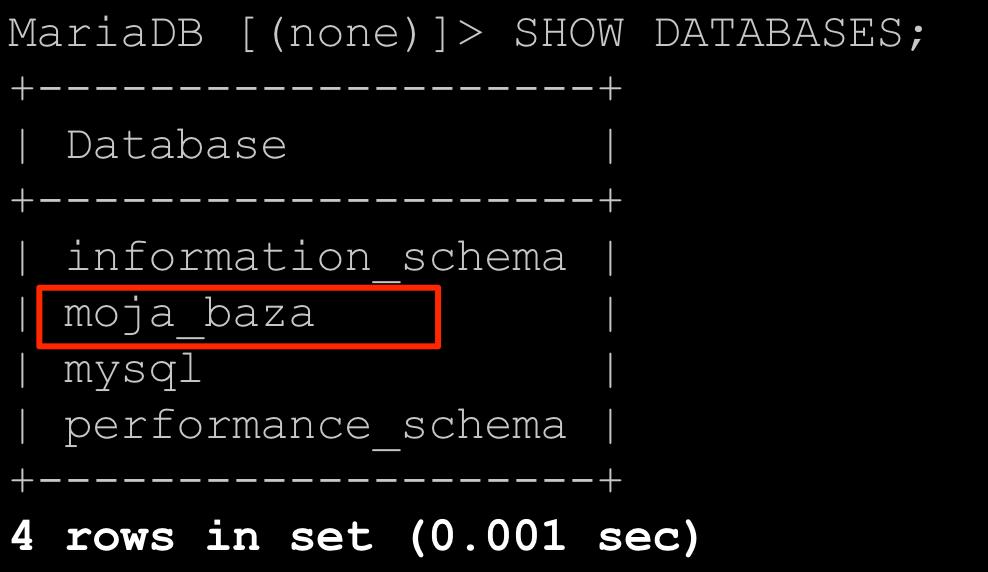
Zapytanie to jest o tyle przydatne, że gdybym próbowali utworzyć nową bazę podając nazwę bazy, która już istnieje to w rezultacie otrzymamy błąd. Na potrzeby tego przykładu możemy ponownie wywołać polecenie, którym przed chwilą tworzyliśmy bazę danych. U mnie będzie to poniższe polecenie.
CREATE DATABASE moja_baza;
W rezultacie dostajemy błąd.
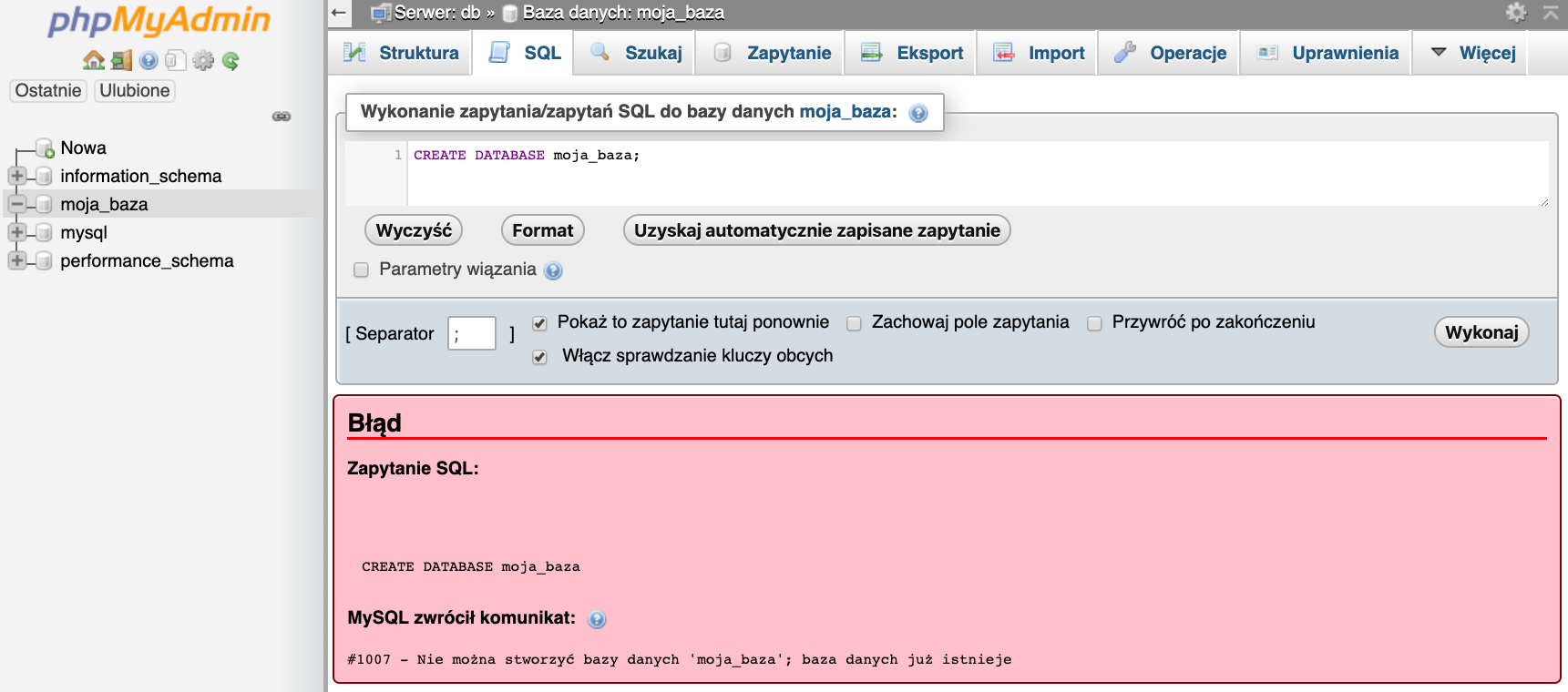
Dla analogicznego zapytania w konsoli otrzymamy taki sam błąd. Z tą różnicą, że nie wygląda tak dobrze ;)
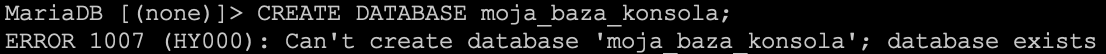
Możemy uniknąć tego błędu poprzez wykorzystanie opcjonalnej struktury IF NOT EXISTS. Mam nadzieję, że pamiętasz. Ten element był opcjonalny i z niego zrezygnowaliśmy na początku. Teraz dodamy go do zapytania.
CREATE DATABASE IF NOT EXISTS moja_baza;
Przy tak skonstruowanym zapytaniu, błąd się nie pojawia.
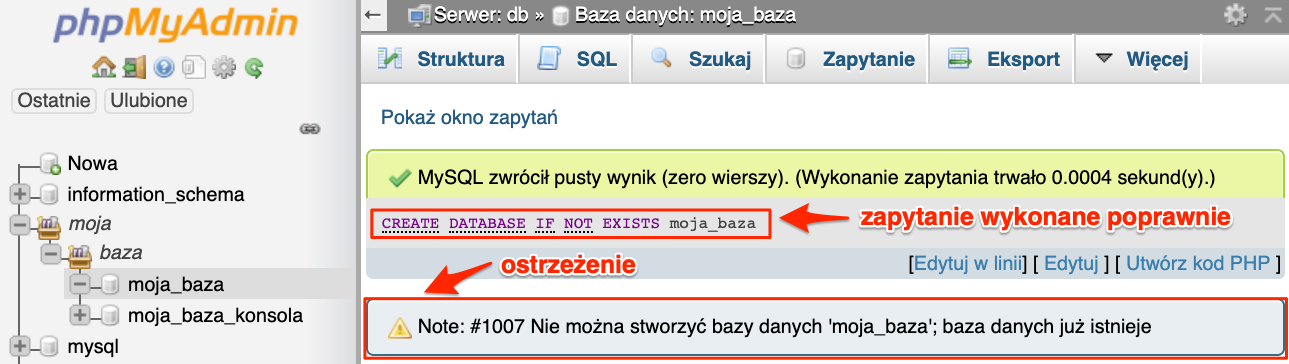
Pomimo że tym razem nie mamy błędu to phpMyAdmin wyświetlił informację, że baza nie została utworzona. Zobaczmy jak zachowa się konsola.

Konsola jest jak zwykle oszczędniejsza w komunikatach, ale wyświetla bardzo ważną rzecz. Jest to ostrzeżenie (ang. warning), niestety nie mówi od razu o czym mówi dane ostrzeżenie. Do wyświetlania ostrzeżeń mamy odpowiednie zapytanie.
SHOW WARNINGS;
W rezultacie otrzymamy informację o ostrzeżeniach jakie zostały odnotowane.

Na bazie tych informacji jesteśmy w stanie stwierdzić czy my utworzyliśmy bazę, czy ona już tam się znajdowała.
W phpMyAdmin wywoływanie zapytania SHOW WARNINGS nie spowoduje wyświetlenie listy ostrzeżeń. Wynika to z faktu, że phpMyAdmin sam o to pyta, aby wyświetlić nam odpowiedni komunikat w interfejsie.
Usuwanie bazy danych
Skoro mamy już utworzoną bazę danych to czas ją skasować 😉 Pełna struktura zapytania wygląda następująco.
DROP {DATABASE | SCHEMA} [IF EXISTS] db_name
I znowu zaczynając od absolutnego minimum otrzymamy zapytanie.
DROP DATABASE moja_baza;
Po jego wywołaniu otrzymamy informację o powodzeniu operacji.
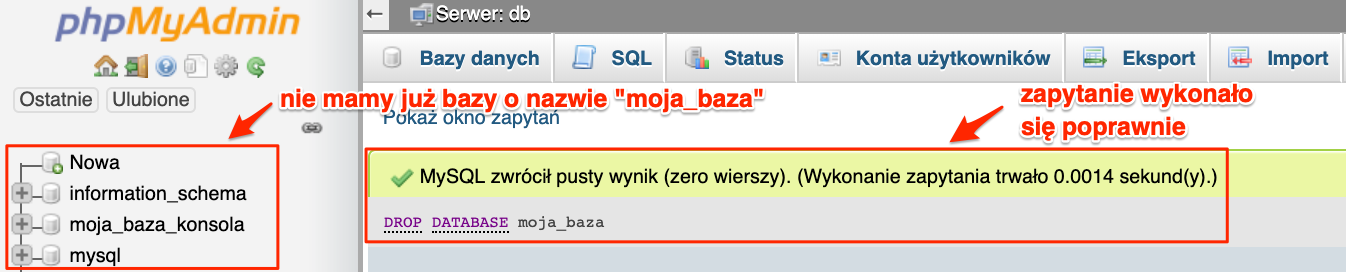
Z poziomu konsoli sytuacja będzie wyglądała analogicznie.

Jedyna różnica, że z poziomu konsoli nie widzimy od razu listy baz. Więc nie możemy naocznie tego zweryfikować, ale z pomocą przychodzi nam zapytanie listujące bazy danych.
SHOW DATABASES;
W rezultacie otrzymamy aktualną listę baz do których mamy dostęp.
I jak widać baza została usunięta, czyli zwrócony rezultat w konsoli nie kłamał. A teraz zastanówmy się chwilę, co by się stało gdybym spróbowali usunąć bazę danych, która nie istnieje ??
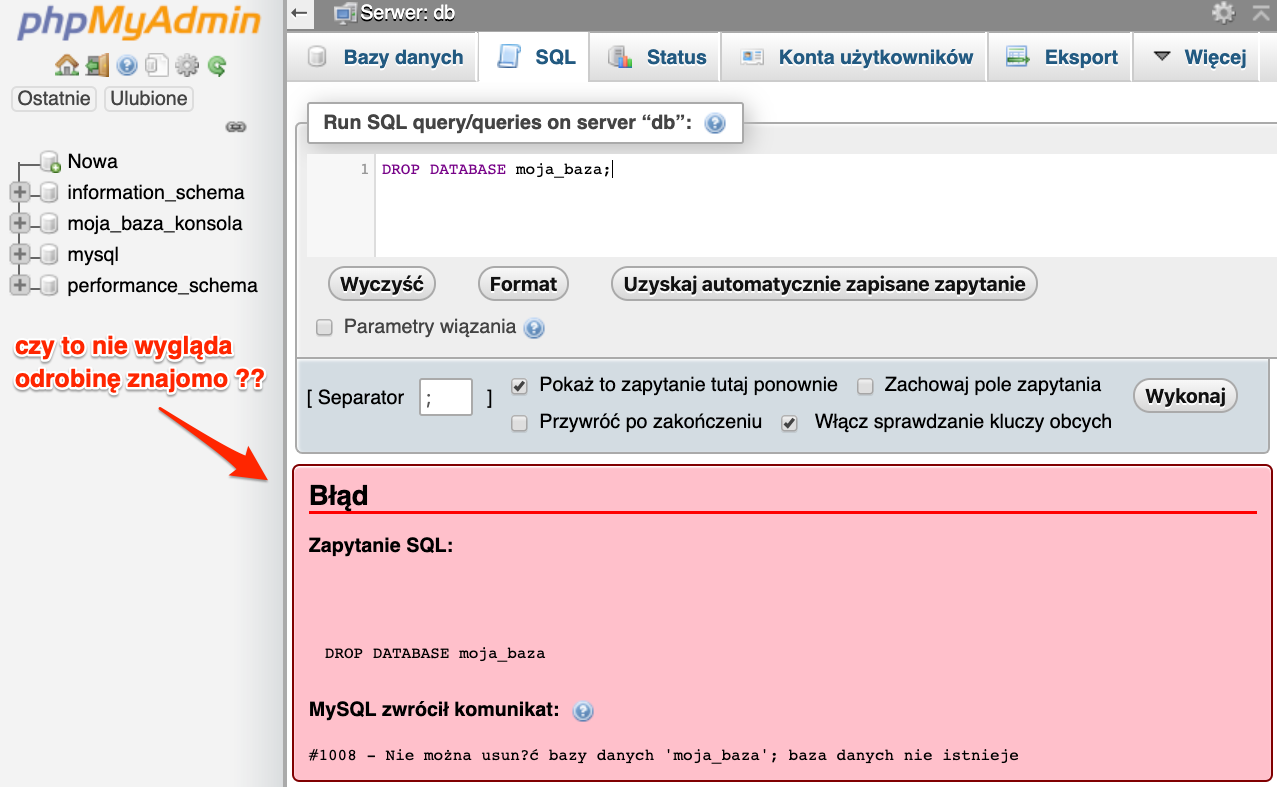

Sytuacja jest taka sama jak w przypadku tworzenia bazy danych. Otrzymujemy błąd, gdyż nie można usunąć czegoś co nie istnieje. I z pomocą przychodzi ta sama konstrukcja co poprzednio IF EXISTS.
DROP DATABASE IF EXISTS moja_baza;
W tym przypadku już nie otrzymamy błędu, a jedynie ostrzeżenie. Tak samo jak w przypadku dodawania bazy danych.
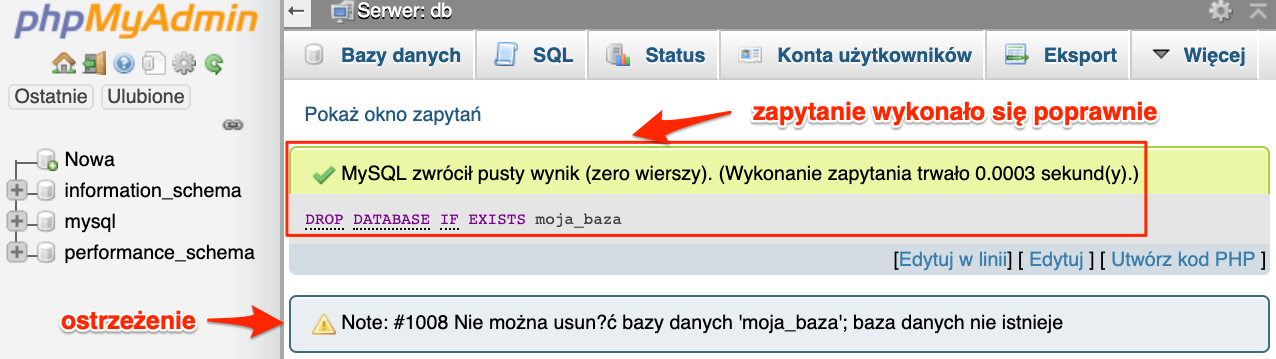
I analogiczna sytuacja z poziomu konsoli.

Oraz podgląd ostrzeżeń z poziomu konsoli.
SHOW WARNINGS;

Tabele
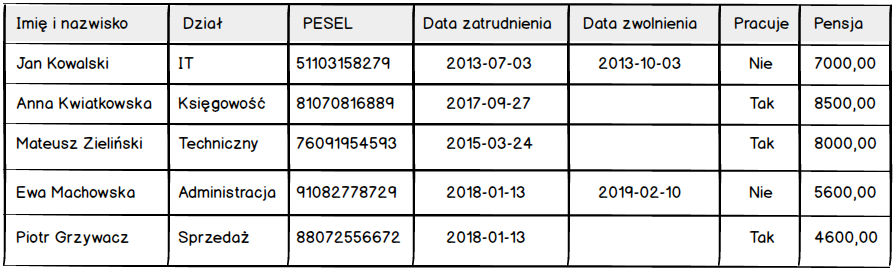
Powyższa tabela nie jest dla nikogo zaskoczeniem, każdy z nas wie jak wygląda tabela. Zbiór kolumn i wierszy. Przy czym jeśli myślimy o tabeli w kontekście bazy danych to powinniśmy myśleć jedynie o kolumnach.
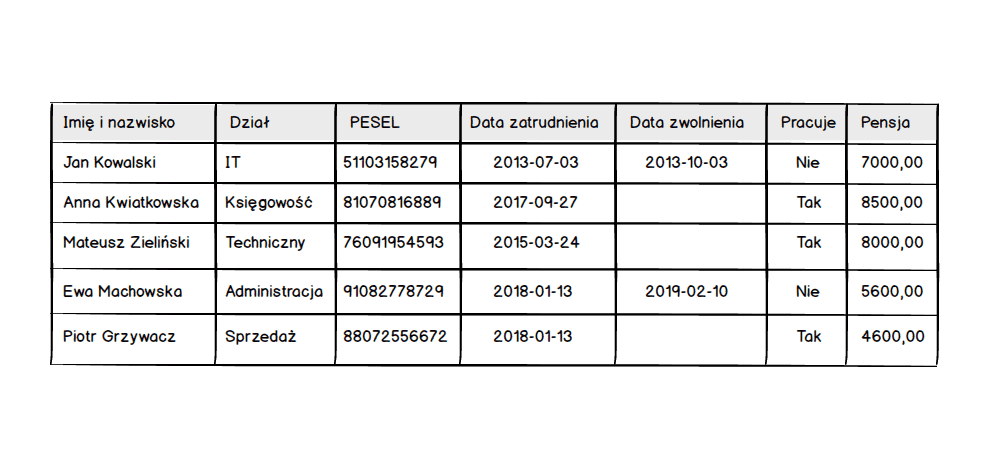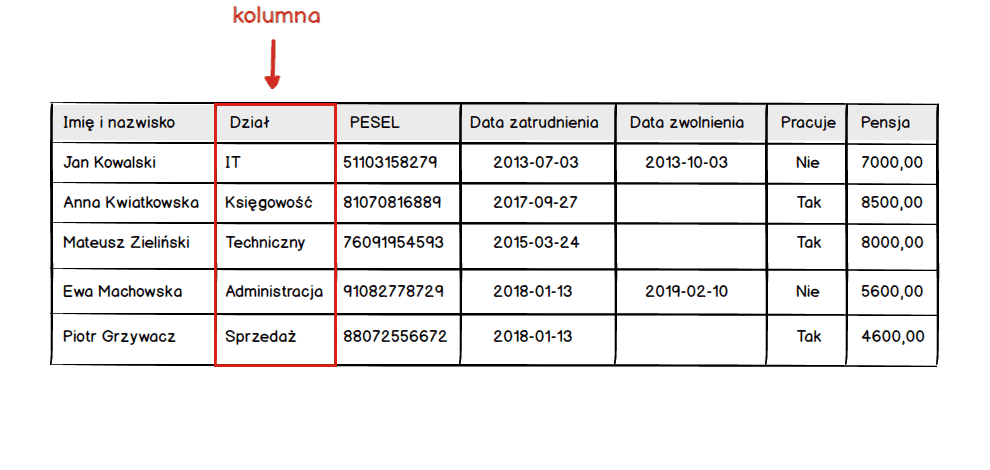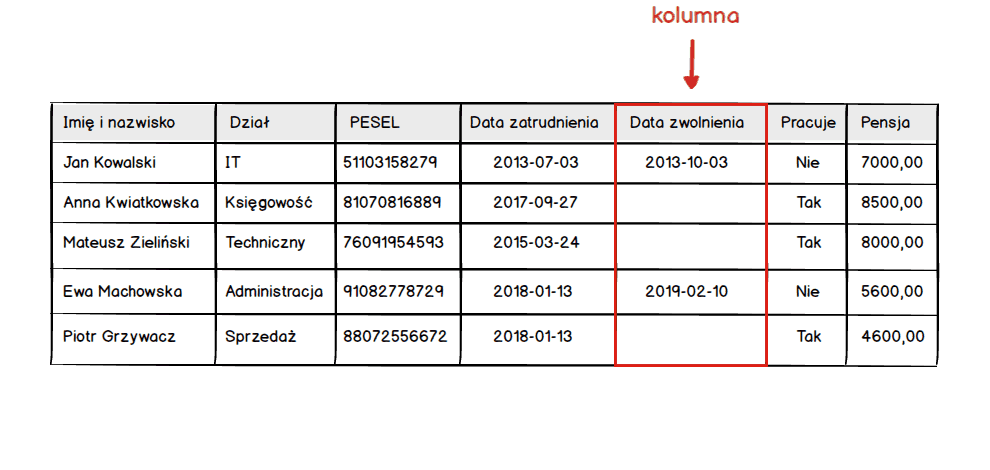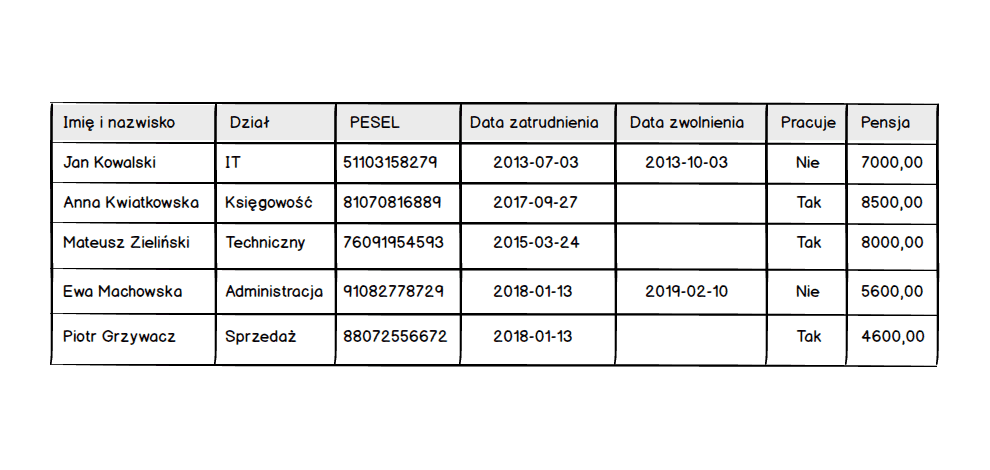
Wynika to z faktu, że tworząc tabelę definiujemy jedynie jakie kolumny mają się w niej znajdować, plus milion dodatkowych rzeczy nieistotnych na tym etapie ;) Pomimo że tworząc tabelę myślimy tylko o kolumnach to nie możemy zapominać o przyszłych danych, które w danej tabeli się znajdą. A to dlatego, że w odróżnieniu od tabeli rysowanej na kartce papieru, w arkuszu kalkulacyjnym czy edytorze tekstu musimy podać rodzaj przechowywanych danych.
Pomyślmy teraz jak opisali byśmy rodzaj danych dla poszczególnych kolumn naszej tabeli ?
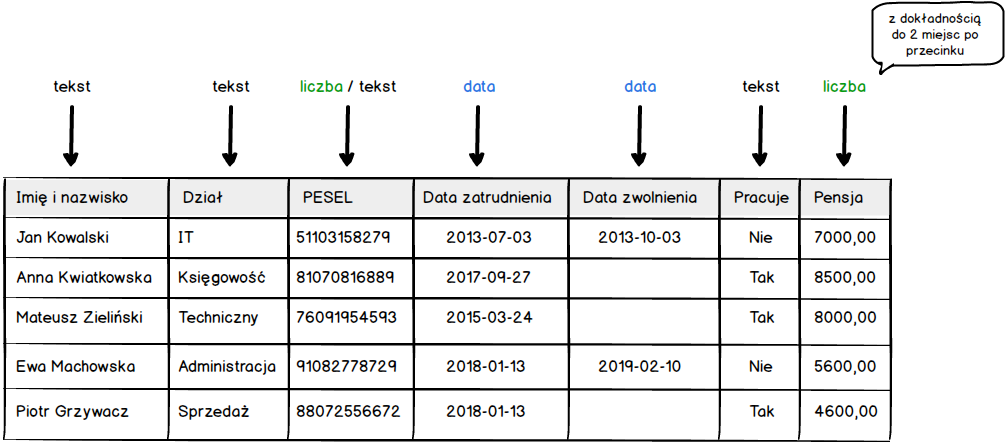
Czy tak mogło by to wyglądać ? Według mnie jest OK ;) Teraz pozostaje przełożenie tego bardzo prostego opisu rodzaju przechowywanych danych w kolumnach na odpowiednie typy danych, które zrozumie baza danych.
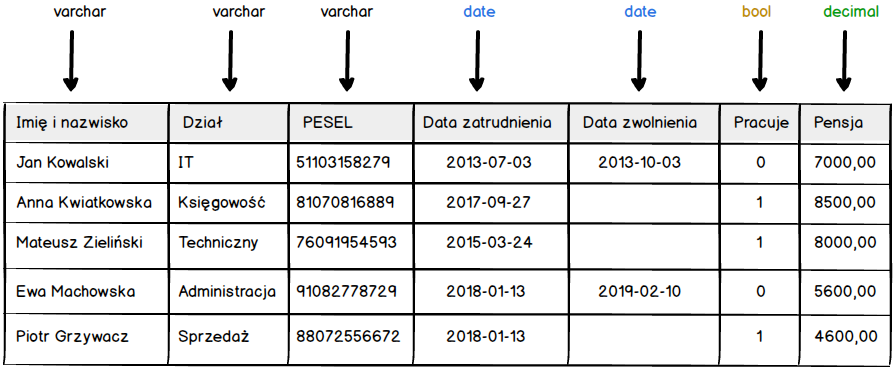
Porównując nasz pierwotny opis z przełożeniem na typy charakterystyczne dla baz danych, a tym samym języka SQL, ukaże nam się poniższy obraz.
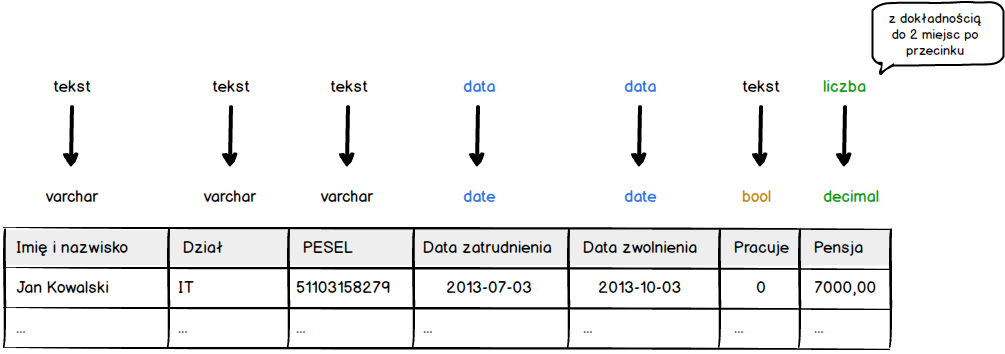
Na podstawie tego obrazu możemy dojść do prostych wniosków.
- tekst w SQL-u to typ varchar,
- data w w SQL-u to typ date,
- tekst wyrażający stan prawda / fałsz w SQL-u to typ bool,
- liczba będąca kwotą w SQL-u to typ decimal
Wnioski są jak najbardziej słuszne, jednak możliwych typów danych jest dużo więcej. W dodatku wiele z nich może przechowywać ten sam rodzaj danych. Przykładowo dane tekstowe mogą być przechowywane w typie varchar, ale także w typach: char, text, mediumtext, longtext. Dlatego warto przyjrzeć się nieco bliżej dostępnym typom danych.
Typy danych
Wiemy już że każda kolumna w tabeli musi mieć określony typ danych. Nawet poznaliśmy już kilka typów charakterystycznych dla określonych danych: tekst -> varchar, data -> date, kwota -> decimal itd. Nie są to oczywiście wszystkie typy dostępne w bazach danych. Jest ich znacznie więcej i często opisują te same dane. Weźmy na przykład tekst, który może być przechowywany w kolumnie typu varchar. Ale także może być przechowywany w kolumnach typu char, text, mediumtext, longtext. Sam wybór odpowiedniego typu jest uzależniony co dokładnie chcemy przechowywać i jak dużo pamięci chcemy na to poświęcić. Zanim zajmiemy się dokładniej tym zagadnieniem zobaczmy jakie typy danych mamy dostępne w MySQL-u.
| Dane tekstowe | char, varchar, text, mediumtext, longtext |
| Liczbowe | tinyint, smallint, mediumint, int, bigint, float, double, decimal |
| Data i czas | date, datetime, timestamp, time, year |
| Binarne | tinyblob, blob, mediumblob, longblob |
| Specjalne | enum, set |
Powyższa lista została stworzona dla bazy MySQL, ale większość typów znajdziemy także w innych silnikach bazodanowych. Więc na tym etapie nie musimy się tym przejmować. Ważniejszym aspektem jest wybór samego typu dla naszej kolumny.
Niestety wiele osób pracujących z bazami danych nie przejmuje się wybieranymi typami danych. Wiąże się to głównie z dużymi mocami serwerów oraz niemal nieograniczoną powierzchnią na dyskach tychże serwerach. Bo to co powinniście wiedzieć o typach to to, że każdy z nich zajmuje określoną ilość miejsca na dysku serwera. I każdy z nich w związku z tym ma pewne ograniczenia.
Dane tekstowe
Przyjrzyjmy się naszemu ulubionemu typowi danych, czyli tekstowi. Możemy przechowywać go na wiele sposobów. Każdy z dostępnych typów różni się ilością użytej pamięci oraz maksymalną długością przechowywanego tekstu.
| Typ | Rozmiar | Długość tekstu |
| CHAR(dł.) | określamy w nawiasie | od 0 do 255 bajtów |
| VARCHAR(dł.) | długość 1 bajt (dla tekstu do 255 bajtów), długość 2 bajty (dla tekstów powyżej 255 bajtów) | od 0 do 65 535 bajtów |
| TEXT | długość 2 bajty | od 0 do 65 535 bajtów |
| MEDIUMTEXT | długość 3 bajty | od 0 do 16 777 215 bajtów |
| LONGTEXT | długość 4 bajty | od 0 do 4 294 967 295 bajtów |
CHAR – typ ten jest dość specyficzny z dwóch powodów. Pierwszy powód to fakt że definiujemy dokładnie ile bajtów będzie zajmował. I nie ma tutaj żadnego odstępstwa, jeśli dany rekord nie będzie zawierał żadnego tekstu w kolumnie tego typu to i tak zostanie zajęta zdefiniowane ilość bajtów. Drugim powodem wyjątkowości tego typu jest dodawanie treści do naszych danych. A dokładniej chodzi o ich uzupełnianie spacjami w przypadku braku odpowiedniej ilości znaków (bajtów).
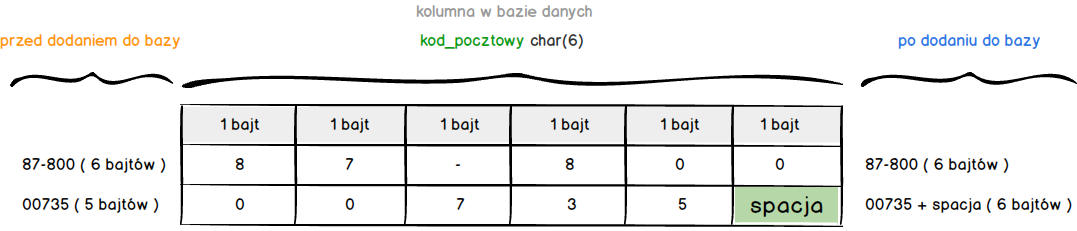
VARCHAR typ ten w odróżnieniu od poprzednio omawianego nie na stałej długości. Naszym zadaniem jest podanie maksymalnej ilość bajtów jakie kolumna może przechowywać. Przy czym nie możemy przekroczyć 65 535 bajtów. I dalej za nas pracuje już silnik bazy danych, który sam określa ilość bajtów i dodaje 1 bajt jeśli długość jest mniejsza 256 bajtów lub dwa gdy ta wartość została przekroczona. Dzięki takiemu podejściu typ ten jest bardzo często stosowany.
Typy TEXT, MEDIUMTEXT oraz LONGTEXT nie wymagają od nas podawania żadnych informacji. I działają analogicznie jak typ VARCHAR przy odpowiednio większej ilości danych jakie mogą przechowywać. Co naturalnie wiąże się z większym zapotrzebowaniem na pamięć.
Wiemy już jak się ma sprawa z typami tekstowymi. Wiedza ta wystarczy, aby zrozumieć analogię w przypadku pozostałych typów danych. Liczby całkowite różnią się zakresem, podobnie zmiennoprzecinkowe. W przypadku daty i czasu nie mamy różnic w zakresie, ale czym dokładniejsze informacje chcemy przechowywać tym więcej bajtów potrzebujemy.
Liczbowe
| Typ | Rozmiar | Opis |
| TINYINT | 1 bajt | od -128 do 127, lub od 0 do 255 |
| SMALLINT | 2 bajty | od -32 768 do 32 767, lub od 0 do 65 535 |
| MEDIUMINT | 3 bajty | -8 388 608 do 8 388 607, lub od 0 do 16 777 215 |
| INT | 4 bajty | –2 147 483 648 do 2 147 483 647, lub od 0 do 4 294 967 295 |
| BIGINT | 8 bajtów | -9 223 372 036 854 775 808 do 9 223 372 036 854 775 807, lub od 0 do 18 446 744 073 709 551 615 |
| FLOAT | 4 bajty | liczba zmiennoprzecinkowa z zakresu od -3.402823466E 38 do -1.175494351E-38, 0, i 1.175494351E-38 do 3.402823466E 38 |
| DOUBLE | 8 bajty | liczba zmiennoprzecinkowa z zakresu od -1.7976931348623157E 308 do -2.2250738585072014E-308, 0, i 2.2250738585072014E-308 do 1.7976931348623157E 308 |
| DECIMAL | długość 1 bajt lub 2 bajty | Zakres taki sam jak DOUBLE. Liczba jest przechowywana w formacie znakowym z możliwością określenia ilości miejsc po przecinku. |
Data i czas
Typ | Rozmiar | Opis DATE | 3 bajty | Data w formacie RRRR-MM-DD DATETIME | 8 bajtów | Data i czas w formacie RRRR-MM-DD HH:MM:SS TIMESTAMP | 4 bajty | Data i czas liczony od 1970-01-01 00:00:00 czyli epoki systemu UNIX do roku 2037 TIME | 3 bajty | czas w formacie HH:MM:SS YEAR | 1 bajt | zakres od 1901 do 2155
Znajomość powyższych typów powinna być wystarczająca na początku przygody z SQL-em i bazami danych.
Lista tabel w bazie
Zanim jeszcze przejdziemy do utworzenia pierwszej tabeli warto znać zapytanie wyświetlające listę tabel znajdujących się w bazie danych.
SHOW [EXTENDED] [FULL] TABLES
[{FROM | IN} db_name]
[LIKE 'pattern' | WHERE expr]
Na podstawie powyższego zapisu i wiedzy jak go czytać, tworzymy bardzo proste zapytanie.
SHOW TABLES;
Rezultat jest oczywisty, czyli brak jakiejkolwiek tabeli.

Skoro mamy już pewność, że w bazie danych nie mamy żadnej tabeli to czas jakąś utworzyć ;)
Tworzenie tabel
Wspominałem wcześniej, że myśląc o tabeli powinniśmy myśleć o kolumnach jakie taka tabela ma posiadać. Wynika to z konieczności zdefiniowania przynajmniej jednej kolumny podczas tworzenia tabeli.
Uproszczony zapis zapytania tworzącego tabelę wygląda następująco.
CREATE [TEMPORARY] TABLE [IF NOT EXISTS] tbl_name
(create_definition,...)
[table_options]
[partition_options]
W tym momencie odrzucimy wszystkie niewymagane elementy i pozostanie nam poniższy zapis.
CREATE TABLE tbl_name
(create_definition,...)
Jedyna niewiadoma w tym momencie to zapis (create_definition,...). A jest to odsyłanie do sekcji opisującej zasady tworzenia kolumn w tabeli. Upraszczając do maksimum schemat, który musimy znać, aby zdefiniować listę kolumn. Dostaniemy coś takiego.
create_definition:
col_name DATA_TYPE [NOT NULL | NULL]
Gdzie DATA_TYPE to typ danych jaki ma być przechowywany w danej kolumnie. Dodatkowo mamy opcjonalną możliwość określenia parametru NOT NULL lub NULL. Możemy oczywiście pominąć ten element co spowoduje ustawienie NULL dla każdej kolumny. Co w praktyce oznacza wartość nieokreśloną, a my przecież znamy wartości prawie wszystkich kolumn. Wyjątkiem jest data zwolnienia, choć i tu może być różnie ;) W praktyce staramy się nie ustawiać wartości NULL w żadnej kolumnie, a gdy to robimy to róbmy to rozważnie. Powodów jest wiele i porozmawiamy o nich sobie w osobnym wpisie.
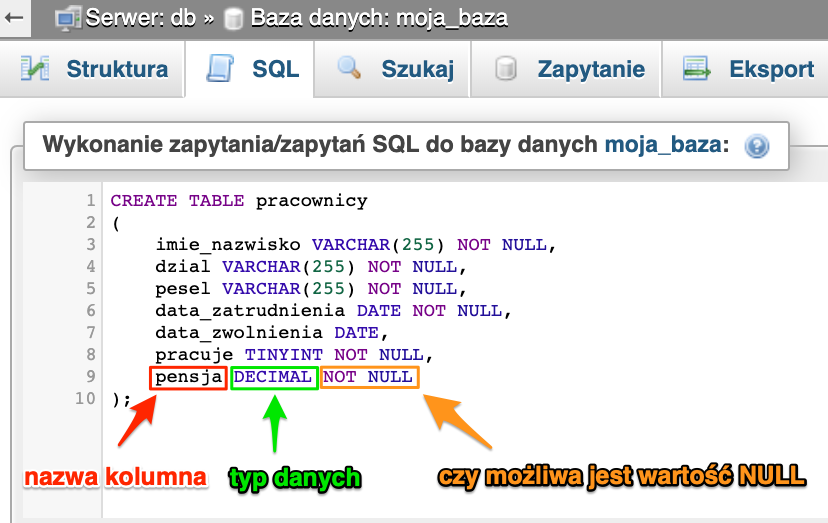
Skoro mamy już pełen obraz to czas zdefiniować pierwszą tabelę :D Zapytanie SQL poniżej.
REATE TABLE pracownicy
(
imie_nazwisko VARCHAR(255) NOT NULL,
dzial VARCHAR(255) NOT NULL,
pesel VARCHAR(255) NOT NULL,
data_zatrudnienia DATE NOT NULL,
data_zwolnienia DATE,
pracuje TINYINT NOT NULL,
pensja DECIMAL NOT NULL
);
Podglądając utworzoną strukturę w phpMyAdmin-ie zobaczymy następujący efekt.
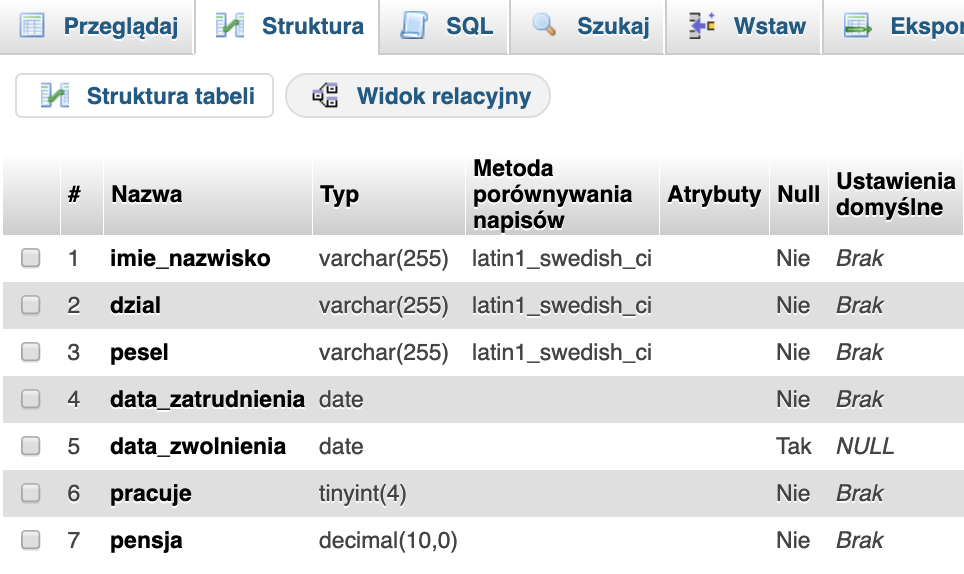
Niestety ta struktura nie jest idealna. Pierwsza wada to brak możliwości zapisania pensji z groszami ;) O ile sama pensja to pewnie nie problem, ale ceny produktów już problemem by były. Problem ten wynika z domyślnej definicji typu DECIMAL, którego rozwinięciem jest DECIMAL(10,0). Zanim wprowadzimy modyfikację szybko wyjaśnijmy sobie co oznaczają poszczególne elementy w typie DECIMAL.
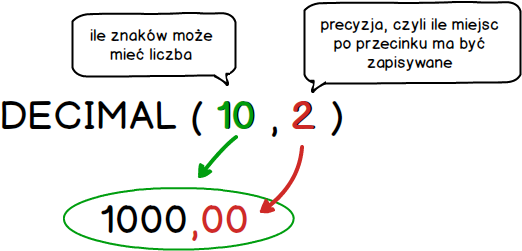
Wiedząc jak odczytywać typ DECIMAL zobaczmy jak zostanie przechowana wartość 1000 przy różnych ustawieniach.
DECIMAL(10,0) 1000 DECIMAL(10,2) 1000,00 DECIMAL(5,0) 1000 DECIMAL(5,2) ???
Trzy pierwsze przykłady doskonale wiedzieliście jak zostaną zapisane, ale co z ostatnim zapisem ?? Otóż przy tak zdefiniowanym typie wartości 1000 nie da się zapisać. Przy próbie wykonania takiej operacji baza danych zwróci błąd. Dlatego bardzo często typ ten zapisuje się w ten sposób DECIMAL(10,2). W większości przypadków będzie to wystarczający zapis. I dlatego wprowadzimy modyfikację w SQL-u tworzącym tabelę.
CREATE TABLE pracownicy
(
imie_nazwisko VARCHAR(255) NOT NULL,
dzial VARCHAR(255) NOT NULL,
pesel VARCHAR(255) NOT NULL,
data_zatrudnienia DATE NOT NULL,
data_zwolnienia DATE,
pracuje TINYINT NOT NULL,
pensja DECIMAL(10,2) NOT NULL
);
Drugą wadą tego zapytania jest definicja pola pracuje, które powinno być typu prawda/fałsz czyli BOOL. Niestety nie każda baza danych implementuje taki typ i w przypadku bazy MySQL nie mamy takiego typu. Rozwiązaniem jest użycie typu TINYINT, który zajmuje zaledwie 1 bajt. Niestety sami musimy zadbać o utrzymywanie wartości 0 / 1, gdyż typ ten ma zakres od 0 do 255 lub od -128 do 127.
Usuwanie tabel
Usuwanie tabel to operacja bardzo prosta, a sama składnia w porównaniu do składni tworzenia tabeli jest banalny.
DROP [TEMPORARY] TABLE [IF EXISTS] [/COMMENT TO SAVE/]
tbl_name [, tbl_name] ...
[WAIT n|NOWAIT]
[RESTRICT | CASCADE]
Jako że chcemy jedynie usunąć tabelę to wystarczy się ograniczyć do niezbędnego minimum. W tym celu pomijamy elementy opcjonalne i w ten sposób otrzymujemy poniższe zapytanie.
DROP TABLE pracownicy;
Zaczniemy od wykonania tego zapytania w phpMyAdminie, gdyż przy pisaniu zapytań będziemy otrzymywać podpowiedzi oraz od razu zobaczymy listę tabel.
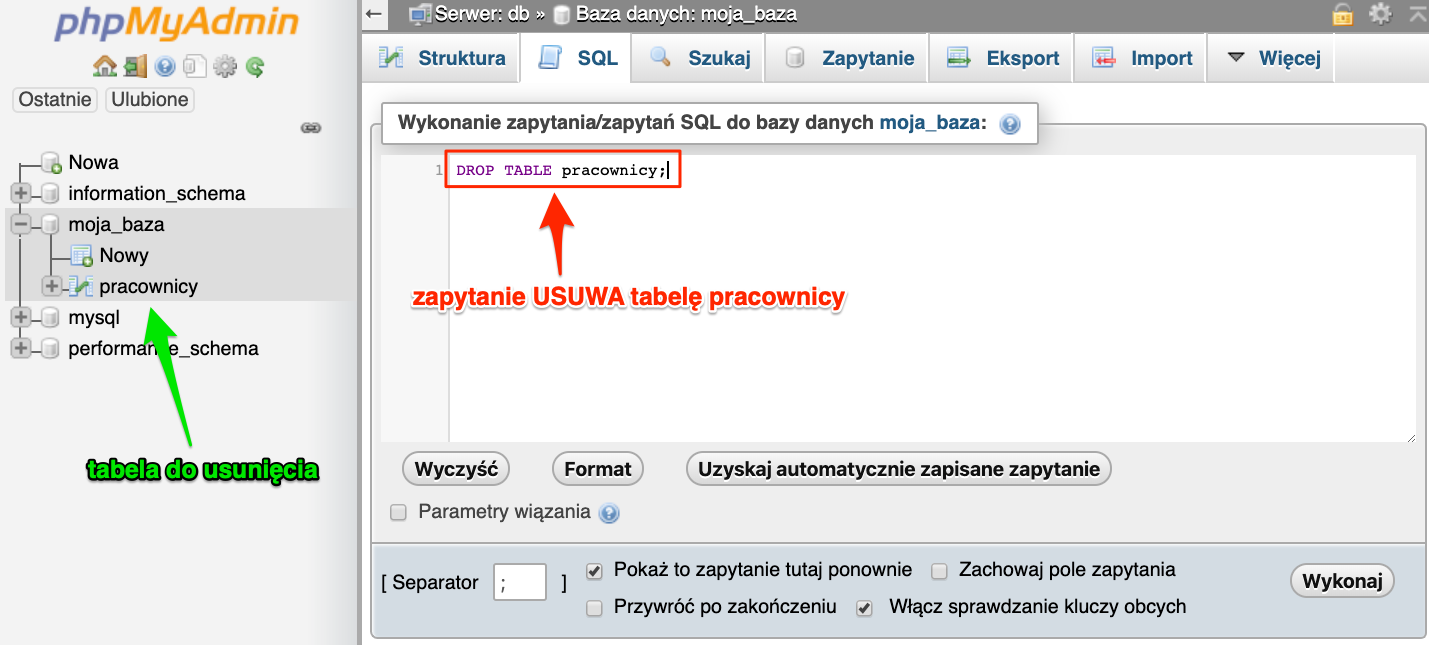
Próbując wykonać to zapytanie phpMyAdmin wyświetli nam ostrzeżenie z prośbą o potwierdzenie.
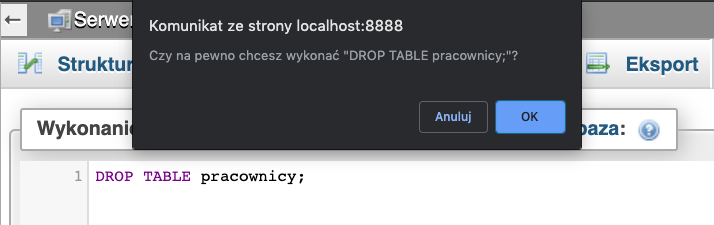
Ma to nas zabezpieczyć, przed wykonaniem zapytania usuwającego tabelę przez pomyłkę. Potwierdzamy chęć wykonania zapytania klikając OK.
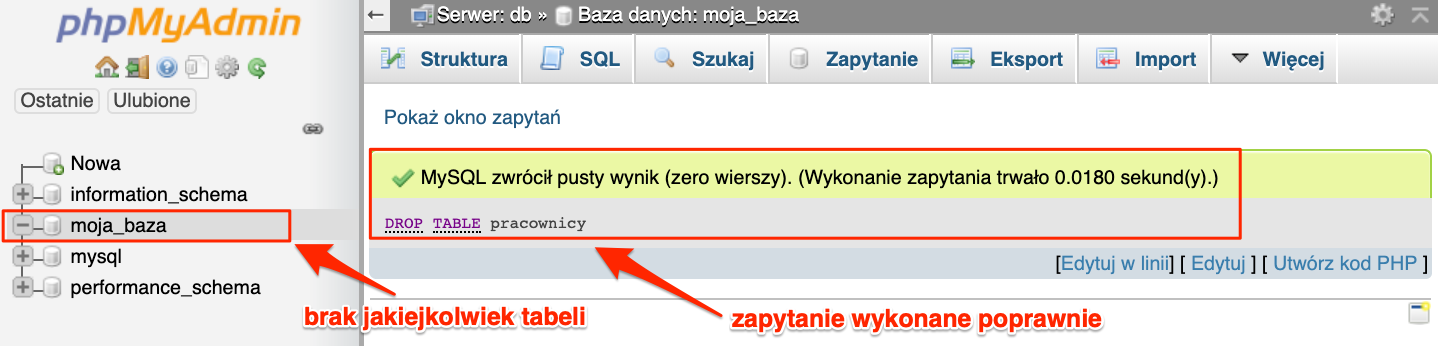
W przypadku gdy korzystamy z konsoli sprawa wygląda nieco inaczej. Samo zapytanie oczywiście pozostaje bez zmian jednak nie mamy co liczyć na dodatkowe pytanie, czy aby na pewno chcesz usunąć tabelę.

Operacja została wykonana poprawnie, a tabela została usunięta co możemy sprawdzić zapytaniem SHOW TABLES;

Zwrócono informację, że baza danych jest pusta. Co jest prawdą, mieliśmy jedną tabelę i ją usunęliśmy więc nie ma żadnych tabel.
Modyfikacja tabel
Podczas tworzenia tabeli okazało się, że domyślne ustawienia typu DECIMAL nie były dla nas satysfakcjonujące. W tamtym momencie rozwiązaliśmy ten problem usuwając i tworząc tabelę na nowo. Zapewne domyślasz się, że to nie najlepsze rozwiązanie i musi być możliwość modyfikacji istniejącej tabeli. I rzeczywiście tak jest, poniżej znajdziesz schemat zapytania, które to umożliwia.
ALTER [ONLINE] [IGNORE] TABLE tbl_name
[WAIT n | NOWAIT]
alter_specification [, alter_specification] ...
alter_specification:
table_option ...
| ADD [COLUMN] [IF NOT EXISTS] col_name column_definition [FIRST | AFTER col_name ]
| ADD [COLUMN] [IF NOT EXISTS] (col_name column_definition,...)
| ADD {INDEX|KEY} [IF NOT EXISTS] [index_name] [index_type] (index_col_name,...) [index_option] ...
| ADD [CONSTRAINT [symbol]] PRIMARY KEY [index_type] (index_col_name,...) [index_option] ...
| ADD [CONSTRAINT [symbol]] UNIQUE [INDEX|KEY] [index_name] [index_type] (index_col_name,...) [index_option] ...
| ADD FULLTEXT [INDEX|KEY] [index_name] (index_col_name,...) [index_option] ...
| ADD SPATIAL [INDEX|KEY] [index_name] (index_col_name,...) [index_option] ...
| ADD [CONSTRAINT [symbol]] FOREIGN KEY [IF NOT EXISTS] [index_name] (index_col_name,...) reference_definition
| ADD PERIOD FOR SYSTEM_TIME (start_column_name, end_column_name)
| ALTER [COLUMN] col_name SET DEFAULT literal
| (expression)
| ALTER [COLUMN] col_name DROP DEFAULT
| CHANGE [COLUMN] [IF EXISTS] old_col_name new_col_name column_definition [FIRST|AFTER col_name]
| MODIFY [COLUMN] [IF EXISTS] col_name column_definition [FIRST | AFTER col_name]
| DROP [COLUMN] [IF EXISTS] col_name [RESTRICT|CASCADE]
| DROP PRIMARY KEY
| DROP {INDEX|KEY} [IF EXISTS] index_name
| DROP FOREIGN KEY [IF EXISTS] fk_symbol
| DROP CONSTRAINT [IF EXISTS] constraint_name
| DISABLE KEYS
| ENABLE KEYS
| RENAME [TO] new_tbl_name
| ORDER BY col_name [, col_name] ...
| CONVERT TO CHARACTER SET charset_name [COLLATE collation_name]
| [DEFAULT] CHARACTER SET [=] charset_name
| [DEFAULT] COLLATE [=] collation_name
| DISCARD TABLESPACE
| IMPORT TABLESPACE
| ALGORITHM [=] {DEFAULT|INPLACE|COPY|NOCOPY|INSTANT}
| LOCK [=] {DEFAULT|NONE|SHARED|EXCLUSIVE}
| FORCE
| partition_options
| ADD PARTITION (partition_definition)
| DROP PARTITION partition_names
| COALESCE PARTITION number
| REORGANIZE PARTITION [partition_names INTO (partition_definitions)]
| ANALYZE PARTITION partition_names
| CHECK PARTITION partition_names
| OPTIMIZE PARTITION partition_names
| REBUILD PARTITION partition_names
| REPAIR PARTITION partition_names
| EXCHANGE PARTITION partition_name WITH TABLE tbl_name
| REMOVE PARTITIONING
| ADD SYSTEM VERSIONING
| DROP SYSTEM VERSIONING
index_col_name:
col_name [(length)] [ASC | DESC]
index_type:
USING {BTREE | HASH | RTREE}
index_option:
KEY_BLOCK_SIZE [=] value
| index_type
| WITH PARSER parser_name
| COMMENT 'string'
| CLUSTERING={YES| NO}
table_options:
table_option [[,] table_option] ..
Prawda że wygląda imponująco ? Nie martw się, nie będę próbował wytłumaczyć wszystkiego. Powoli przerobimy różne możliwości modyfikacji, teraz skupimy się na najbardziej podstawowych. Czyli dodamy nową kolumnę, zmodyfikujemy jej nazwę, zmienimy typ danych, a na koniec ją usuniemy.
Dodanie kolumny
W tym momencie lista kolumn w tabeli nie jest specjalnie rozbudowana. Znajdują się tam podstawowe dane pracowników.
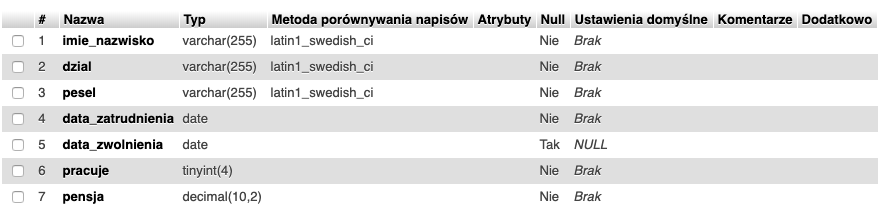
Dla nas te dane nie są wystarczające i chcemy je wzbogacić o numer telefonu. W tym celu potrzebujemy dodać nową kolumnę, która będzie przechowywała tekst. W związku z czym użyjemy typu VARCHAR i ustawimy maksymalną długość tekstu na 100 bajtów (mniej więcej 100 znaków).
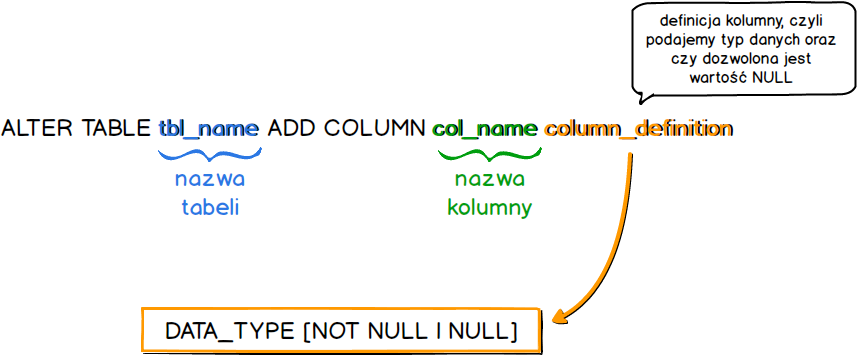
ALTER TABLE tbl_name ADD COLUMN col_name column_definition
Powyższą składnię możemy wytłumaczyć następująco.
Wiedząc co możemy podstawić pod odpowiednie elementy składni stwórzmy zapytanie dodające kolumnę.
ALTER TABLE pracownicy ADD COLUMN telefon VARCHAR(100) NOT NULL;
Możemy to przetłumaczyć następująco. Do tabeli pracownicy tbl_name dodajemy kolumnę telefon col_name typu VARCHAR(100) i nie chcemy w niej przechowywać wartości NULL NOT NULL.
Po wykonaniu zapytania struktura tabeli ulegnie zmianie. Na końcu została dodana nasza kolumna.

Kolejność kolumn dla bazy danych nie ma żadnego znaczenia, a kolumny w zapytaniach mogą być definiowane w dowolnej kolejności. Tylko my nie jesteśmy komputerami i dla nas kolejność kolumn może mieć znaczenie. Dużo wygodniej jest przeglądać dane, gdzie data zatrudnienia i zwolnienia są obok siebie. Podczas definiowania tabeli jest bardzo łatwo ustawić kolejność, a co w przypadku późniejszego dodawania kolumn ?
Chcąc dodać kolumnę w określonym miejscu, musimy delikatnie rozszerzyć nasze zapytanie.
ALTER TABLE tbl_name ADD COLUMN col_name column_definition [FIRST | AFTER col_name ]
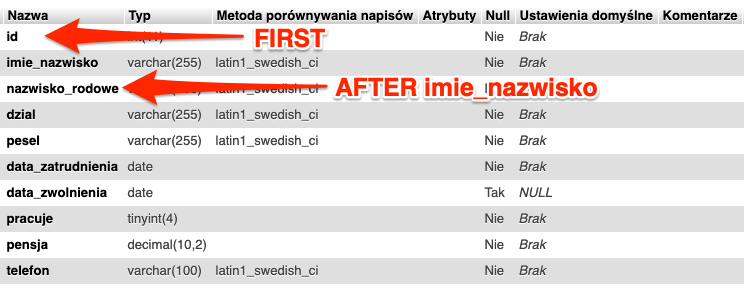
Na końcu pojawiła się opcjonalna sekcja [FIRST | AFTER col_name ]. Mamy do wyboru FIRST, czyli dodanie nowej kolumny na początku tabeli. Przykładowe zapytanie mogło by wyglądać następująco.
ALTER TABLE pracownicy ADD COLUMN id INT NOT NULL FIRST;
Druga opcja AFTER col_name pozwala nam określić za jaką kolumną ma się znaleźć nowo dodawana kolumna. Testowo dodamy kolumnę przechowującą nazwisko rodowe i chcemy, aby kolumna znalazła się za kolumną imie_nazwisko. W tym celu tworzymy zapytanie.
ALTER TABLE pracownicy ADD COLUMN nazwisko_rodowe VARCHAR(255) NOT NULL AFTER imie_nazwisko;
Po wykonaniu obu zapytań nasza tabela powinna wyglądać następująco.
Zmiana nazwy kolumny
Zmiany nazwy kolumn to nie operacja, którą wykonuje się często. A to dlatego, że przekłada się na konieczność wprowadzenia zmian w aplikacji, która daną bazę i tabelę wykorzystuje. Jednak czasem zmiany są konieczne zwłaszcza na wczesnym etapie developmentu. W naszym przypadku zmienimy nazwy kolumn z polskich na angielskie, gdyż w większości przypadków z nazwami angielskimi będziemy pracowali.
Schemat zapytania wygląda dość podobnie do operacji dodawania nowej kolumny.
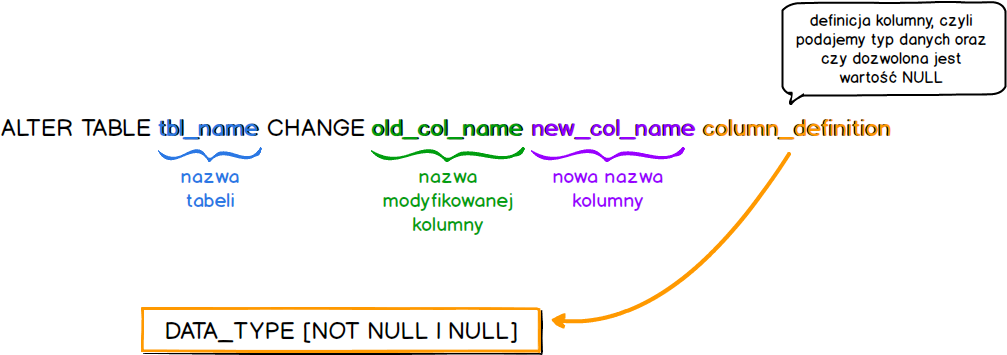
ALTER TABLE tbl_name CHANGE [COLUMN] [IF EXISTS] old_col_name new_col_name column_definition [FIRST|AFTER col_name]
Kastrując schemat ze wszystkich zbędnych elementów, pozostała by poniższa konstrukcja.
ALTER TABLE tbl_name CHANGE old_col_name new_col_name column_definition
Możemy ją zinterpretować w następujący sposób.
Niemal identycznie jak proces dodawania kolumny. Nieco dziwne może się wydawać ponowne podawanie danych dotyczących typu oraz informacji mówiącej czy kolumna może przechowywać NULL-a. Wynika to z faktu, że zapytanie to może także zmodyfikować typ kolumny. Ale o tym za chwilę 😉
Końcowe zapytanie wygląda następująco.
ALTER TABLE
pracownicy
CHANGE
imie_nazwisko name VARCHAR(255) NOT NULL;
Teraz zadanie dla Ciebie. Zmodyfikuj pozostałe kolumny zmieniając jedynie nazwy na angielskie odpowiedniki.
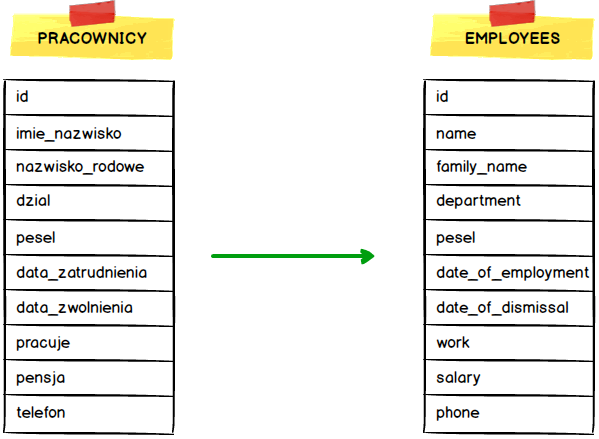
Przy okazji zmiany nazw kolumn zmieniłem także nazwę tabeli, aby zachować konsekwencję. Brak konsekwencji jest gorszy niż używanie polskich nazw kolumn i tabel ;)
Zmiana typu kolumny
Modyfikując nazwy kolumn zwróciliśmy uwagę na konieczność zdefiniowania parametrów kolumny. Tu możemy się zastanowić, co by było gdybym podali inne parametry ?? Otóż poza zmianą nazwy nastąpiła by zmiana ustawień kolumny. Tym samym znamy polecenie umożliwiające zmianę typu.
ALTER TABLE tbl_name CHANGE old_col_name new_col_name column_definition
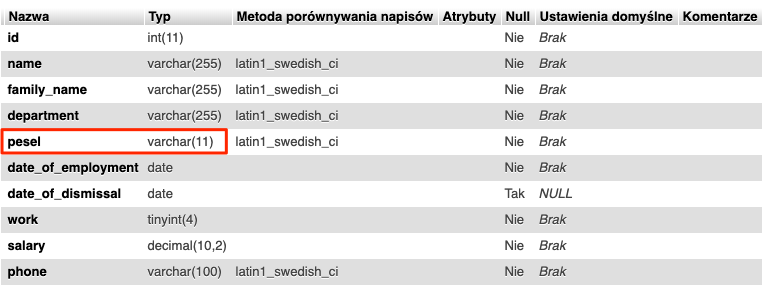
Oczywiście w przypadku gdy chcemy zmienić jedynie typ danych wpisujemy dwa razy tę samą nazwę kolumny. W naszym przypadku kolumna pesel nie musi przechowywać aż 255 znaków. Numer PESEL jest to 11-cyfrowy stały symbol numeryczny. W związku z czym zmodyfikujemy typ kolumny na VARCHAR(11).
ALTER TABLE employees CHANGE pesel pesel VARCHAR(11) NOT NULL;
Po wykonaniu zapytania nasza struktura powinna wyglądać następująco.
Usunięcie kolumny
Poznaliśmy już sposób na dodawanie oraz modyfikację kolumn, czas na ich usuwanie. Składnia w tym przypadku jest bardzo prosta i praktycznie początek możemy napisać na podstawie wcześniejszych zapytań.
ALTER TABLE tbl_name DROP col_name
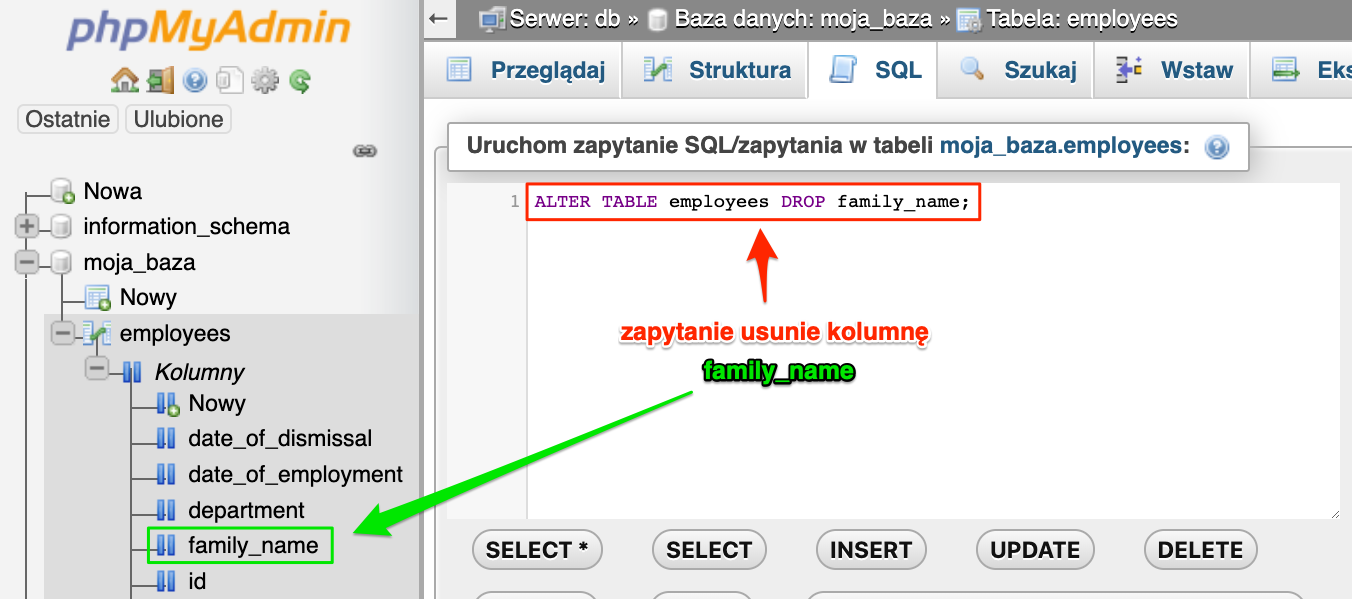
Pod tbl_name podstawiamy naszą jedyną tabelę employees, a kolumną którą usuniemy będzie nazwisko rodowe czyli family_name i podstawiamy je pod col_name. To w rezultacie utworzy nam poniższe zapytanie.
ALTER TABLE employees DROP family_name;
Wpisujemy je w phpMyAdmin i zobaczymy czy rzeczywiście kolumna zniknie.
Próba uruchomienia zapytania spowoduje wyświetlenie ostrzeżenia. Ma ono na celu zabezpieczyć nas przed omyłkowym usunięciem kolumny.
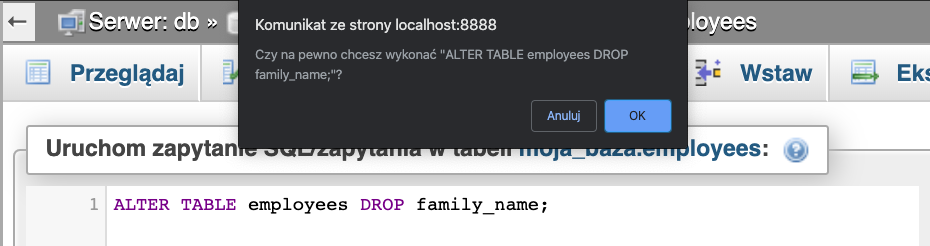
My jesteśmy pewni poprawności zapytania i chcemy usunąć kolumnę w związku z czym klikamy OK.
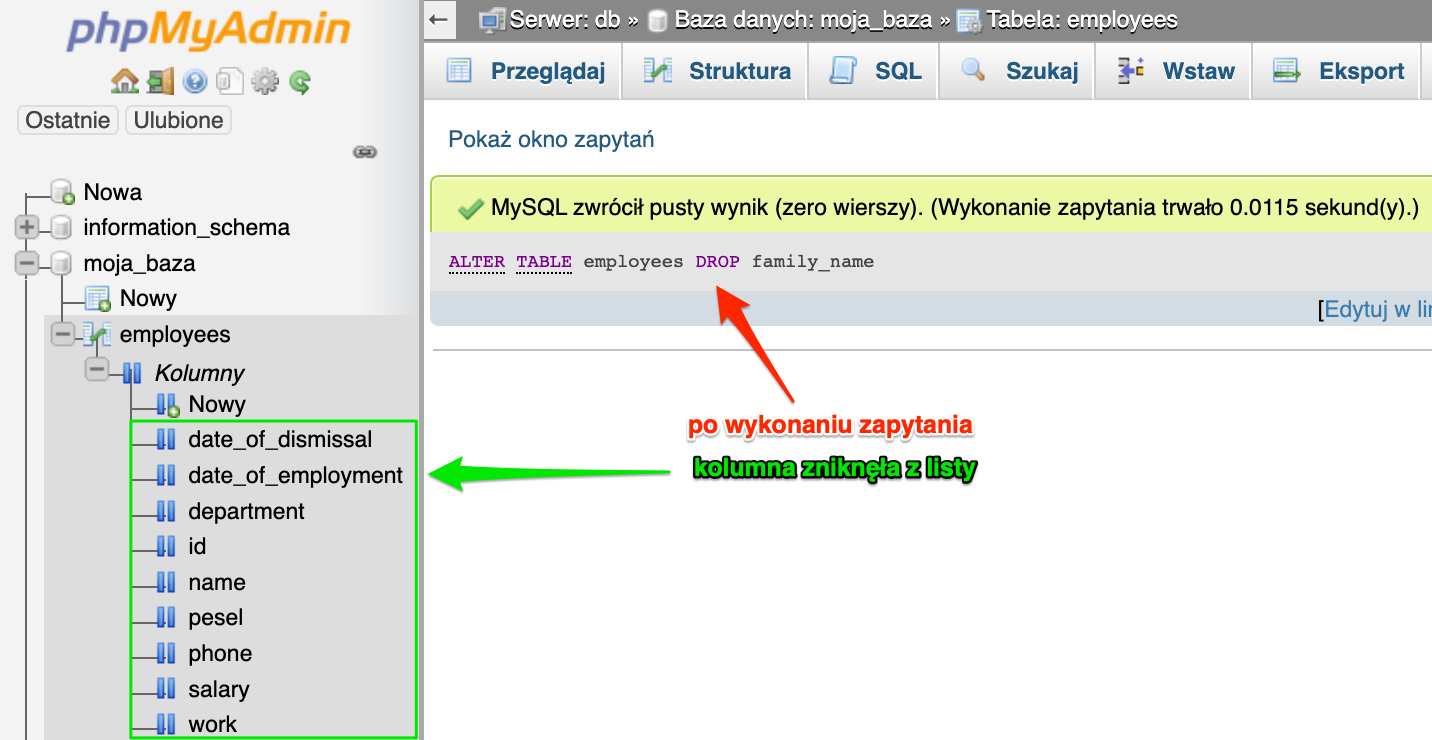
Zapytanie wykonało się poprawnie i kolumny nie ma już na liście. Operacja usunięcia kolumny wygląda analogicznie w konsoli z delikatną różnicą. Konsola nas nie spyta czy na pewno chcemy usunąć kolumnę tylko ją usunie.
Usuńmy kolejną kolumnę, tym razem z poziomu konsoli. Tym razem padło na kolumnę work. Zapytanie SQL będzie wyglądało identycznie jak poprzednio ze zmienioną jedynie nazwą kolumny do usunięcia.
ALTER TABLE employees DROP work;
I w konsoli widzimy to następująco.
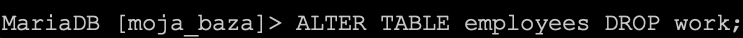
Zatwierdzając zapytanie enter-em spowodujemy usunięcie kolumny work.

Rzeczywiście zapytanie zostało wykonane poprawnie. Niestety nie widzimy listy kolumn tak jak ma to miejsce w phpMyAdmin. Ale pamiętajmy że phpMyAdmin jest jedynie klientem, który prezentuje dane. SQL dostarcza nam zapytanie listujące kolumny z danej tabeli.
SHOW COLUMNS FROM tbl_name
Prawda że bardzo prosty schemat, teraz tylko podstawiamy pod tbl_name nazwę tabeli i otrzymamy listę kolumn wraz z podstawowymi informacjami o nich.
SHOW COLUMNS FROM employees;
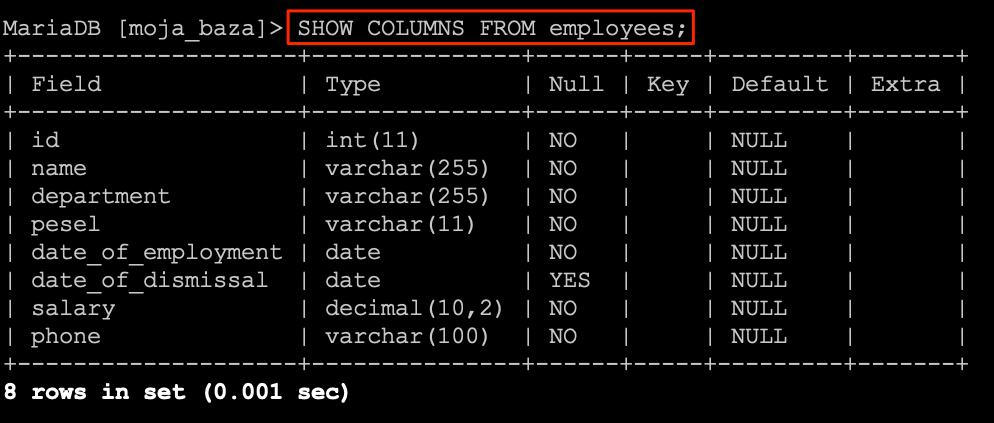
Nawet forma prezentacji danych jest bardzo przyjazna. Znajdziemy tutaj informację ile kolumn znajduje się w tabeli oraz typy danych jakie mogą przechowywać. Dodatkowo widzimy czy możliwe jest przechowywanie wartości NULL oraz jaka jest wartość domyślna w przypadku nie przekazania żadnej wartości przy dodawaniu rekordu do tabeli.
Ostatnią rzeczą o jakiej chciałem wspomnieć w przypadku usuwania kolumn są błędy. A dokładniej błędy przy wpisywaniu nazw kolumn. W przypadku phpMyAdmin-a jest nieco łatwiej, gdyż mamy podpowiedzi przy pisaniu zapytań. Gorzej z pisaniem zapytań w konsoli, tam nic nam nie podpowie nazwy kolumny, a przynajmniej nie standardowy klient dostarczany z bazą danych.
ALTER TABLE employees DROP nane;

Powyżej mamy zapytanie usuwające kolumnę. Łatwizna, przed chwilą je poznaliśmy. Niestety zrobiliśmy literówkę w nazwie kolumny i w rezultacie otrzymaliśmy błąd. Mówi on, że nie można usunąć kolumny o nazwie nane. I jesteśmy proszeni o sprawdzenie, czy dana kolumna istnieje w tabeli.
Operacje na danych
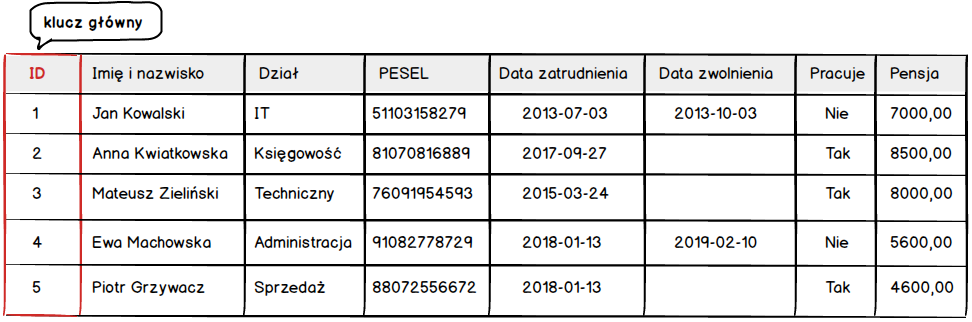
Baza danych jest, tabela jest, to czas na dodawanie danych. Nim przystąpimy do tej operacji musimy sobie porozmawiać o jednej sprawie. W tym celu rzućmy okiem na naszą początkową tabelę.
Tabela ta jest wypełniona danymi. Jedną z danych jest numer PESEL, który został wymyślony do identyfikacji osób. Można spytać się po co w ten sposób identyfikować osoby. Otóż wynika to z faktu, że identyfikacja osób na podstawie imienia i nazwiska była by bardzo problematyczna. W dużych miastach praktycznie niemożliwa. Do tego dochodzi możliwość zmiany miejsca zamieszkania, czy zmiana nazwiska. Mam nadzieję, że widzisz problem jednoznacznej identyfikacji osób 😉
Wyobraź sobie, że w tabeli masz 37 milionów rekordów. Jak znajdziesz siebie jeśli nie po numerze PESEL ?? Tego typu numery są idealnym rozwiązaniem problemu i w bazach danych kryją się pod nazwą klucza podstawowego.
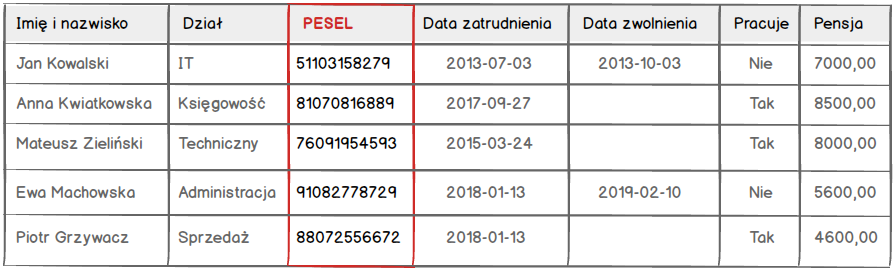
Klucz podstawowy
Tak jak wspominałem wcześniej w przypadku naszej tabeli możemy użyć kolumny PESEL jako klucza podstawowego (ang. primary key).
I na ten moment zapewne by to wystarczyło. Co jednak, gdy żadna z kolumn przechowujących dane nie może nam posłużyć jako klucz podstawowy ??
Tak, dobrze myślisz zakładamy kolumnę, która będzie przechowywała unikalny numer dla każdego rekordu w tabeli. Najczęściej spotkasz się z kolumną o nazwie id i z reguły jest to pierwsza kolumna w tabeli. Oczywiście nazwa i kolejność mogą być dowolne jednak umieszczanie kolumny jako pierwszej z nazwą id jest dobrą praktyką.
Wiemy jak dodać nową kolumnę, o określonej nazwie i danego typu. W tym przypadku wyglądało by to następująco.
ALTER TABLE employees ADD COLUMN id INT NOT NULL FIRST;
Jest to dokładnie to samo zapytanie, które już wykonywaliśmy i taka kolumna znajduje się w naszej tabeli. Teraz wzbogacimy zapytanie o informację, że dana kolumna na być kluczem podstawowym. Schemat takiego zapytania prezentuje się następująco.
ALTER TABLE tbl_name ADD COLUMN col_name column_definition [FIRST | AFTER col_name ], ADD PRIMARY KEY (col_name, ...)
Widzimy że zmieniła się jedynie końcówka, gdzie pojawił się zapis ADD PRIMARY KEY. Po którym w nawiasach klamrowych podajemy listę kolumn, które mają stanowić klucz podstawowy. U nas będzie to tylko jedna kolumna, ale klucz podstawowy może składać się z kilku kolumn. Nas to w tym momencie nie interesuje ;)
Zobaczmy zmodyfikowane zapytanie tworzące kolumnę i ustawiające ją jako klucz podstawowy.
ALTER TABLE employees ADD COLUMN id INT NOT NULL FIRST, ADD PRIMARY KEY (id);
Prawda że proste, dodaliśmy jedynie zapis ADD PRIMARY KEY (id) i po bólu. Niestety jeśli spróbujemy dodać tę kolumnę do bazy na której dotychczas pracowaliśmy możemy otrzymać błąd.
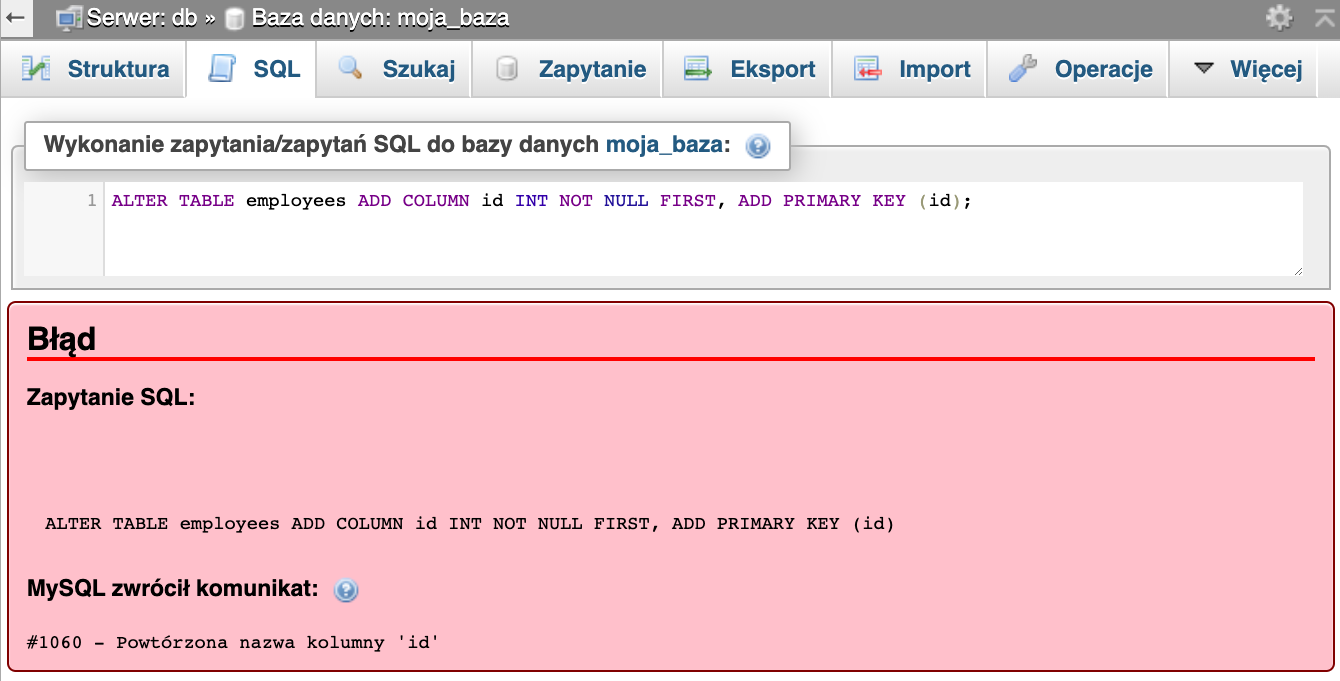
Czytamy w nim, że kolumna o nazwie id już istnieje. Co w takim przypadku ?? Dodajemy klucz główny do istniejącej kolumny. A zapytanie praktycznie znamy, bo wystarczy pominąć tworzenie kolumny i mamy zapytanie dodające klucz główny do danej kolumny.
ALTER TABLE tbl_name ADD PRIMARY KEY (col_name, ...)
Czyli w naszym przypadku będzie ono wyglądało następująco.
ALTER TABLE employees ADD PRIMARY KEY (id);
Po poprawnym wykonaniu zapytania w phpMyAdmin powinniśmy w strukturze tabeli zobaczyć dodatkową ikonę żółtego kluczyka przy kolumnie id.
![]()
Gdy posługujemy się konsolą to także mamy stosowną informację o kluczu podstawowym.
SHOW COLUMNS FROM employees;
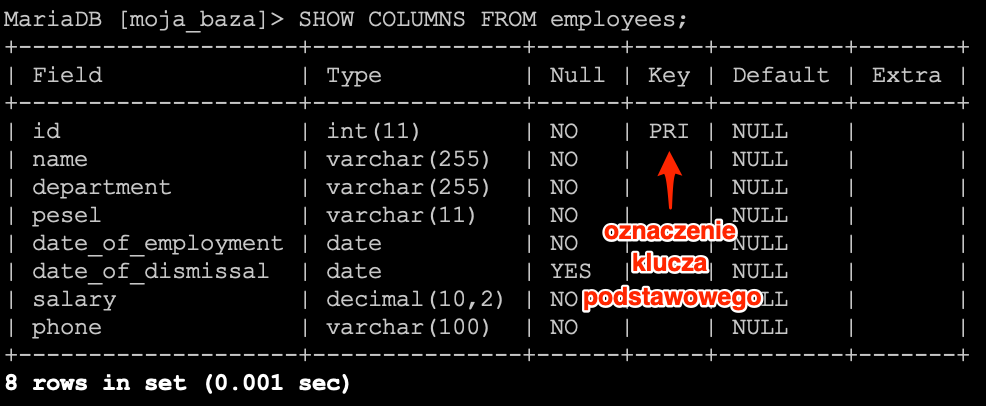
Wszystko widać jak na dłoni. Teraz pozostaje tylko generować unikane identyfikatory dla każdego rekordu. I tu mamy kilka podejść, pierwsze bardzo proste oparte o wartości liczbowe. W tym podejściu każdy rekord otrzymuje unikalną liczbę, co wymusza na nas sprawdzanie czy rekord o podanej liczbie już nie istnieje. Najprostszą implementacją tego rozwiązania jest dodawanie rekordów z kolejnymi liczbami. Pierwszy rekord otrzymuje liczbę 1, drugi 2, trzeci 3 itd. Oznacza to że musimy przed dodaniem sprawdzić jaka jest największa liczba i zwiększyć jej wartość o 1. W ten sposób otrzymując identyfikator, który jeszcze nie został wykorzystany. Uproszczony model można zobaczyć poniżej.
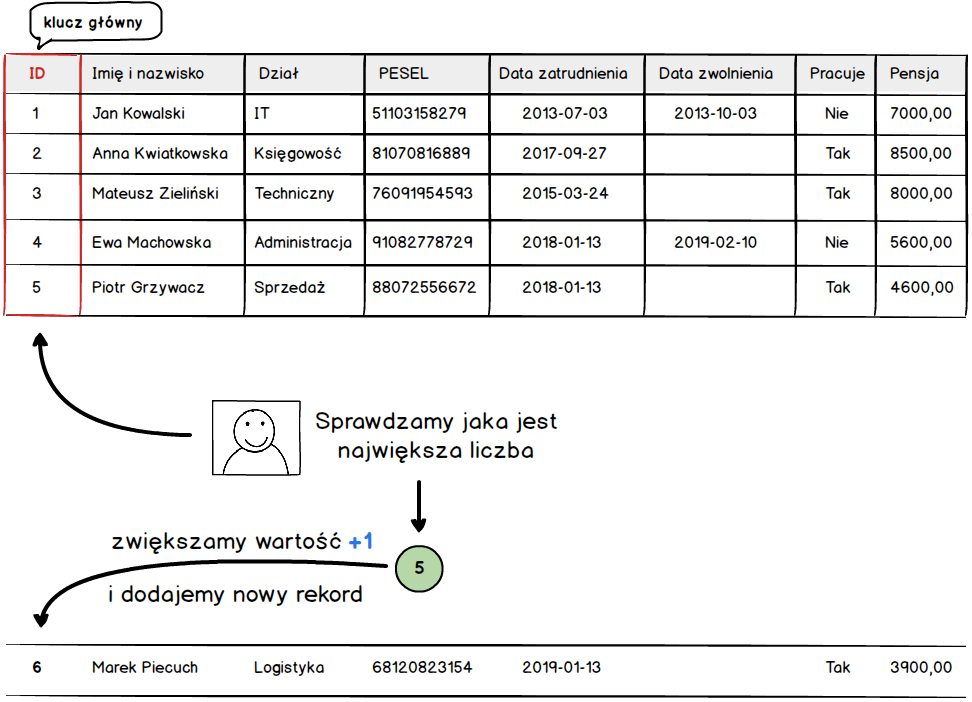
Niestety podejście to ma jeden zasadniczy problem. Mianowicie gdy dwóch użytkowników, próbuje wykonać operację dodawania na tej samej tabeli w tym samym czasie to jeden z nich otrzyma błąd.
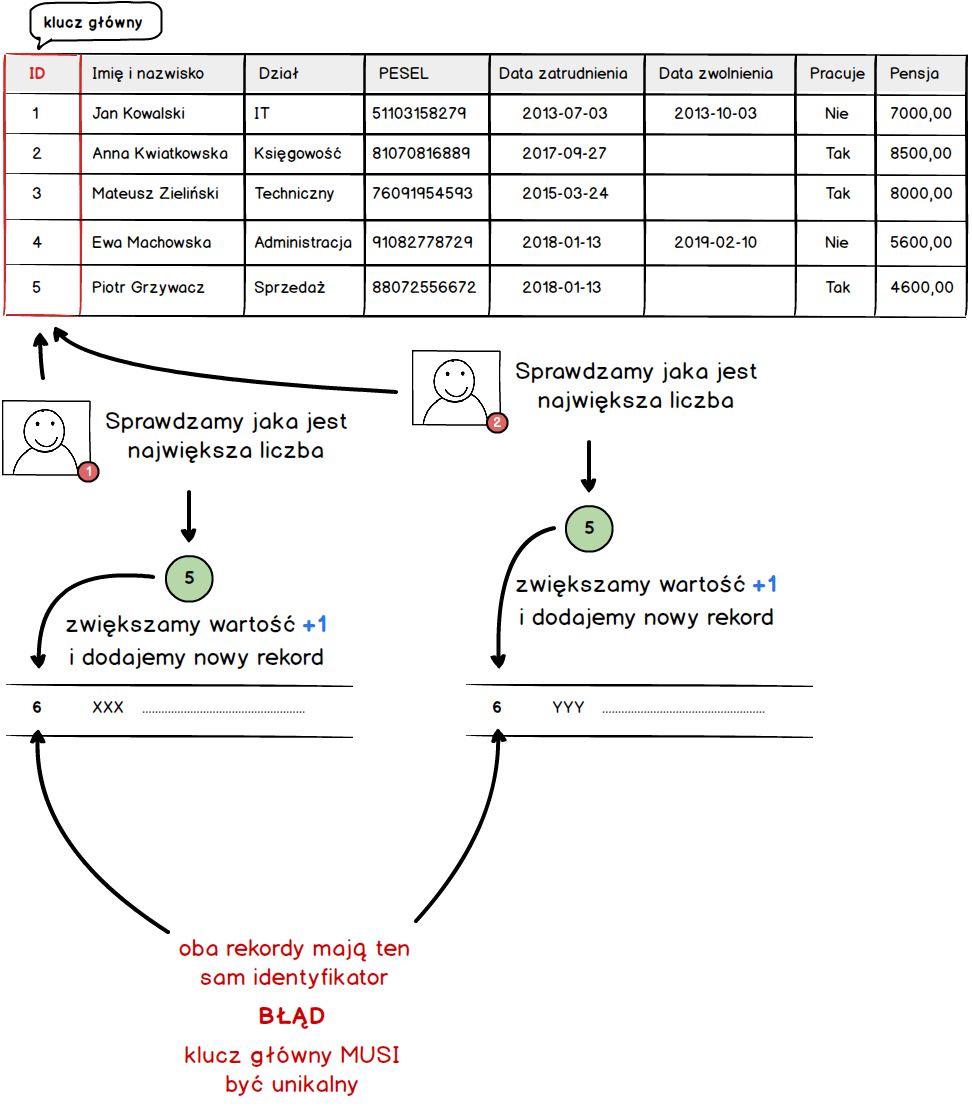
Powyższego błędu nie zauważy tylko pierwszy użytkownik, gdyż w momencie dodawania rekordu do bazy takiego identyfikatora nie będzie. Każdy kolejny użytkownik otrzyma błąd. Niestety zaobserwowanie tego błędu nie jest takie łatwe ze względu na wydajność bazy oraz konieczność wykonania operacji dokładnie w tym samym czasie. Na szczęście jest rozwiązanie tego problemu i nazywa się Auto-increment, czyli przerzucenie na bazę danych odpowiedzialności za generowanie kolejnych numerów.
Innym podejściem do tematu jest generowanie UUID ( ang. universally unique identifier ).
Unikatowy identyfikator uniwersalny ( UUID ) jest 128-bitowy numer używany do identyfikacji informacji w systemach komputerowych
Upraszczając jest to pewien ciąg znaków, który z założenia ma być unikalny i losowy. Ma także zapewniać praktycznie bezkolizyjność, czyli nie zostanie wygenerowany ten sam UUID co jest konieczne jeśli chcemy używać go jako klucza głównego.
Większość systemów wykorzystuje pierwsze podejście, czyli przerzucenie odpowiedzialności na bazę danych. Jest to bardzo wygodne rozwiązanie, a my na początku swojej przygody nie potrzebujemy zbytnio komplikować sobie życia ;)
Auto Increment
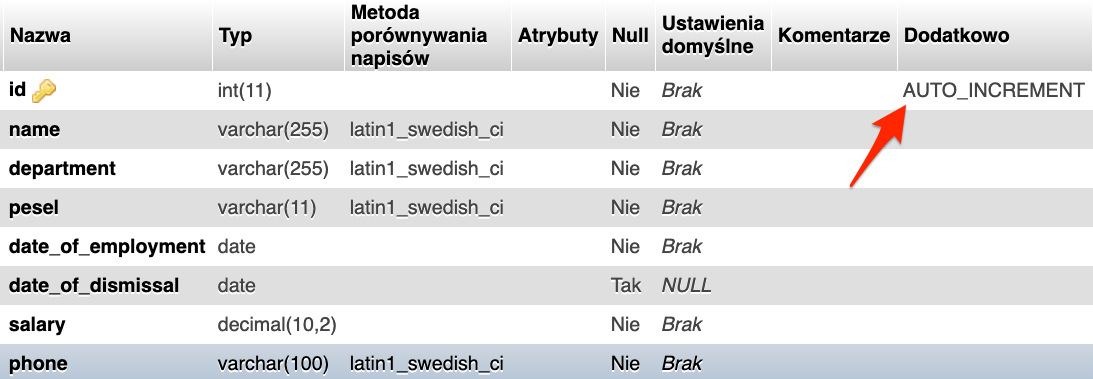
Opcja auto inkrementacji, czyli automatycznego zwiększania liczby o jeden w określonej kolumnie jest przydatna, gdy chcemy aby baza automatycznie generowała identyfikatory w kolumnie będącej kluczem głównym. Teraz pytanie jak to zrobić ??
Zacznijmy od najprostszej sytuacji, czyli dodajemy nową kolumnę. Kolumna id ma być kluczem głównym i ma posiadać opcję auto inkrementacji.
ALTER TABLE employees
ADD COLUMN id INT NOT NULL AUTO_INCREMENT FIRST,
ADD PRIMARY KEY (id);
Jedyna różnica w stosunku do poprzedniego zapytania, gdzie tworzyliśmy kolumnę będącą kluczem głównym, jest dodanie do zapytania AUTO_INCREMENT przy nazwie kolumny.
Gdybym jednak mieli już kolumnę będącą kluczem podstawowym oraz kolumna ta była by liczbą, to możemy dodać opcję auto inkrementacji używając polecenia modyfikacji kolumny.
ALTER TABLE `employees`
CHANGE `id` `id` INT(11) NOT NULL AUTO_INCREMENT;
I w ten sposób właśnie kolumna id otrzymała dodatkowe ustawienie.
Dodawanie rekordów
Czas w końcu dodać jakieś rekordy do tabeli w naszej bazie danych. Do dodawania rekordów służy instrukcja INSERT, której uproszczona składnia prezentuje się następująco.
INSERT [INTO] tbl_name [(col,...)] {VALUES | VALUE} ({expr | DEFAULT},...),(...),...
Składnia ta daje nam możliwość przygotowania zapytania dodającego dane na dwa sposoby. Pierwszy z pominięciem listy kolumn.
INSERT INTO `employees` VALUES (NULL, 'Marcin', 'IT', '88052384376', '2019-04-09', NULL, '10000', '888767545');
Zapytanie to wstawia nowy rekord do tabeli employees, gdzie kolejność poszczególnych wartości jest zgodna kolejnością kolumn w tabeli. Co możemy wizualizować jak na poniższej grafice.

Pierwsze co rzuca się w oczy to wartość NULL przypisana do kolumny id. I spieszę wyjaśnić, że możemy oczywiście podać identyfikator, ale po co skoro mamy opcję AUTO_INCREMENT na tej kolumnie i baza sama zadba o wpisanie tam odpowiedniego identyfikatora.
Kolejna sprawa to konieczność pamiętania lub sprawdzenia dokładnej kolejności kolumn w tabeli. Jest to ekstremalnie niewygodne zwłaszcza w kontekście możliwych modyfikacji tabeli. Dodając jakąkolwiek kolumnę do tabeli employees spowodujemy, że nasze zapytania dodające przestaną działać. Dlatego też mamy do dyspozycji drugą składnię, w której wymieniamy listę kolumn oraz wartości jakie mają trafić do poszczególnych kolumn.
INSERT INTO `employees`
(`id`, `name`, `department`, `pesel`, `date_of_employment`, `date_of_dismissal`, `salary`, `phone`) VALUES
(NULL, 'Marcin', 'IT', '88052384376', '2019-04-09', NULL, '10000.00', '888767545');
Powyższe zapytanie jest dokładnie takim samym zapytaniem jak poprzednio. Z tą drobną różnicą, że mamy wymienione nazwy kolumn. A skoro mamy wymienione nazwy kolumn to możemy modyfikować dowolnie ich kolejność i usuwać te nieistotne. W tym zapytaniu całkowicie zbędna jest kolumna id której nie ustawiamy wartości oraz date_of_dismissal, której ustawiamy wartość NULL.
INSERT INTO `employees`
(`name`, `department`, `pesel`, `date_of_employment`, `salary`, `phone`) VALUES
('Marcin', 'IT', '88052384376', '2019-04-09', '10000.00', '888767545');
I w ten sposób mamy jedynie listę kolumn dla których ustawiamy jakieś wartości. Dodatkowo możecie się pobawić i zmienić kolejność kolumn oraz wartości dla nich i zobaczyć, że dalej wszystko działa prawidłowo.
Dla zaintersowanych ;) MySQL dostarcza jeszcze jedną składnię, która łączy zalety składni zawierającej nazwy kolumn wraz z poprawą czytelności zapytań.
INSERT INTO
`employees`
SET
`name` = 'Marcin',
`department` = 'IT',
`pesel` = '88052384376',
`date_of_employment` = '2019-04-09',
`salary` = '10000.00',
`phone` = '888767545';
Prawda że czytelnie, jeśli będziecie pracować tylko z MySQL-em czy MariaDB to zachęcam do używania tej składni. Nawet zapytanie nie sformatowane wygląda bardzo przyjemnie.
INSERT INTO `employees` SET `name` = 'Marcin', `department` = 'IT', `pesel` = '88052384376', `date_of_employment` = '2019-04-09', `salary` = '10000.00', `phone` = '888767545';
Przeglądanie rekordów
Mamy już jakieś rekordy w tabeli i chcieli byśmy je zobaczyć. W phpMyAdmin-ie sprawa jest prosta, klikamy zakładkę Przeglądaj i widzimy zawartość tabeli, a gdy rekordów jest za dużo to lista jest podzielona na podstrony.
Zaletą phpMyAdmin-a jest to, że zawsze pokazuje nam ja wygląda zapytanie SQL przy okazji wykonywania danej czynności. W tym przypadku widzimy dzięki jakiemu zapytaniu SQL, phpMyAdmin wygenerował listę rekordów z tabeli employees.

Wiemy więc, że mamy do czynienia z zapytaniem SELECT, którego uproszczona składnia wygląda następująco.
SELECT
select_expr [, select_expr ...]
FROM
tbl_name
[WHERE where_condition]
[GROUP BY {col_name | expr | position} [ASC | DESC]]
[HAVING where_condition]
[ORDER BY {col_name | expr | position} [ASC | DESC], ...]
[LIMIT {[offset,] row_count | row_count OFFSET offset}]
Po słowie kluczowym SELECT mamy select_expr, które oznacza jakieś wyrażenie, a takim wyrażeniem jest nazwa kolumny. Dalej znajdziemy tbl_name pod które podstawiamy nazwę kolumny. Mając tę wiedzę możemy utworzyć pierwsze zapytanie.
SELECT `id`, `name`, `department`, `pesel`, `date_of_employment`, `date_of_dismissal`, `salary`, `phone` FROM `employees`;
Zwróci ono listę wszystkich rekordów z tabeli employees.
Zmieniając kolejność kolumn w zapytaniu, zmienimy zwracany wynik. Przykładowo chcemy, aby identyfikator był ostatnią kolumną.
SELECT `name`, `department`, `pesel`, `date_of_employment`, `date_of_dismissal`, `salary`, `phone`, `id` FROM `employees`;
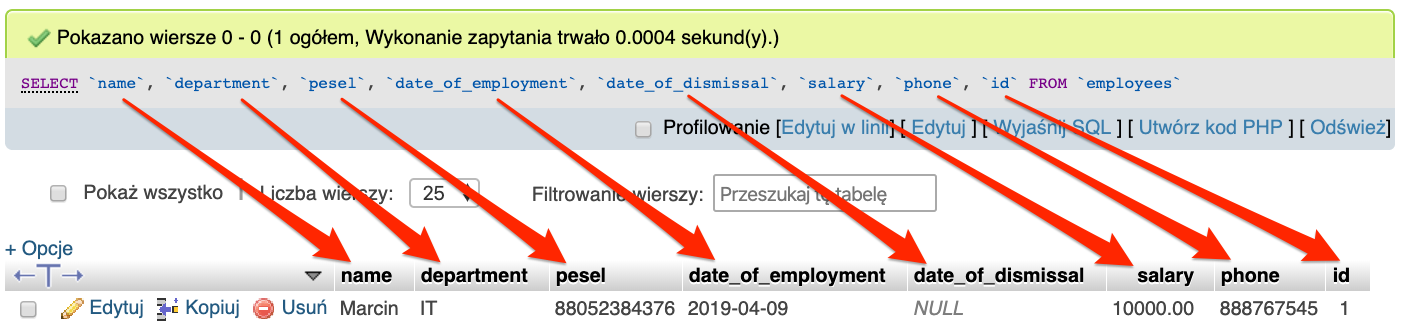
Należy pamiętać, że sama kolejność kolumn zwracanych z bazy nie ma większego znaczenia. Dlatego w większości przypadków spotkamy się ze skróconą formą zapisu wszystkich kolumn, czyli *. Co da nam zapytanie wyglądające następująco.
SELECT * FROM employees;
Rezultatem wykonania tego zapytania będzie zwrócenie wszystkich rekordów znajdujących się w tabeli pracownicy. Co jednak, gdy w tabeli znajdą się setki albo tysiące rekordów ?? Czy nie lepszym rozwiązaniem było by ograniczenie zwracanej listy rekordów do kilkudziesięciu pozycji i dodanie mechanizmu stronicowania w aplikacji ?? Właśnie do tego celu służy klauzula LIMIT.
Klauzula ORDER BY
ORDER BY czyli klauzula odpowiedzialna za sortowanie rekordów. Uproszczony zapis tej klauzuli może wyglądać następująco.
ORDER BY col_name [ASC|DESC], ...
Po klauzuli ORDER BY podajemy listę kolumn po których chcieli byśmy, aby zostało wykonane sortowanie. Na pojedynczy parametr klauzuli składają się dwa elementy, pierwszy col_name reprezentujący nazwę kolumny. Drugi parametr to rodzaj sortowanie, do dyspozycji mamy dwie opcje:
- ASC – sortowanie rosnące,
- DESC – sortowanie malejące,
Przy czym drugi parametr jest opcjonalny, jeśli go nie podamy to domyślnie wybierane jest sortowanie rosnące ASC.
Zacznijmy od posortowania rosnąco rekordów, po kolumnie name.
SELECT * FROM `employees` ORDER BY `name` ASC;
Powyższe zapytanie będzie równoznaczne z zapytaniem bez ASC.
SELECT * FROM `employees` ORDER BY `name`;
W obu przypadkach otrzymamy następującą listę rekordów.
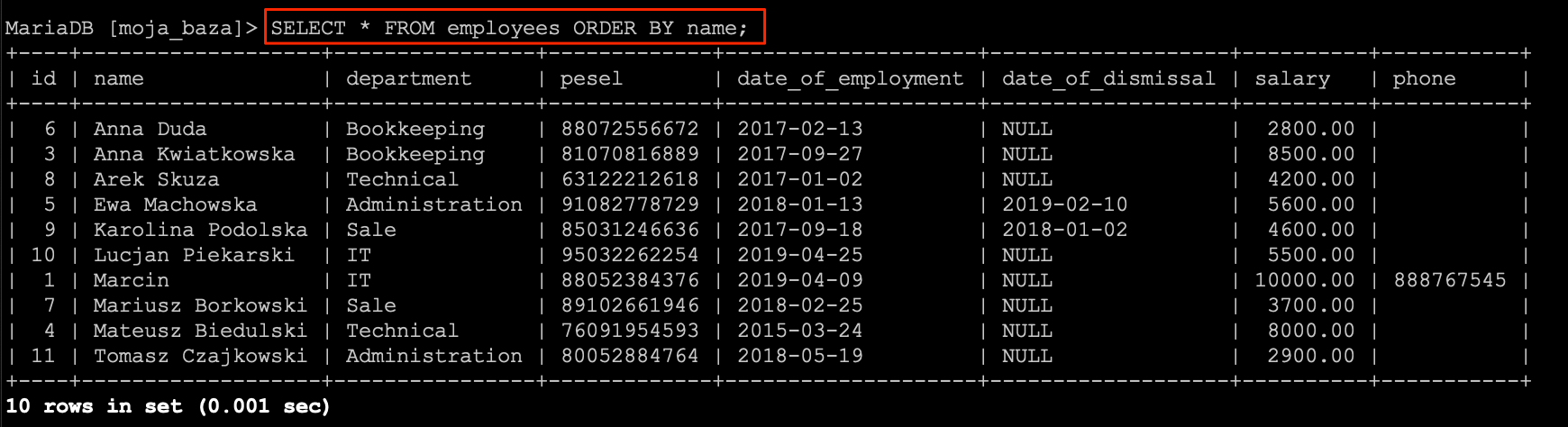
Gdybym chcieli przesortować pracowników od tych najlepiej zarabiających do tych najgorzej to skorzystali byśmy z poniższego zapytania.
SELECT * FROM `employees` ORDER BY `salary` DESC;
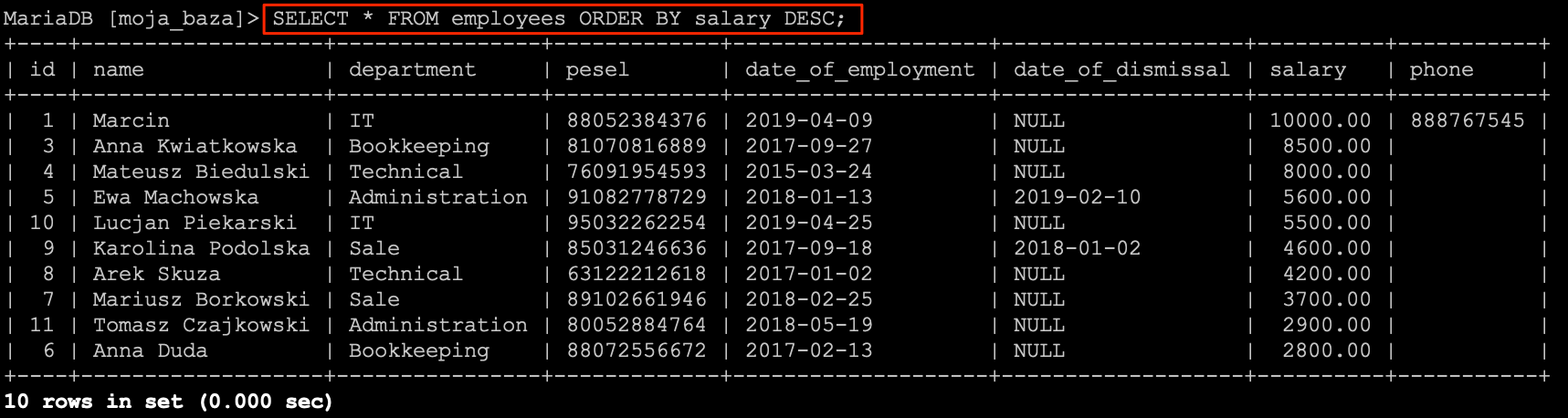
Ale żeby było minimalnie trudniej to posortujmy te dane działami.
SELECT * FROM `employees` ORDER BY `department`, `salary` DESC;
W ten sposób uzyskaliśmy sortowanie po dwóch kolumnach. Pierwsza kolumna department jest sortowana domyślnie rosnąco, dzięki czemu otrzymamy rekordy z danego działu obok siebie. Następnie sortujemy po kolumnie salary w sposób DESC, czyli malejąco. Rezultatem tego zapytania będzie lista rekordów “pogrupowana” działami, a w ramach działów zobaczymy pensje pracowników ułożone od najwyższych do najniższych.
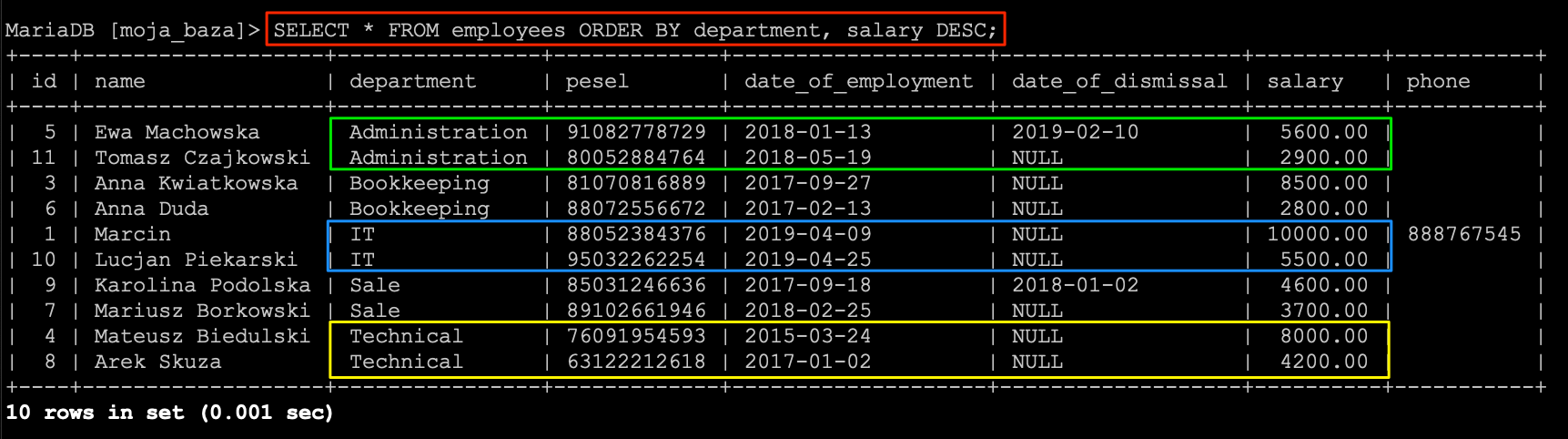
W ten prosty sposób możemy sortować rekordy po dowolnej kolumnie.
Klauzula LIMIT
Klauzula LIMIT jest często spotykana w kontekście zapytania SELECT zwłaszcza, gdy w aplikacji wyświetlamy zawartości tabel. W takich przypadkach praktycznie zawsze mamy mechanizm stronicowania. Do opracowania takiego mechanizm z wykorzystaniem SQL-a konieczna będzie znajomość klauzuli LIMIT.
Schemat zapisu wygląda następująco.
LIMIT {[offset,] row_count | row_count OFFSET offset}
Zanim zaczniemy, dodajmy sobie kilka rekordów do tabeli pracownicy. Pozwoli nam to lepiej zobaczyć jak działają poszczególne parametry. Poniżej przygotowałem kilka zapytań SQL, które dodadzą nam pracowników do naszej tabeli.
INSERT INTO employees (`id`, `name`, `department`, `pesel`, `date_of_employment`, `date_of_dismissal`, `salary`, `phone`) VALUES
(NULL, 'Anna Kwiatkowska', 'Bookkeeping', '81070816889', '2017-09-27', NULL, '8500.00', ''),
(NULL, 'Mateusz Biedulski', 'Technical', '76091954593', '2015-03-24', NULL, '8000.00', ''),
(NULL, 'Ewa Machowska', 'Administration', '91082778729', '2018-01-13', '2019-02-10', '5600.00', ''),
(NULL, 'Anna Duda', 'Bookkeeping', '88072556672', '2017-02-13', NULL, '2800.00', ''),
(NULL, 'Mariusz Borkowski', 'Sale', '89102661946', '2018-02-25', NULL, '3700.00', ''),
(NULL, 'Arek Skuza', 'Technical', '63122212618', '2017-01-02', NULL, '4200.00', ''),
(NULL, 'Karolina Podolska', 'Sale', '85031246636', '2017-09-18', '2018-01-02', '4600.00', ''),
(NULL, 'Lucjan Piekarski', 'IT', '95032262254', '2019-04-25', NULL, '5500.00', ''),
(NULL, 'Tomasz Czajkowski', 'Administration', '80052884764', '2018-05-19', NULL, '2900.00', '');
W rezultacie powinniśmy mieć tabelę z poniższą zawartością.
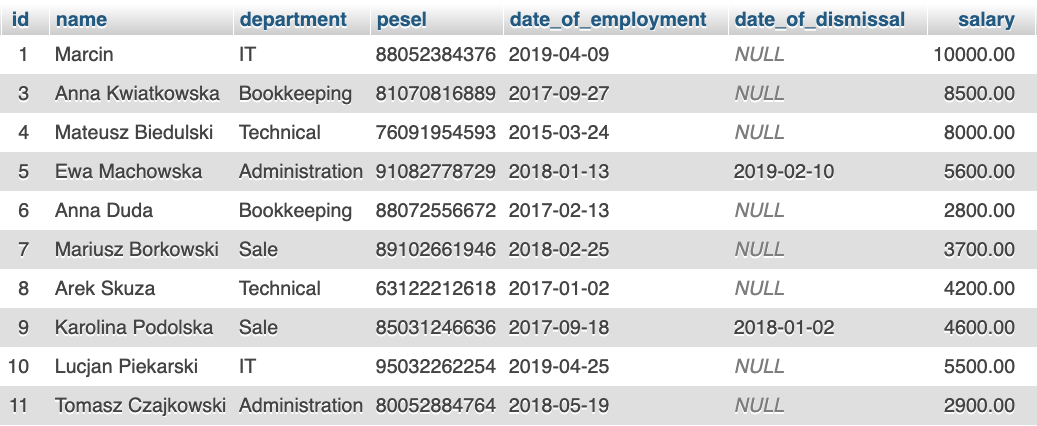
Skoro mamy już wypełnioną tabelę to przejdźmy do samej klauzuli. Zacznijmy od najprostszej postaci schematu, czyli podamy tylko ile rekordów ma zostać wyświetlonych.
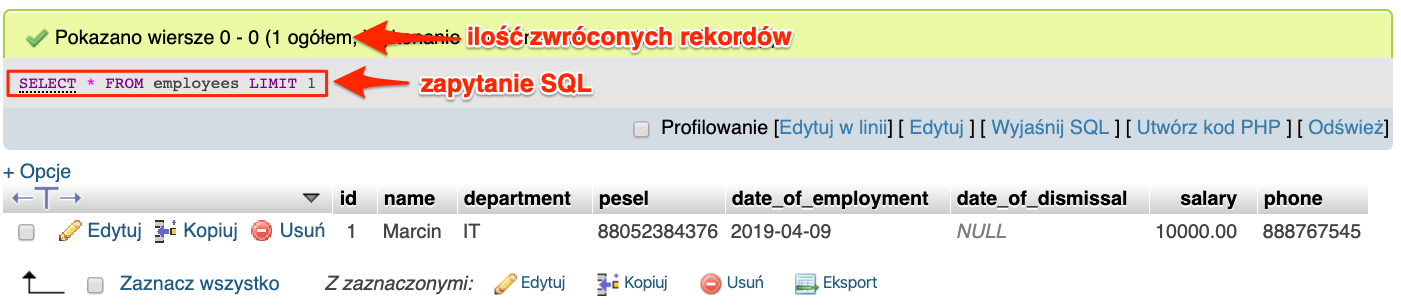
SELECT * FROM `employees` LIMIT 1;
Co w rezultacie zwróci nam tylko jeden rekord.
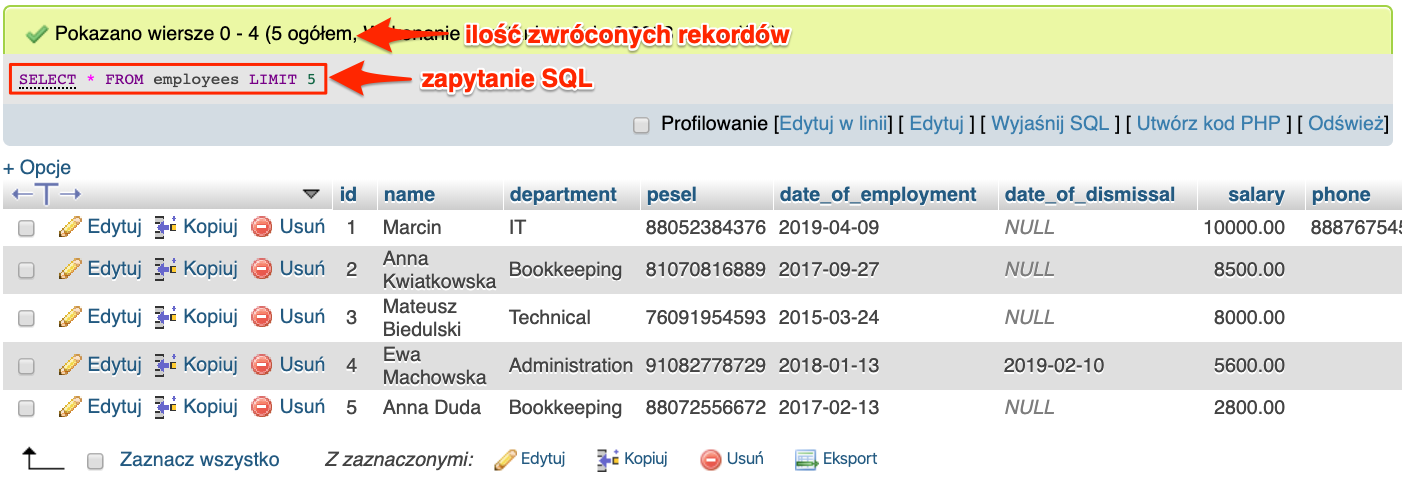
Gdy zmienimy nieco zapytanie, i wpiszemy zamiast 1 wartość 5 to powinniśmy zobaczyć pięć pierwszych rekordów z naszej tabeli.
SELECT * FROM `employees` LIMIT 5;
A żeby w pełni zrozumieć zasadę mała wizualizacja. Jak wpływa zmiana wartości LIMIT na listę zwracanych rekordów.
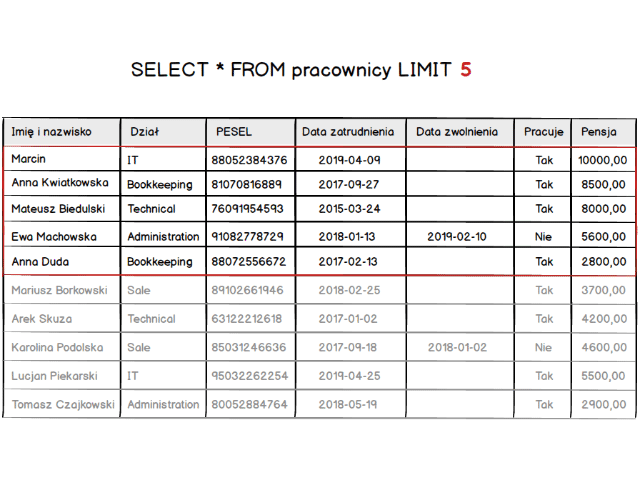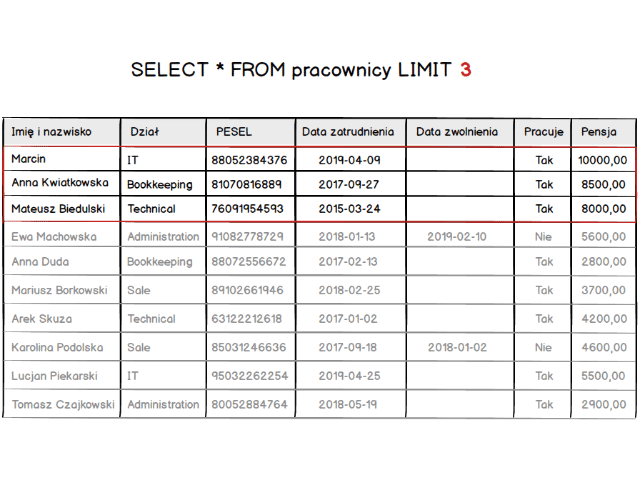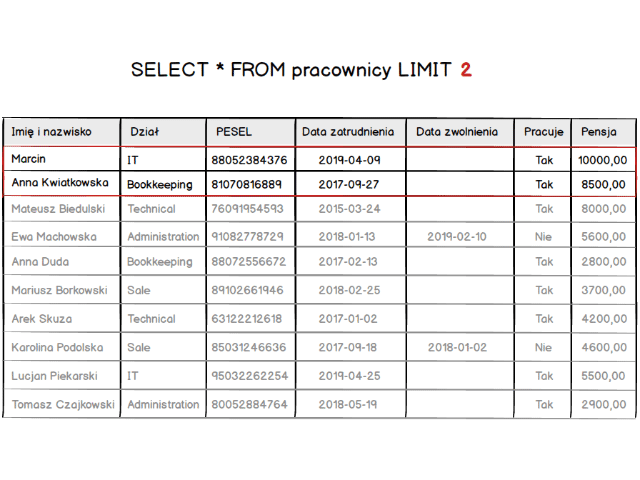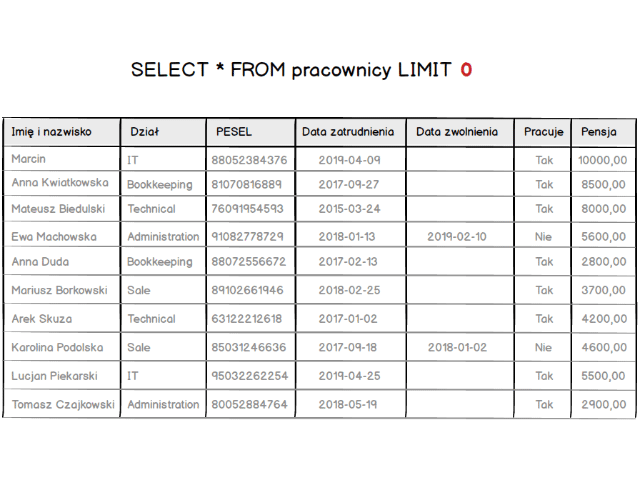
Jest już jasne że row_count, który widzieliśmy w schemacie klauzuli powoduje ograniczenie liczby rekordów do podanej wartości. Więc teraz możemy już ograniczyć listę zwracanych rekordów. W ten sposób jesteśmy w stanie wyświetlić pierwszą stronę naszej tabeli z listą pracowników. Ale co z wyświetleniem kolejnych podstron ?? Otóż musimy przesunąć się względem początku tabeli. Do tego celu służy parametr offset. Mówi on “przesuń zwracaną listę o X rekordów”.
W praktyce wyglądało będzie to następująco.
SELECT * FROM `employees` LIMIT 5 OFFSET 2;
Co możemy przetłumaczyć na nasz język:
SELECT * FROM employees – zwróć mi rekordy z tabeli employees
LIMIT 5 – interesuje mnie tylko 5 rekordów
OFFSET 2 – interesują mnie rekordy od trzeciego rekordu
Wiem że offset może być w pierwszej chwili mylący, zwłaszcza dla osób nie przyzwyczajonych do tego, że rekordy liczymy od zera nie od 1. Dlatego pozwól, że posłużę się wizualizacją tego przypadku i jak będzie się on zmieniał, gdy zmieniała będzie się wartość offset.
Poza tym co poznaliśmy przed chwilą możliwy jest jeszcze uproszczony zapis bez słowa kluczowego OFFSET. Wynik działania będzie dokładnie ten sam.
SELECT * FROM `employees` LIMIT 5 OFFSET 2;
Wersja krótsza.
SELECT * FROM `employees` LIMIT 2, 5;
Na początku zachęcam do używania wersji ze słowem kluczowym OFFSET. Lepiej będzie widać jakie wartości podstawiliśmy pod poszczególne parametry.
Klauzula WHERE
Ograniczanie listy rekordów przez klauzulę LIMIT jest bardzo przydatne. Jednak nie pozwoli ono na zawężenie listy pracowników do konkretnej osoby, na przykład posiadającej określony numer PESEL. Do tego celu służy klauzula WHERE.
SELECT
select_expr [, select_expr ...]
FROM
tbl_name
[WHERE where_condition]
Powyższy zapis rzuca pewne światło, jak powinno wyglądać zapytanie z klauzulą WHERE. Pozostaje jedynie wyjaśnić, co kryje się pod where_condition ?? I tu mam mały problem, bo jest ogrom możliwości, a nie chciałbym nikogo przestraszyć 😉 Dlatego skupimy się na ograniczeniach biorących pod uwagę wartości znajdujące się w kolumnach. Zanim przejdziemy do pisania pierwszych zapytań, musimy poznać operatory porównania.
Operatory porównania
Mniejsze niż < pozwala na sprawdzenie czy jakaś wartość jest mniejsza niż inna. W naszym przypadku sprawdzimy kto zarabia mniej niż 3700 zł.
SELECT * FROM `employees` WHERE `salary` < 3700;
W rezultacie powinniśmy otrzymać poniższą listę rekordów.

Naturalnym rozwinięciem będzie operator najwyżej (lub inaczej, mniejsze równe) <=. Pozostając przy poprzednim przykładzie, chcemy się dowiedzieć kto zarabia mniej niż 3700 zł, ale także równo 3700 zł.
SELECT * FROM `employees` WHERE `salary` <= 3700;
I tutaj wynik jest niemal identyczny jak poprzednio. Pojawił się dodatkowy rekord, który jest równy 3700 zł.

Równy = pozwala na wyszukanie tylko rekordów, gdzie wartość jest dokładnie taka jak podaliśmy z prawej strony operatora. Pozostając w konwencji, sprawdźmy kto zarabia dokładnie 3700 zł.
SELECT * FROM `employees` WHERE `salary` = 3700;

I została nam zwrócona lista rekordów spełniających nasz warunek. Oczywiście nie tylko liczby możemy porównywać. Możemy poprosić o listę pracowników pracujących w dziale sprzedaży.
SELECT * FROM `employees` WHERE `department` = "Sale";

Kolejny operator to większy niż >, i dzięki niemu za chwilę dowiemy się kto zarabia ponad 3700 zł.
SELECT * FROM `employees` WHERE `salary` > 3700;
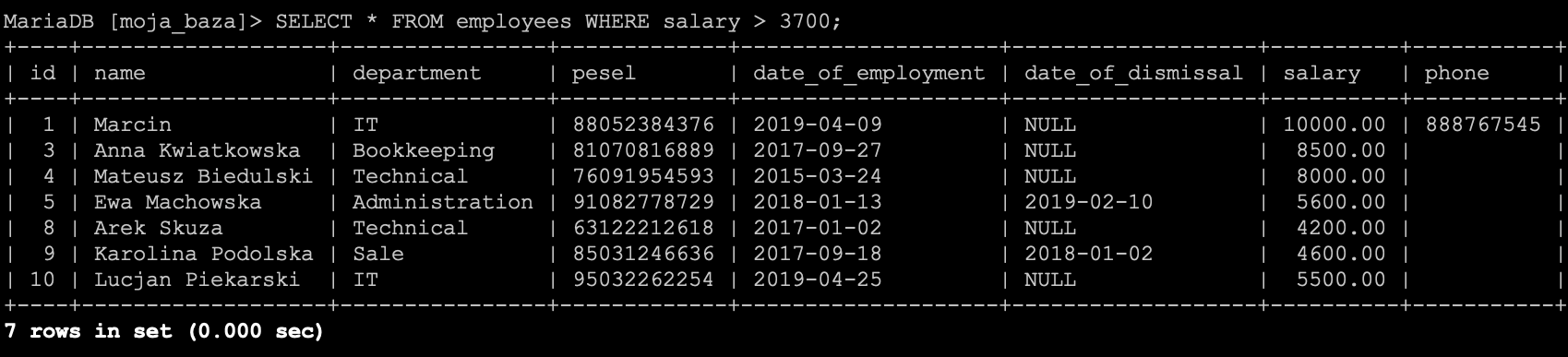
Analogicznie jak w przypadku operatora mniejszy niż, tutaj także mamy rozwinięcie w postaci operatora przynajmniej (równy lub większy) >=.
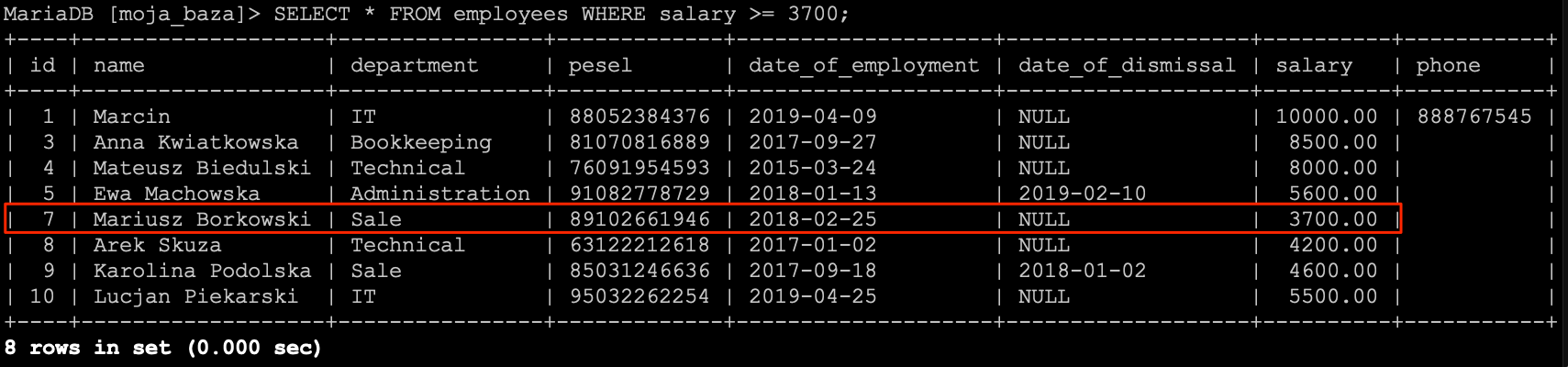
SELECT * FROM `employees` WHERE `salary` >= 3700;
Zostanie nam zwrócona lista na której znajdzie się osoba zarabiająca równo 3000 zł oraz wszystkie osoby zarabiające więcej niż podana kwota.
Ostatni operator to nierówne <>. I pewnie już wiecie jak on działa 😉 Dla urozmaicenia wykluczymy z listy rekordów dział IT.
SELECT * FROM `employees` WHERE `department` <> "IT";

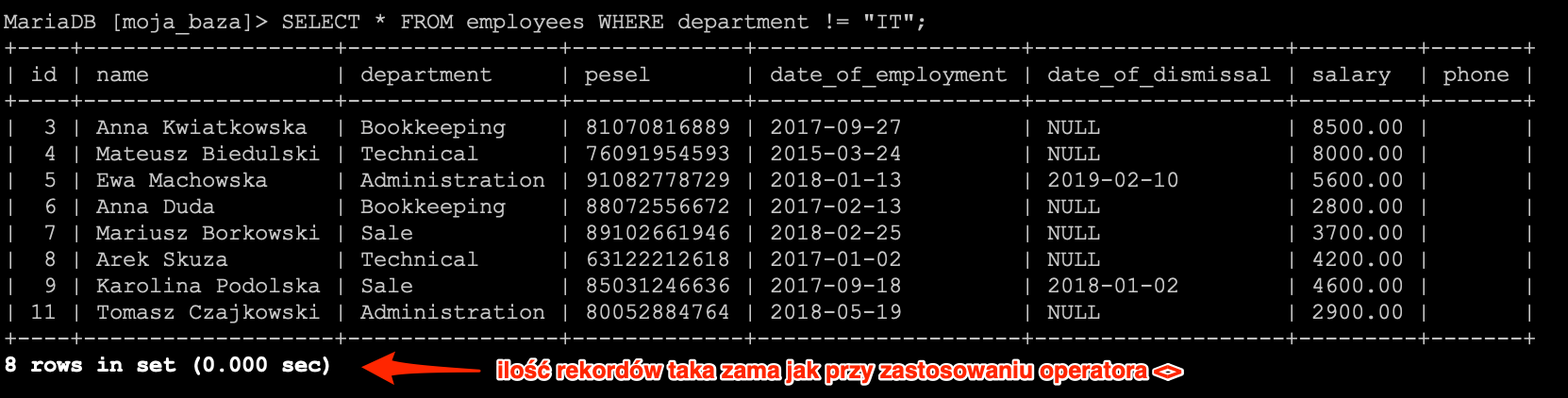
Rzeczywiście na liście nie znajdziemy żadnej osoby z działu IT. W starszych implementacjach SQL-a możecie się spotkać z operatorem !=, który także zadziała i zwróci poprawną listę rekordów.
SELECT * FROM `employees` WHERE `department` != "IT";
Mimo tego, że operator działa trzymajmy się operatora <>, który możemy spotkać w większości implementacji SQL-a.
Operatory obsługujące NULL
Operator równości daje nam możliwość wyszukania rekordów, które w określonej kolumnie posiadają określoną wartość. Od każdej reguły znajdziemy pewne odstępstwa i w tym przypadku także takie istnieje. Jest nim wyszukiwanie rekordów, gdzie chcemy wyszukać rekordy posiadające w określonej kolumnie wartość NULL.
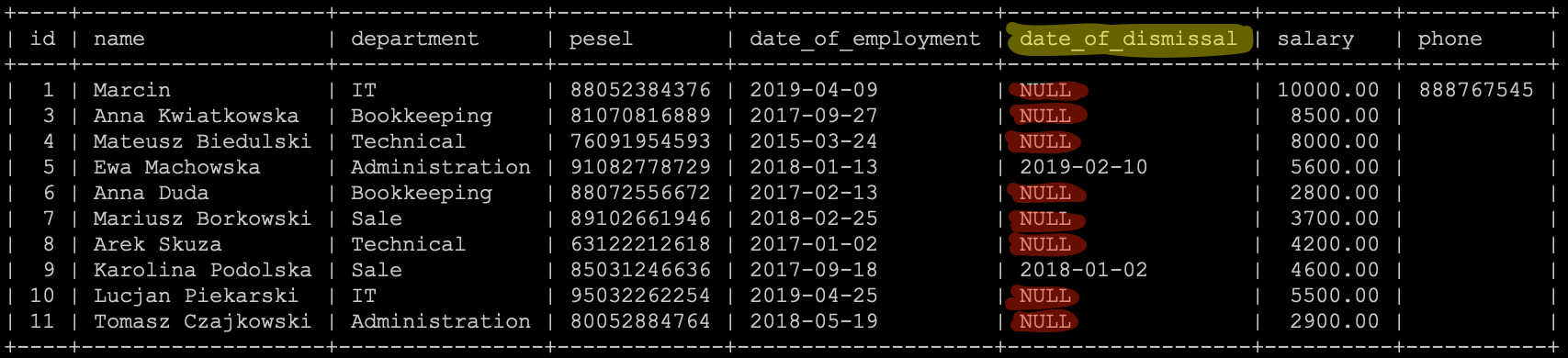
Na liście pracowników widać, że w kolumnie date_of_dismissal mamy wartości NULL. I teraz chcielibyśmy ograniczyć listę rekordów do tych, które w kolumnie date_of_dismissal mają wartość NULL. Wydawać się może, że wystarczy użyć operatora równości i otrzymamy listę rekordów.
SELECT * FROM `employees` WHERE `date_of_dismissal` = NULL;
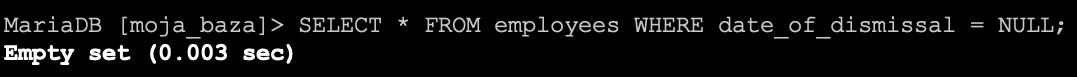
Niestety tak się nie stało. Wynika to z faktu, że NULL jest specjalną wartością i nie da się jej tak po prostu przyrównać. Dlatego zostały dodane dwa operatory dzięki którym możemy określać czy wartość jest NULL, czy też nie.
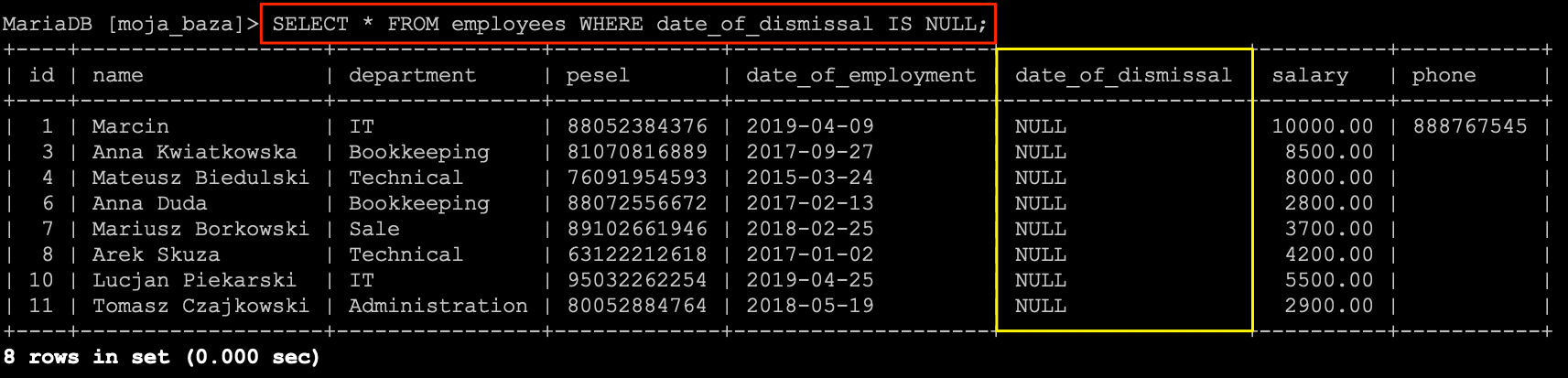
Zacznijmy od pierwszej opcji, czyli chcemy otrzymać rekordy posiadające wartość NULL w kolumnie date_of_dismissal. Do tego celu użyjemy operatora IS NULL.
SELECT * FROM `employees` WHERE `date_of_dismissal` IS NULL;
A teraz odwróćmy sytuację i ograniczmy listę rekordów do takich, które nie mają wartości NULL. W takim przypadku musimy posłużyć się operatorem IS NOT NULL.
SELECT * FROM `employees` WHERE `date_of_dismissal` IS NOT NULL;

Po wykonaniu zapytania na liście pozostały tylko te rekordy, które nie miały NULL-a w kolumnie date_of_dismissal.
Operatory LIKE
Ciekawym operatorem, który koniecznie trzeba znać jest operator LIKE. Pozwala on na przeszukiwanie tekstu pod kątem wystąpienia określonego wzorca. Już tłumaczę co to dokładnie oznacza.
SELECT * FROM `employees` WHERE `name` LIKE 'Marcin';
Powyższe zapytanie ma za zadanie znaleźć wszystkich pracowników, który w kolumnie name mają wartość Marcin.

Widzimy że wynik jest zgodny z oczekiwaniami. I jest to równoznaczne z zapytaniem, gdzie mieli byśmy warunek WHERE name = 'Marcin'.
SELECT * FROM `employees` WHERE `name` = 'Marcin';

Skoro oba zapytania są dają nam taki sam wynik, to po co nam LIKE ?? Operator ten bez połączenia z dodatkowymi znakami specjalnymi traci swą magię.
Mamy dwa znaki specjalne:
%dopasowuje dowolną ilość znaków,_dopasowuje pojedynczy znak
Wiedząc już jakie znaki specjalne możemy użyć, zobaczmy jak wyszukać wszystkie Anie. Zwykłe porównanie się tutaj nie sprawdzi, gdyż każda Ania ma wpisane nazwisko.
SELECT * FROM `employees` WHERE `name` LIKE 'Anna%';

Co jednak gdybym chcieli wyszukać pracownika po nazwisku np. Kwiatkowska ?? Zdefiniowany wzorzec Anna% oznacza, że ciąg znaków ma rozpocząć się od Anna, a po nim może wystąpić cokolwiek. Jednym z rozwiązań jest umieszczenie procenta na początku %Kwiatkowska. Co oznacza, że na początku może być cokolwiek, ale musi kończyć się ciągiem znaków Kwiatkowska.
SELECT * FROM `employees` WHERE `name` LIKE '%Kwiatkowska';

Zgodnie z oczekiwaniami mamy jednego pracownika. Tylko teraz musimy wiedzieć, czy chcemy wyszukać imię czy nazwisko. A co gdyby umożliwić wyszukiwanie po imieniu i nazwisku ?? W tym celu wystarczy we wzorcu umieścić znak procenta na początku i końcu wzorca.
SELECT * FROM `employees` WHERE `name` LIKE '%Kwiatkowska%';

Zobaczmy teraz czy stosując to samo podejście znajdziemy wszystkie Anny.
SELECT * FROM `employees` WHERE `name` LIKE '%Anna%';

Mamy oczekiwane wyniki, ale ma to swoje konsekwencje. Może już się domyślasz jakie, a jeśli nie to nie szkodzi. Zaraz przeanalizujemy jeden przypadek i wszystko stanie się jasne. Załóżmy że chcemy znaleźć wszystkich szczęśliwców, którzy urodzili się w grudniu. Nie mamy daty urodzin, ale mamy PESEL, który zawiera datę urodzenia.
Numer PESEL możemy sobie rozkodować następująco RRMMDDXXXXX, gdzie poszczególne elementy oznaczają:
RRrok,MMmiesiąc,DDdzień,XXXXXto nas nie interesuje ;)
Jako że rok nas nie interesuje to pominiemy go używając znaku specjalnego %. Następnie mamy miesiąc, który ustawiamy na 12. Po miesiącu mamy dzień oraz ciąg który nas nie interesuje. Więc możemy go zastąpić także znakiem procenta %. W ten sposób otrzymaliśmy wzorzec %12%, co po podstawieniu do zapytania będzie wyglądało następująco.
SELECT * FROM employees WHERE pesel LIKE '%12%';

Wyniki są prawie dobre, ale przez to że znak procenta pozwala na dopasowanie dowolnego ciągu znaków. To spowodowało że otrzymaliśmy dane osoby, która urodziła się 12 dnia, a nie 12 miesiąca. Oczywiście przy numerze PESEL, którego struktura jest znana i stała możemy ten problem rozwiązać stosując drugi znak specjalny _.
SELECT * FROM employees WHERE pesel LIKE '__12%';

Teraz dopasowanie jest poprawne, a we wzorcu zastąpiliśmy jedynie pierwszy znak procenta. Dwoma znakami _, które zastępują pojedynczy dowolny znak.
Dla chętnych, małe zadanie ;) Jakie zapytanie wyszuka wszystkie osoby, których nazwisko zaczyna się na literę B. Odpowiedzi wrzucajcie w komentarzach.
Operatory AND / OR
Poznaliśmy już operatory porównania z których będziemy korzystali bardzo często oraz kilka innych nieco rzadziej wykorzystywanych. Pozostało nam dowiedzieć się jak możemy budować zapytania z rozbudowanymi warunkami.
Przykładem takiego zapytania może być zapytanie wyszukujące wszystkie osoby z działu sprzedaży, które nie zostały zwolnione. Mamy tutaj dwa warunki, pierwszy mówi że interesują nas wszystkie osoby z działu sprzedaży.
SELECT * FROM employees WHERE department='Sale';

Drugi warunek mówi o osobach, które jeszcze pracują w naszej firmie. Więc data zwolnienia w ich przypadku będzie NULL, a to oznacza, że samo zapytanie wyszukujące będzie wyglądało następująco.
SELECT * FROM employees WHERE date_of_dismissal IS NULL;
Teraz możemy pomyśleć jak połączyć te dwa zapytania. A jest to dziecinnie proste. Musimy w jednym zapytaniu umieścić po klauzuli WHERE nasze warunki oraz połączyć je operatorem AND lub OR w zależności od efektu jaki chcemy otrzymać. Operator AND w zapytaniu możemy zastąpić słowem i, co oznacza że możemy powiedzieć: rekord musi spełnić warunek pierwszy i drugi. Operator OR możemy zastąpić słowem lub, co da nam warunek mówiący: rekord musi spełnić warunek pierwszy lub drugi.
Wiedząc jak działają poszczególne warunki, możemy przygotować jedno zapytanie dla naszego przykładu. W zapytaniu wykorzystamy operator AND do połączenia warunków w klauzuli WHERE.
SELECT *
FROM
employees
WHERE
department='Sale' AND
date_of_dismissal IS NULL;

W wyniku działania zapytania otrzymaliśmy tylko jeden rekord. Sytuacja wyglądała by całkowicie inaczej gdybym wstawili tam operator OR. Jednak taki warunek nie miał by większego sensu, dlatego posłużę się nieco innym przykładem.
Załóżmy że chcemy wyświetlić listę osób z dwóch działów, działu IT oraz sprzedaży Sale. Nasze zapytanie będzie wykorzystywało operator OR, a samo zapytanie może wyglądać następująco.
SELECT *
FROM
employees
WHERE
department='Sale' OR
department='IT';

Mamy listę pracowników z obu działów, teraz nie stoi nic na przeszkodzie, aby dodać kolejny warunek. W którym np. usuniemy pracowników nie pracujących już w naszej firmie. Czyli teoretycznie do zapytania dodajemy warunek, który widzieliśmy już wcześniej date_of_dismissal IS NULL.
SELECT *
FROM
employees
WHERE
department='Sale' OR
department='IT' AND
date_of_dismissal IS NULL;

Niestety nie takich wyników się spodziewaliśmy. Zaznaczony rekord nie spełnia warunku date_of_dismissal IS NULL, więc pytanie dlaczego się pojawił w wynikach ?? Otóż jak w matematyce liczy się kolejność wykonywania działań. Pisząc działanie 1 + 2 + 3 wiemy że kolejność nie ma żadnego znaczenia. Gdy nieco mienimy nasze działanie 1 + 2 * 3 to wiemy, że kolejność działań ma znaczenie. W SQL-u jest bardzo podobnie, kolejność ma znaczenie. Dlatego przy stosowaniu obu operatorów w jednym zapytaniu warto umieszczać warunki w nawiasach. Zapytanie które się wykonało i zwróciło “błędy” wynik zostało by zapisane w następujący sposób.
SELECT *
FROM
employees
WHERE
department='Sale' OR
(
department='IT' AND
date_of_dismissal IS NULL
);
Nieco poprawiłem formatowanie, co powinno ułatwić czytanie zapytania. Nie ma to żadnego wpływu na poprawność jego wykonania, czy to w konsoli, czy w phpMyAdmin.

Teraz lepiej widać dlaczego mamy taką, a nie inną listę rekordów. Chcąc osiągnąć pożądany efekt konieczne jest dodanie odpowiednich nawiasów do zapytania.
SELECT *
FROM
employees
WHERE
(
department='Sale' OR
department='IT'
) AND
date_of_dismissal IS NULL;

Tym razem lista rekordów jest dokładnie taka, jaką oczekiwaliśmy otrzymać.
Modyfikacja rekordów
Zapytanie modyfikujące dane jest bardzo podobne do składni zapytania dodającego rekordy do tabeli. A dokładnie do ostatniej wersji jaką poznaliśmy.
Dla przypomnienia, dodawanie rekordów wygląda następująco.
INSERT INTO
`pracownicy`
SET
`name` = 'Marcin',
`department` = 'IT',
`pesel` = '88052384376',
`date_of_employment` = '2019-04-09',
`salary` = '10000.00',
`phone` = '888767545';
A zapytanie aktualizujące będzie wyglądało bardzo podobnie.
UPDATE
`pracownicy`
SET
`name` = 'Marcin',
`department` = 'IT',
`pesel` = '88052384376',
`date_of_employment` = '2019-04-09',
`salary` = '10000.00',
`phone` = '888767545';
Oczywiście powyższe zapytanie ma bardzo dużą wadę choć jest poprawne składniowo. Tą wadą jest brak klauzuli WHERE, gdy jej nie zdefiniujemy to wszystkie rekordy w tabeli zostaną wypełnione powyższymi danymi. Dlatego wypadało by poznać składnię tego zapytania.
UPDATE tbl_name
SET col1={expr1|DEFAULT} [,col2={expr2|DEFAULT}] ...
[WHERE where_condition]
Jak widać powyżej, mamy słowo kluczowe UPDATE dzięki któremu wiadomo, że chodzi o operację aktualizacji. Następnie SET pozwala nam zdefiniować listę kolumn wraz z wartościami jakie mają zostać przypisane do kolumn. Następnie mamy możliwość określenia warunków jakie mają zostać spełnione, aby dany rekord został zaktualizowany. To właśnie robimy w klauzuli WHERE.
Chcąc, aby nasze zapytanie nie niszczyło zawartości tabeli powinniśmy dodać jakiś warunek. Najczęściej wym warunkiem będzie identyfikator rekordu.
UPDATE
`pracownicy`
SET
`name` = 'Marcin',
`department` = 'IT',
`pesel` = '88052384376',
`date_of_employment` = '2019-04-09',
`salary` = '10000.00',
`phone` = '888767545';
WHERE
`id` = 1;
I takie zapytanie spowoduje aktualizację tylko jednego rekordu o co nam chodziło od samego początku.
Usuwanie rekordów
Ostatnią operacją jaką poznamy jest usuwanie rekordów z tabeli. Do tego celu służy zapytanie typu DELETE, którego uproszczony schemat wygląda następująco.
DELETE FROM tbl_name
[WHERE where_condition]
[ORDER BY ...]
[LIMIT row_count]
Jako że już jesteśmy weteranami to wiemy, że btn_name oznacza nazwę tabeli, a wszystkie elementy ujęte w nawiasy kwadratowe są opcjonalne. W związku z czym najprostsze zapytanie będzie wyglądało następująco.
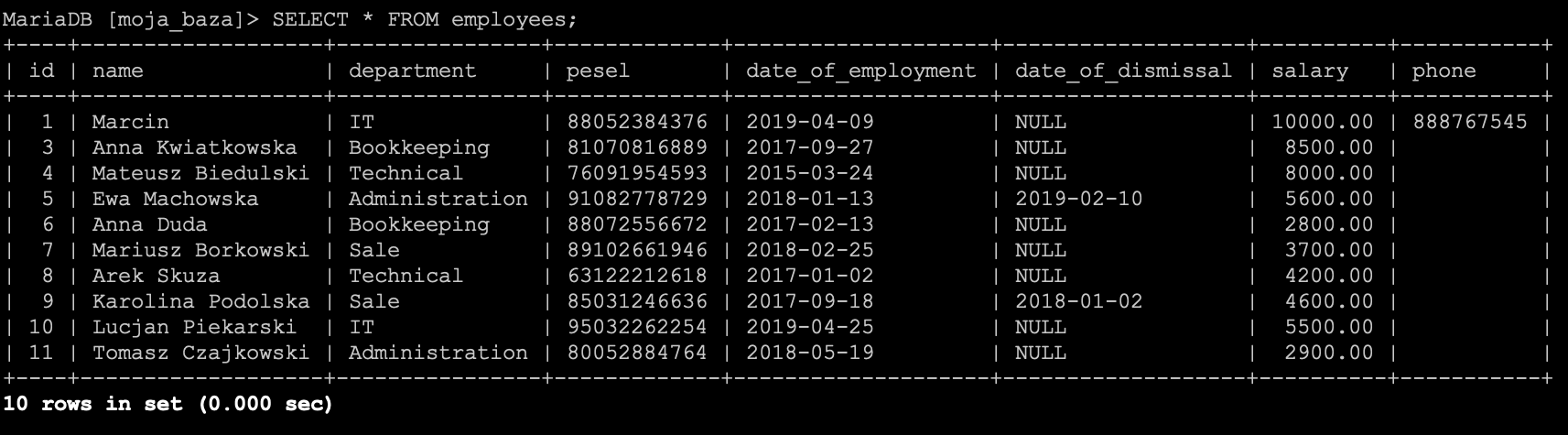
DELETE FROM `employees`;
Zanim je wykonamy musimy mieć świadomość, że takie zapytanie usunie wszystkie rekordy z podanej tabeli. A stanie się tak dlatego, że nie zdefiniowaliśmy ani klauzuli WHERE, ani klauzuli LIMIT.
Zapytanie wykonane i tabela employees jest teraz pusta. Jeśli nie chcecie wprowadzać danych ponownie, to możecie mi zaufać, że dane zostaną usunięte ;)
Takie zapytanie to rzadkość, w większości przypadków w zapytaniu będzie występowała klauzula WHERE ograniczająca listę usuwanych rekordów. Najczęściej usuwamy rekord o określonym identyfikatorze. I właśnie takie zapytanie sobie napiszemy.
DELETE FROM `employees` WHERE `id` = 1;
Zapytanie to usunie nam rekord z tabeli employees, gdzie w kolumnie id zostanie znaleziony identyfikator 1.
Możemy się bawić i rozbudowywać warunki w klauzuli WHERE, ale na ten moment nie ma to większego sensu. Niczym się one nie będą różniły od tych, które widzieliśmy w zapytaniu SELECT.
Poza klauzulą WHERE w zapytaniu DELETE mamy do dyspozycji klauzulę LIMIT. Można wykorzystać ją dwojako. Pierwsza opcja to dodatkowe zabezpieczenie, przed usunięciem zbyt dużej liczby rekordów. Czyli w naszym poprzednim zapytaniu, usuwającym pracownika o określonym identyfikatorze, mogli byśmy dodać klauzulę LIMIT mówiącą, że maksymalnie może zostać usunięty jeden rekord. Zmodyfikowane zapytanie wyglądało by następująco.
DELETE FROM employees WHERE id = 1 LIMIT 1;

Innym zastosowaniem jest połączenie klauzuli LIMIT z klauzulą ORDER BY. Takie połączenie daje nam możliwość usuwania określonej liczby rekordów z początku lub końca zbioru rekordów. Najprostszym przykładem może być chęć usunięcia osoby pracującej najkrócej w firmie.
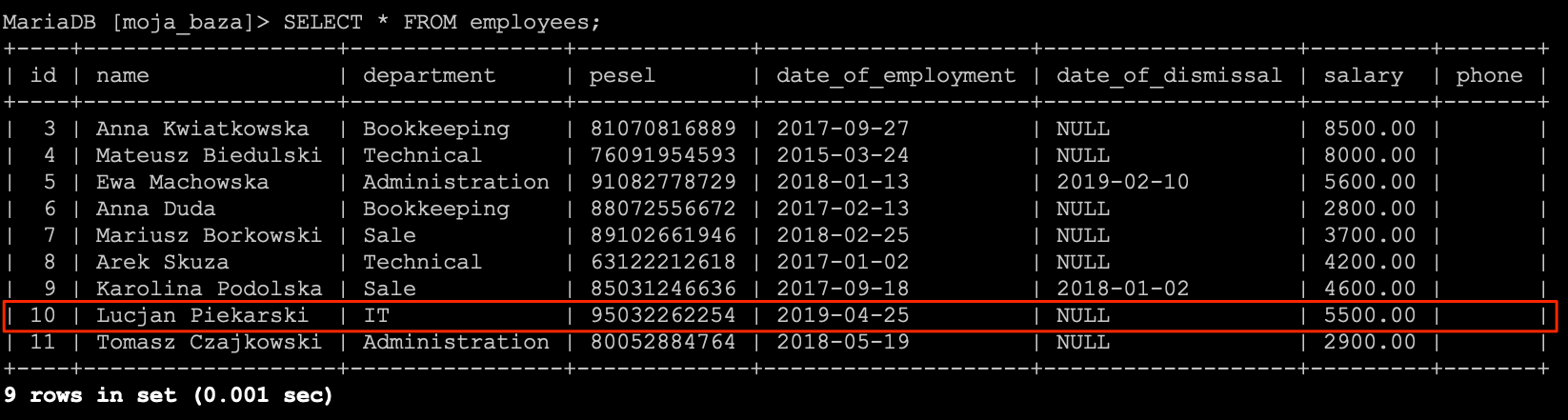
W tym celu konieczne jest przesortowanie wszystkich rekordów po kolumnie date_of_employment, a następnie usunięcie pierwszego rekordu ze zbioru.
DELETE FROM employees
ORDER BY date_of_employment DESC
LIMIT 1;

Po wykonaniu zapytania nasza lista pracowników będzie wyglądała następująco.
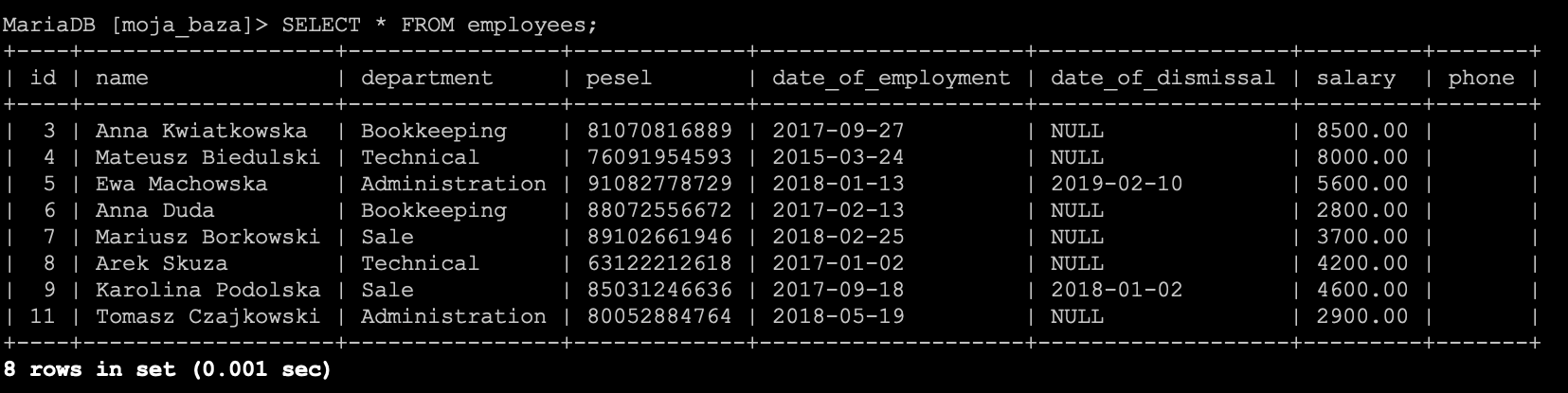
Nie znajdziemy już na niej pracownika zatrudnionego w 2019 roku. W ten sposób łącząc różne klauzule możemy usuwać różne rekordy w nieco bardziej zaawansowany sposób ;)
Funkcje
Wraz z językiem SQL zostały nam dostarczone funkcje wbudowane dzięki którym otrzymujemy całkiem nowe możliwości przetwarzania danych. Funkcje te są zaimplementowane na poziomie silnika bazodanowego i mogą się różnić w zależności od silnika na jakim pracujesz. Jednak większość podstawowych funkcji znajdziesz w każdym silniku ;)
Poniższy przegląd ma za zadanie jedynie pokazać kilka przykładowych funkcji operujących na różnych rodzajach danych. Po więcej będzie trzeba się udać do dokumentacji danego silnika bazodanowego ;)
LENGTH
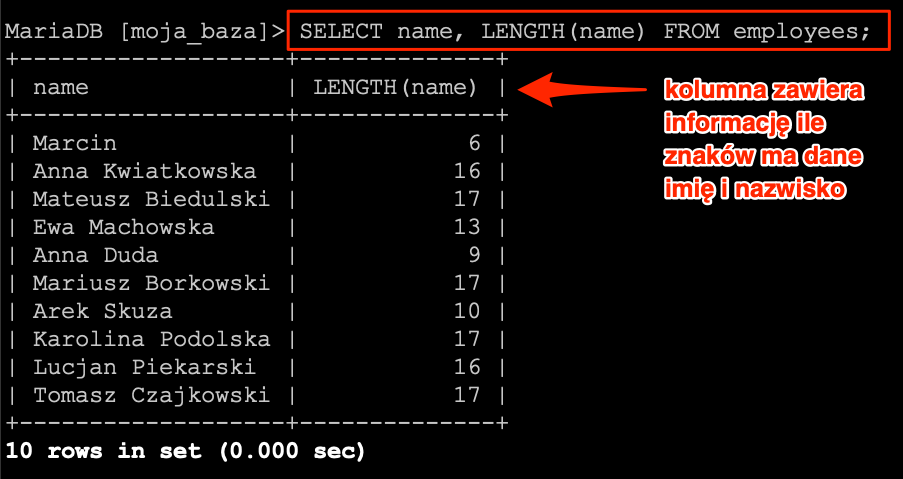
Na początek przygody z funkcjami przetestujemy bardzo prostą funkcję LENGTH, która zwraca długość łańcucha znaków.
SELECT name, LENGTH(name) FROM employees;
W rezultacie otrzymamy listę pracowników na której będzie widoczne imię i nazwisko oraz długość ciągu znaków.
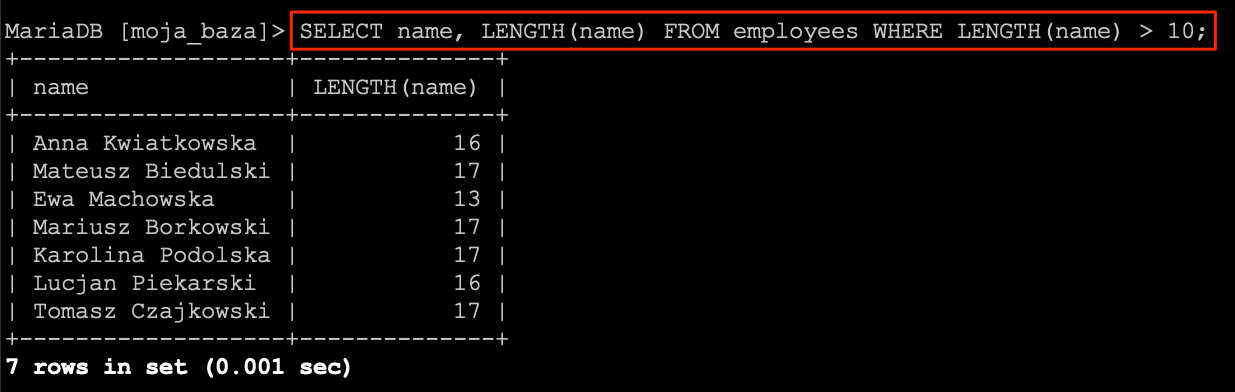
Oczywiście funkcje możemy umieszczać jako warunek w naszych zapytaniach. Co pozwala nam znacznie rozbudować możliwości samych zapytań.
SELECT
name,
LENGTH(name)
FROM
employees
WHERE
LENGTH(name) > 10;
CONCAT
Łączenie tekstu jest dość przydatną funkcją, gdy chcemy połączyć dane z kilku kolumn. Jako, że w naszej tabeli nie mamy zbyt dużo kolumn, które po połączeniu miały jakiś większy sens to pozostaje nam połączyć imię i nazwisko oraz dział w jakim pracuje osoba.
Zasada użycia jest bardzo prosta, w nawiasach klamrowych funkcji CONCAT umieszczamy nazwy kolumn lub dowolne wyrażenie w tym tekst.
SELECT
name,
department,
CONCAT(name, " - ", department)
FROM
employees
LIMIT 1;
Samo zapytanie jest bardzo proste i sprowadza się do wyświetlenia kolumny name, department oraz rezultatu połączenia tych dwóch kolumn. Przy czym został dodany separator pomiędzy tymi danymi w postaci myślnika, przed którym znajduje się spacja. A także po nim też znajdziemy spację. Dodatkowo lista wyników została ograniczona tylko do jednego rekordu.

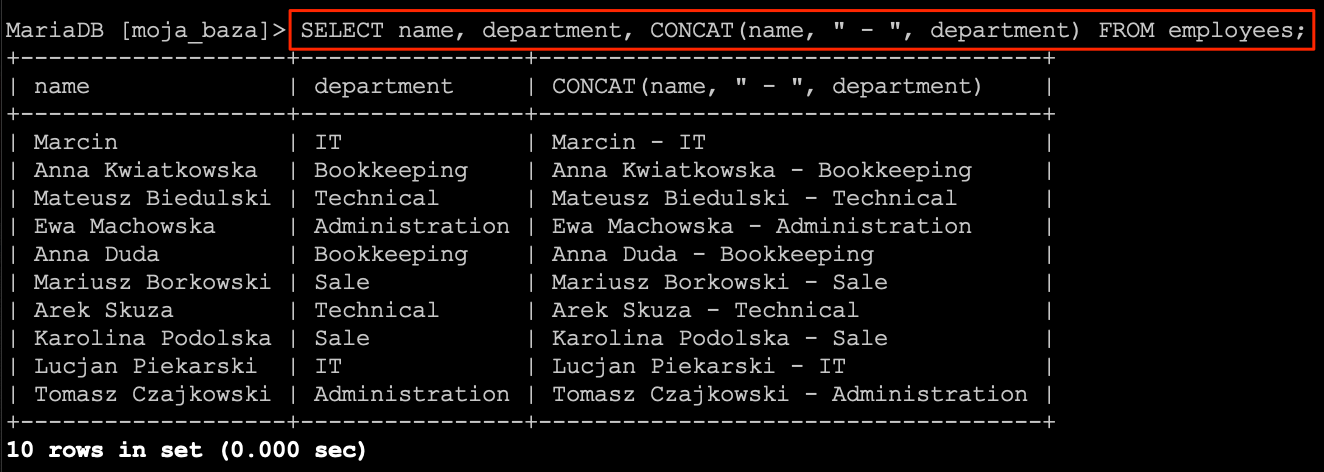
Wynik działania zapytania mam nadzieję nie jest dla nikogo zaskoczeniem. Zobaczmy zapytanie bez ograniczania listy rekordów.
SELECT
name,
department,
CONCAT(name, " - ", department)
FROM
employees;
Mamy wyniki, a teraz zaszalejmy i połączmy tę funkcję z poprzednią. Gdyż funkcja może przyjmować wynik działania innej funkcji. Więc możliwe jest ich zagnieżdżanie 😉
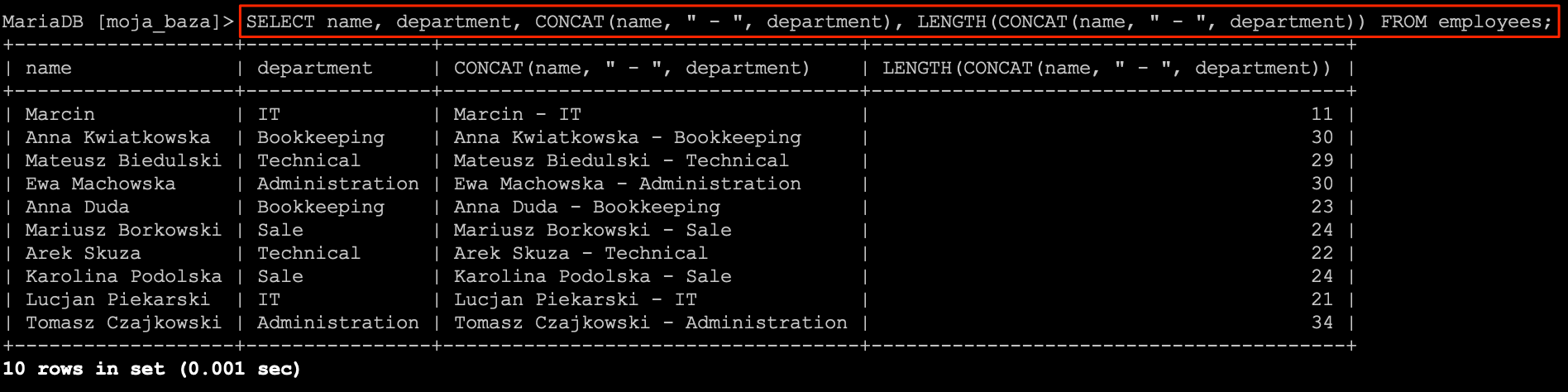
W praktyce wygląda to następująco.
SELECT
name,
department,
CONCAT(name, " - ", department),
LENGTH(CONCAT(name, " - ", department))
FROM
employees;
Funkcja LENGTH przyjmuje rezultat działania funkcji CONCAT i dla tego wyniku wykonuje obliczenie.
Poza brzydkimi nazwami kolumn, które możemy zmienić dzięki aliasom wszystko wygląda dokładnie tak jak powinno. Teraz jedynie musimy poznać odpowiednią ilość funkcji, aby wykonywać bardziej złożone operacje na danych.
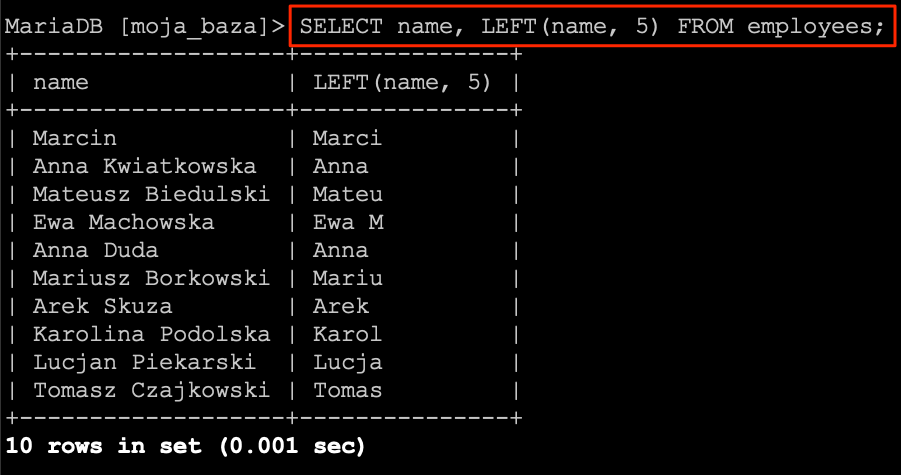
LEFT
LEFT jest kolejną funkcją operującą na tekście. Jej zadaniem jest zwrócenie określoną ilość znaków z lewej strony ciągu znaków.
SELECT
`name`,
LEFT(`name`, 5)
FROM
`employees`;
Zapewne się domyślacie, że mamy też funkcję RIGHT, ale wybaczcie. Nie będę prezentował jak działa ;)
SUBSTRING
Kolejna funkcja pozwalająca na cięcie ciągów znaków. Tym razem mamy pełną dowolność, ponieważ funkcja jako parametry przyjmuje od którego miejsca zacząć i ile znaków wyciąć. Więc możemy dzięki niej osiągnąć dokładnie to samo co w przypadku funkcji RIGHT i LEFT.
SUBSTRING(string, start, length)
Użycie w praktyce będzie wyglądało następująco.
SELECT
`name`,
SUBSTRING(`name`, 2, 5)
FROM
`employees`;
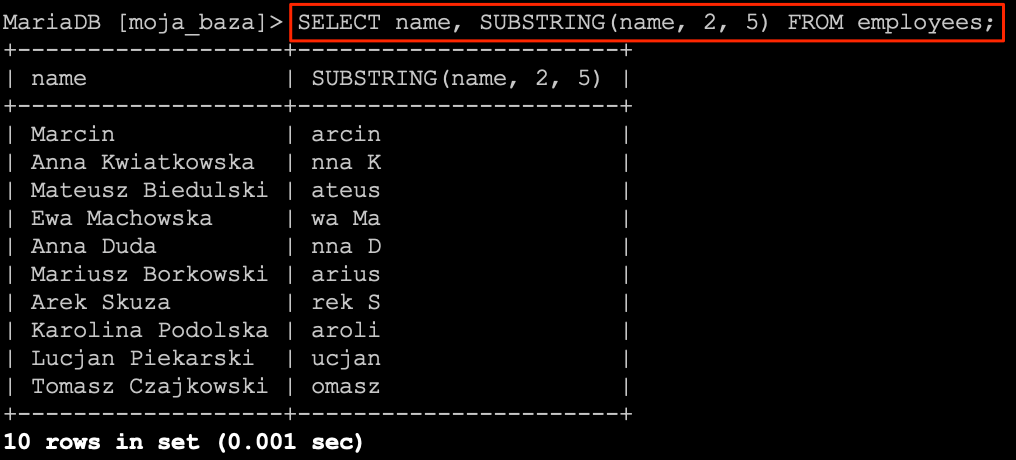
Dość jednoznacznie widać, że zaczęliśmy od drugiego znaku i wycięliśmy pięć znaków z kolumny name.
Funkcja ta występuje także pod nazwą MID oraz SUBSTR.
REPLACE
Ostatnią funkcją operującą na ciągach znaków będzie funkcja umożliwiająca zastępowanie tekstów. Przydatna, gdy musimy podmienić jakiś tekst na inny, a nie chcemy edytować kilkudziesięciu rekordów przez jakiś panel.
SELECT
`name`,
REPLACE(`name`, "Marcin", "Marcin Lewandowski")
FROM
`employees`;
Powyższe zapytanie zastąpi każde wystąpienie słowa Marcin tekstem Marcin Lewandowski. Co w tym konkretnym przypadku nie niesie ze sobą żadnych negatywnych konsekwencji.
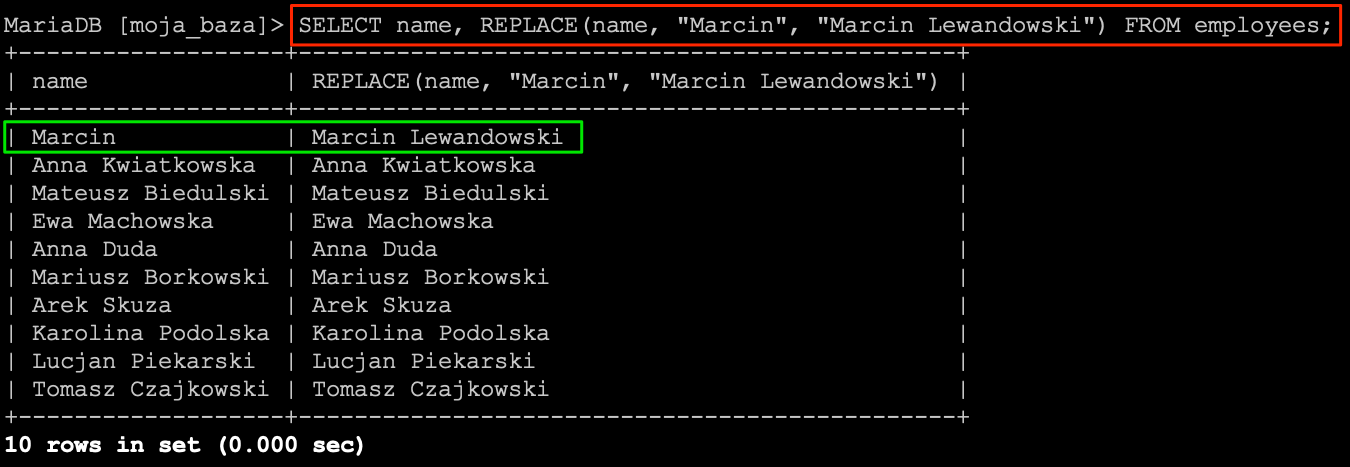
Gdybym wykonywali aktualizację, to został by zaktualizowany jeden rekord. Jednak zmiana imienia Anna mogło by już nieść poważniejsze konsekwencje. Zwłaszcza, że operacji aktualizacji od tak nie cofniemy.
DATE_FORMAT
Formatowanie daty jest jedną z częściej używanych funkcji przy operacjach na dacie. I jest to w pełni zrozumiałe, każdy z nas może oczekiwać, że data zostanie sformatowana w inny sposób. Osobiście jestem zwolennikiem formatowania na poziomie aplikacji, a nie bazy danych. Jednak bardzo często pisząc zapytania bezpośrednio na bazie chcę mieć nieco przyjaźniejsze formatowanie tych danych. Do tego konieczne jest opanowanie funkcji DATE_FORMAT.
DATE_FORMAT(date, format)
Prosty przykład, chcemy dostać listę pracowników wraz z rokiem zatrudnienia.
SELECT
`name`,
`date_of_employment`,
DATE_FORMAT(`date_of_employment`, "%Y")
FROM
`employees`;
Chcąc ograniczyć liczbę wyświetlanych danych w zapytaniu pojawi się kolumna name, date_of_employment oraz rezultat formatowania daty zatrudnienia.
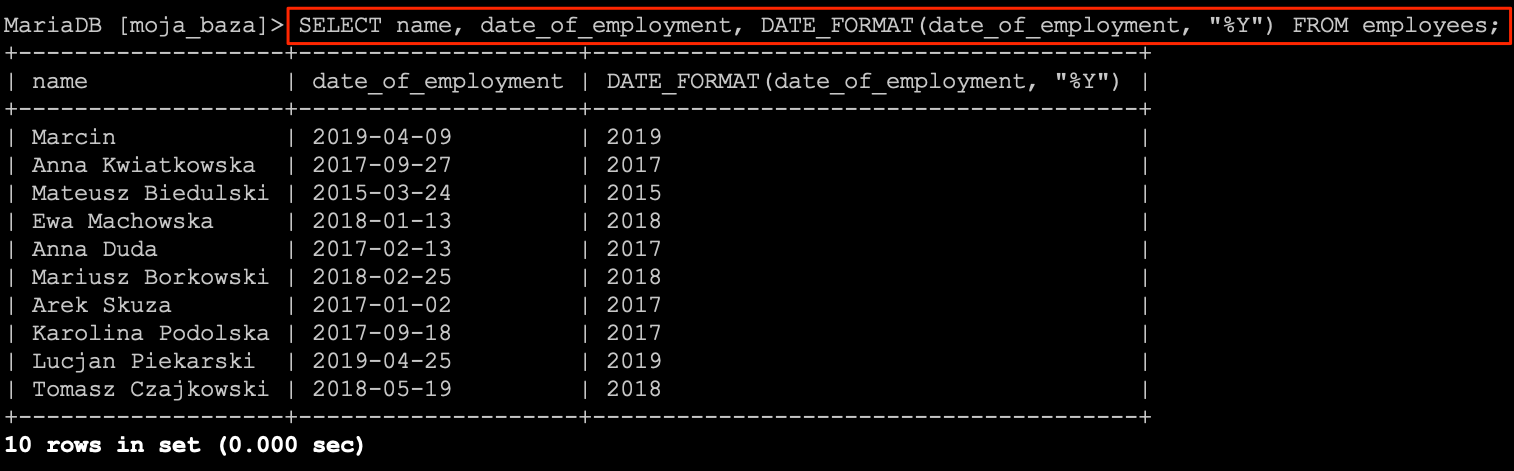
W ten prosty sposób możemy niemal dowolnie formatować datę i czas. Niestety konieczna jest znajomość odpowiednich flag, dzięki którym określamy do jakiego formatu ma zostać sprowadzona data i czas. Poniżej tabelka z dostępnymi fragami. Miłej zabawy ;)
Format Description %a Abbreviated weekday name (Sun to Sat) %b Abbreviated month name (Jan to Dec) %c Numeric month name (0 to 12) %D Day of the month as a numeric value, followed by suffix (1st, 2nd, 3rd, …) %d Day of the month as a numeric value (01 to 31) %e Day of the month as a numeric value (0 to 31) %f Microseconds (000000 to 999999) %H Hour (00 to 23) %h Hour (00 to 12) %I Hour (00 to 12) %i Minutes (00 to 59) %j Day of the year (001 to 366) %k Hour (0 to 23) %l Hour (1 to 12) %M Month name in full (January to December) %m Month name as a numeric value (00 to 12) %p AM or PM %r Time in 12 hour AM or PM format (hh:mm:ss AM/PM) %S Seconds (00 to 59) %s Seconds (00 to 59) %T Time in 24 hour format (hh:mm:ss) %U Week where Sunday is the first day of the week (00 to 53) %u Week where Monday is the first day of the week (00 to 53) %V Week where Sunday is the first day of the week (01 to 53). Used with %X %v Week where Monday is the first day of the week (01 to 53). Used with %X %W Weekday name in full (Sunday to Saturday) %w Day of the week where Sunday=0 and Saturday=6 %X Year for the week where Sunday is the first day of the week. Used with %V %x Year for the week where Monday is the first day of the week. Used with %V %Y Year as a numeric, 4-digit value %y Year as a numeric, 2-digit value
YEAR
Funkcja DATE_FORMAT jest świetna, jednak gdy chcecie wyciągnąć jedynie rok, miesiąc czy numer tygodnia można się posłużyć funkcjami dedykowanymi tylko do takiej operacji. Wracając więc do przykładu w którym wyświetlamy jedynie rok zatrudnienia danego pracownika. Możemy to zrealizować nieco prościej, wykorzystując funkcję YEAR.
SELECT
`name`,
`date_of_employment`,
YEAR(`date_of_employment`)
FROM
`employees`;
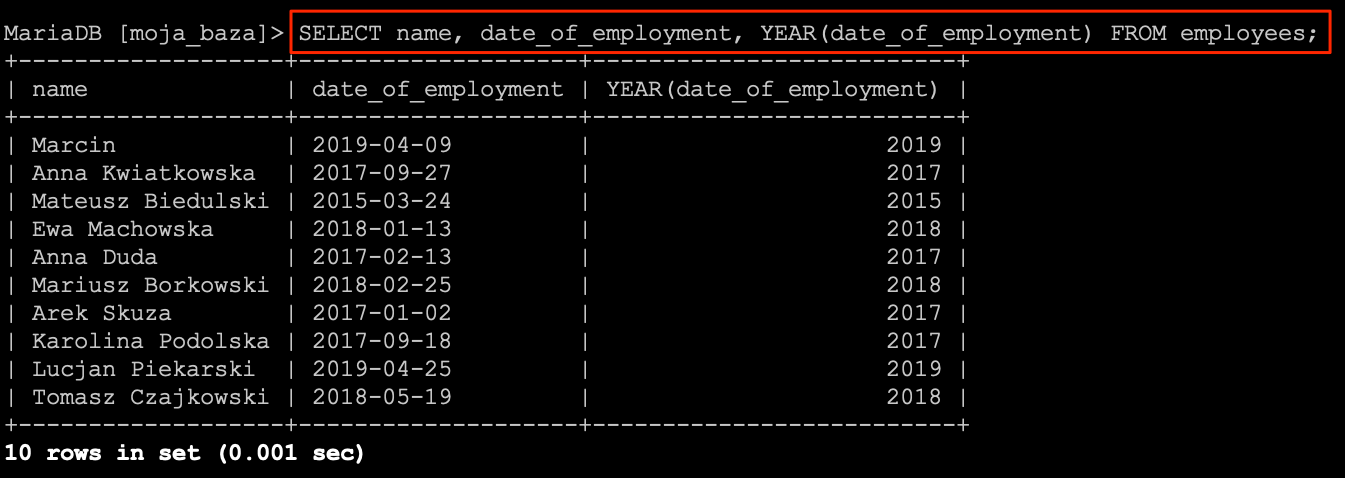
Prawda że dokładnie taki sam efekt, a dużo łatwiej zapamiętać na początku przygody z SQL-em ;)
NOW
Ostatnią funkcją operującą na czasie jest funkcja NOW, która zwraca aktualny czas. Jest ona często używana przy aktualizacji lub wstawianiu rekordów do bazy.
SELECT NOW();
Prawda że ciekawie wygląda to zapytanie SQL ?? Od razu zaznaczam, że jest w pełni poprawne i zwróci poniższy wynik.
SUM
Już sama nazwa jest wystarczającą podpowiedzią do czego ta funkcja służy. Tak, zwraca nam sumę. Pytanie tylko co chcemy zsumować. W naszym przypadku sprawa jest bardzo prosta, mamy jedną kolumnę po której sumowanie ma sens. Jest to kolumna z pensjami pracowników. Zobaczmy więc ile naszą firmę kosztują pensje pracowników.
SELECT SUM(salary) FROM employees;

I wszystko jasne ;) Mogli byśmy zacząć dodawać ograniczenia, aby sprawdzić ile kosztują nas poszczególne działy, czy chociażby wyłączyć z sumowania osoby już nie pracujące w naszej firmie.
SELECT
SUM(`salary`)
FROM
`employees`
WHERE
`date_of_dismissal` IS NULL;

Mamy sporo możliwości analizy danych kiedy zaczynamy korzystać z funkcji liczących. Jednak pełnia ich możliwości ujawnia się dopiero w połączeniu z grupowaniem o czym porozmawiamy za chwilę.
AVG
Funkcja licząca średnią z podanego zbioru.
SELECT
AVG(salary)
FROM
employees
WHERE
date_of_dismissal IS NULL;

MIN
Wyciągnięcie minimalnej wartości ze zbioru.
SELECT
MIN(`salary`)
FROM
`employees`
WHERE
`date_of_dismissal` IS NULL;

MAX
Wyciągnięcie maksymalnej wartości ze zbioru.
SELECT
MAX(`salary`)
FROM
`employees`
WHERE
`date_of_dismissal` IS NULL;

COUNT
Zliczenie ilości rekordów czyli w naszym przypadku policzenie ilu pracowników ma firma.
SELECT
COUNT(id)
FROM
employees
WHERE
date_of_dismissal IS NULL;

Inne funkcje…
Ilość funkcji jest ogromna i można nimi zrealizować większość naszych pomysłów. Tutaj pokazałem zaledwie ułamek z długiej listy dostępnych funkcji.
Gdyby okazało się, że czegoś się nie da wykonać za pomocą wbudowanych funkcji, to mamy możliwość stworzenia własnych funkcji. Tak jak możemy to robić w każdym języku programowania. Jednak jak to zrobić pokażę w osobnym wpisie, na ten moment wystarczy Ci wiedza, że jest to możliwe ;)
Grupowanie
Cześć z zaprezentowanych funkcji np. COUNT, MIN, MAX ujawniają swoją potęgę w połączeniu z grupowaniem rekordów. To dzięki grupowaniu rekordów jesteśmy w stanie jednym zapytaniem wyciągnąć informacje ilu pracowników pracuje w poszczególnych działach. Jaka jest najniższa, najwyższa czy średnia pensja w każdym dziale. A wszystko to dzięki klauzuli GROUP BY.
Zobaczmy jak to działa w praktyce, czyli policzmy ilość pracowników w każdym dziale. Do zliczenia ilości pracowników wykorzystamy funkcję COUNT oraz warunek ograniczający zbiór rekordów tylko do tych, gdzie nie została uzupełniona data odejścia WHERE date_of_dismissal IS NULL. Zagwarantuje nam to że otrzymamy tylko pracowników aktualnie zatrudnionych.
SELECT
COUNT(id)
FROM
employees
WHERE
date_of_dismissal IS NULL;
Znamy już to zapytanie. Teraz musimy je rozszerzyć o klauzulę GROUP BY. Klauzula ta występuje na końcu naszego zapytania, gdyż przed grupowaniem muszą zostać zastosowane ograniczenia zawarte w klauzuli WHERE.
SELECT
COUNT(id)
FROM
employees
WHERE
date_of_dismissal IS NULL
GROUP BY
department;
Po klauzuli GROUP BY należy podać listę kolumn po których chcemy aby nastąpiło grupowanie. Nas interesował dział dlatego mamy klauzulę wyglądającą następująco GROUP BY department. Niestety wynik może być nieczytelny.
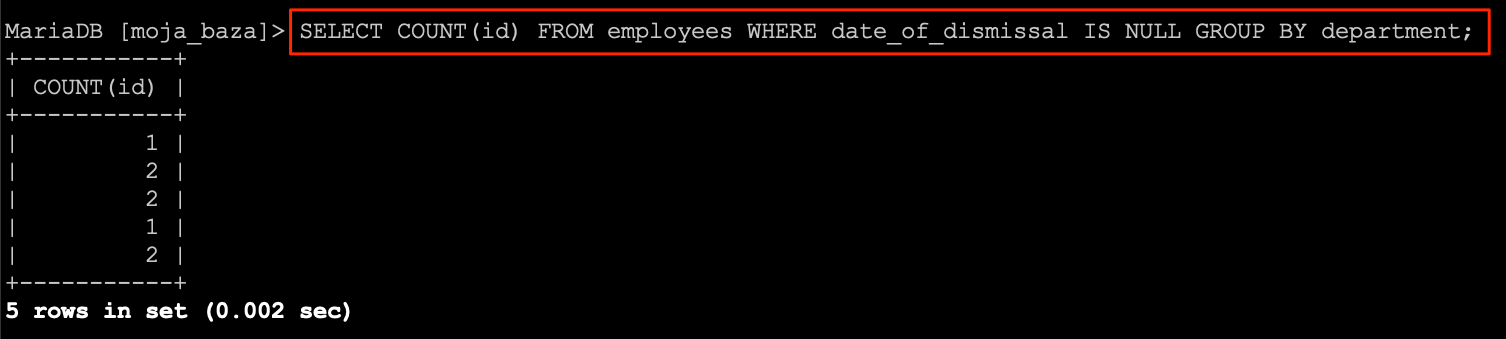
A to dlatego, że poza funkcją liczącą nie podaliśmy kolumny którą wykorzystaliśmy do grupowania. Poprawne zapytanie będzie więc wyglądało następująco.
SELECT
department,
COUNT(id)
FROM
employees
WHERE
date_of_dismissal IS NULL
GROUP BY
department;
Teraz wynik zapytania stanie się dużo bardziej czytelny.

Odpowiednio rozszerzając zapytania możemy wyciągnąć niemal każdą informację. W ramach ćwiczeń wyświetl informację jaka jest najniższa, najwyższy i średnia pensja w każdym dziale ;)
Podzapytania
Znając podstawy tworzenia zapytań i możliwości jakie dają nam funkcje w połączeniu z grupowaniem. Możemy dojść do pewnego momentu w którym nie jesteśmy w stanie jednym zapytaniem wyciągnąć wszystkich danych. Bowiem wynik jednego zapytania jest warunkiem dla drugiego.
Weźmy taki przykład. Chcemy wyświetlić wszystkich pracowników zarabiających powyżej średniej zarobków w firmie. Jednak żeby to zrobić najpierw musimy taką średnią ustalić. Dla uproszczenia pominę warunek eliminujący pracowników zwolnionych.
SELECT AVG(salary) FROM employees;

Mając średnią zarobków możemy zapisać proste zapytanie listujące pracowników zarabiających więcej niż średnia kwota.
SELECT name, salary FROM employees WHERE salary > 5580;
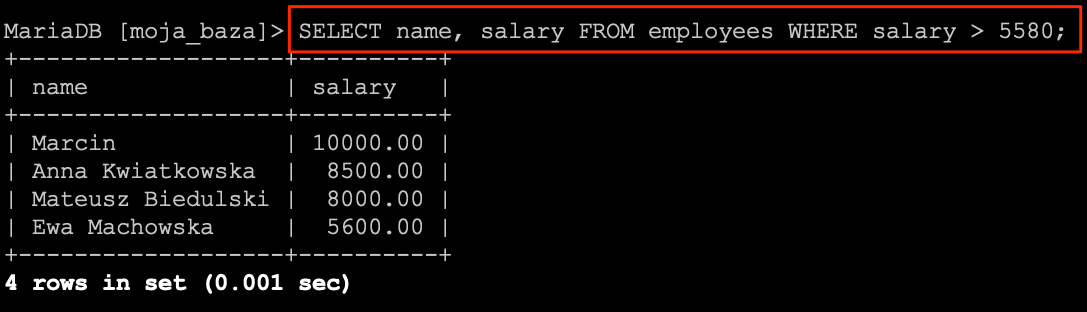
Proste i dość szybkie do zrealizowania. Ale co w przypadku, gdy zapytania będą bardziej złożone ?? Tu z pomocą przychodzą podzapytania. Czyli jedno zapytanie może dostarczać wyniki dla innego. W praktyce łączymy oba zapytania w jedno.
SELECT
name,
salary
FROM
employees
WHERE
salary > (SELECT AVG(salary) FROM employees);
Jak łatwo zauważyć zamiast kwoty, którą poprzednio wpisaliśmy ręcznie podstawiliśmy zapytanie. Bardzo ważne jest to, że nasze zapytanie ustalające średnią zarobków w firmie zostało ujęte w nawiasy. Przez co stało się podzapytaniem. I zwróciło nam odpowiedni wynik.
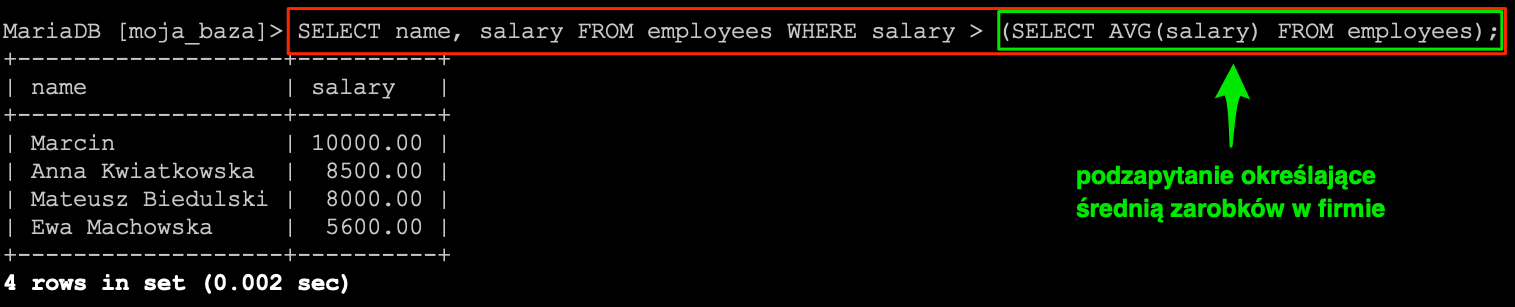
Niestety nie jest to panaceum na całe zło. Gdyż podzapytanie jest wykonywane dla każdego zwracanego rekordu :( A to oznacza utratę wydajności więc przy dużych zbiorach danych może nie być najlepszym rozwiązaniem. Ale warto znać i stosować z rozwagą.
Relacje
Siłą relacyjnych baz danych jest możliwość definiowania relacji, które odwzorowują w jakimś stopniu rzeczywistość. Dzięki czemu bardzo łatwo przychodzi nam projektowanie bazy danych. Jednak żeby to zrozumieć musimy sobie odpowiedzieć na podstawowe pytanie, czym są relacje w bazie danych ?
Czym są relacje ?
W życiu wiemy czym są relacje, każdy z nas posiada grono jakichś znajomych, rodzinę, zainteresowania. Są to naturalne relacje jakie spotkamy w życiu. A jak takie relacje przełożyć na struktury bazodanowe ??
Gdy mówimy o relacjach w kontekście relacyjnych baz danych to w 99% przypadków będziemy mówili o połączeniu pomiędzy dwoma tabelami. Spójrzmy na poniższy schemat.
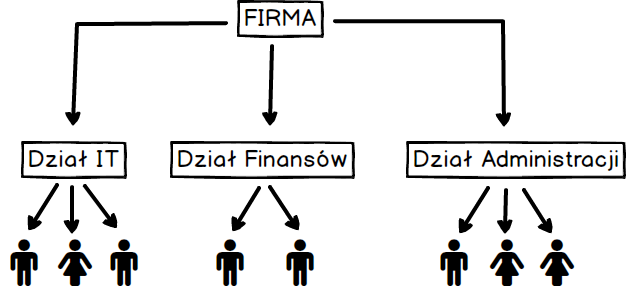
Dla wszystkich jest zrozumiałe, że w firmie mamy działy, a w tych działach pracują określone osoby. Są to relacje, które możemy w prosty sposób przełożyć na odpowiednie tabele w bazie danych.
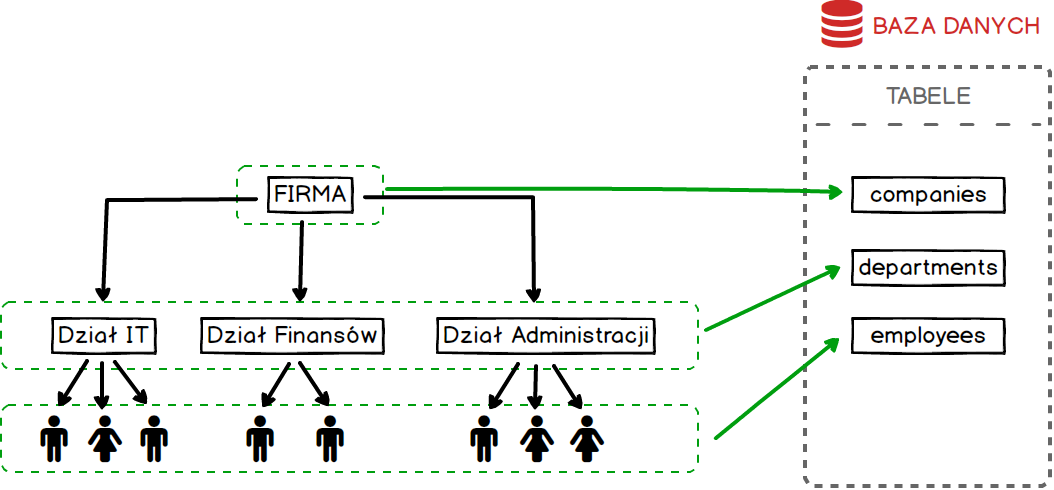
Podzieliliśmy poszczególne elementy na tabele. Pomiędzy tymi tabelami istnieją relacje, które musimy odwzorować na poziomie bazy danych. Odwzorowanie to jest bardzo proste. Mamy tabelę nadrzędną i tabelę podrzędną, w naszym przypadku tabelą nadrzędną jest tabela firmy companies, zaś tabelą podrzędną tabela działy departments
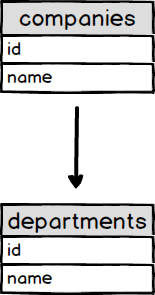
W tabeli podrzędnej konieczne jest zdefiniowanie klucza obcego, który będzie łączył rekord z tabeli podrzędnej z rekordem z tabeli nadrzędnej.
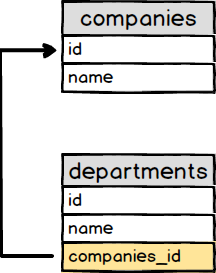
Klucz obcy w tabeli podrzędnej w większości przypadków wskazuje na klucz podstawowy tabeli nadrzędnej. Dodatkowo klucz obcy musi być dokładnie tego samego typu co klucz podstawowy oraz powinien mieć nałożony indeks.
Do dyspozycji mamy trzy rodzaje relacji:
- jeden do jednego, jednemu rekordowi w tabeli A odpowiada dokładnie jeden rekord w tabeli B,
- jeden do wielu, jednemu rekordowi w tabeli A odpowiada wiele rekordów w tabeli B,
- wiele do wielu, to tak na prawdę dwie relacje jeden do wielu z wykorzystaniem dodatkowej tabeli łączącej
Struktura naszej firmy wpisuje się idealnie w relację jeden do wielu, ale nie martw się, za chwilę przyjrzymy się wszystkim typom relacji. A także rozszerzymy naszą początkową bazę o dodatkowe tabele i zdefiniujemy pomiędzy nimi relacje.
Relacja 1:1
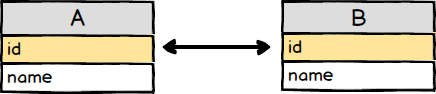
Jest to najrzadziej stosowany rodzaj relacji. A wynika to z faktu, że jednemu rekordowi z tabeli A odpowiada dokładnie jeden rekord z tabeli B. Co z praktycznego punktu widzenia oznacza, że mogli byśmy dołożyć do tabeli A dodatkowe kolumny na dane przechowywane w tabeli B.
Zastanawiacie, się pewnie dlaczego mieli byście stosować relację jeden do jeden, a nie po prostu dodać kolejne kolumny. Otóż tego typu relacje spotkacie, gdy będziecie pracowali ze słownikami. Dzięki takiemu podejściu nie będziecie musieli później jakiejś nazwy zmieniać w kilkunastu miejscach w aplikacji.
W naszym przypadku dodamy sobie prostą tabelę users przechowującą listę użytkowników mogących logować się do systemu. Naszymi użytkownikami będą nasi pracownicy to możemy połączyć ich relacją jeden do jednego.
Zaczniemy od stworzenia prostej tabeli users. Zawierającej kolumny: login – login, hasło – password.
Kod potrzebny do stworzenia tabeli będzie wyglądał następująco.
CREATE TABLE `users` (
`login` VARCHAR(255) NOT NULL ,
`password` VARCHAR(255) NOT NULL
) ENGINE = InnoDB;
Dodanie tabeli spowodowało, że mamy w bazie dwie tabele, które względem siebie powinny być w relacji.
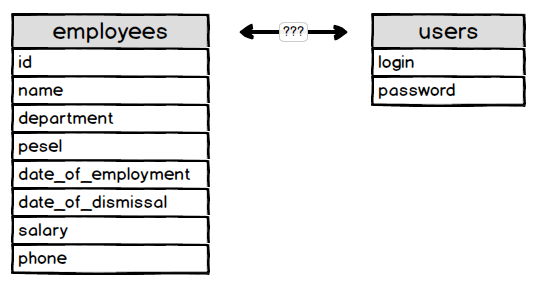
Wiemy ze wstępu, tabela podrzędna powinna zawierać klucz obcy. Jednak w przypadku relacji jeden do jednego, ciężko powiedzieć, że któraś tabela jest podrzędna w stosunku do drugiej. A to dlatego że rekord z jednej tabeli odpowiada dokładnie jednemu rekordowi z drugiej. Jednak w naszym przypadku tabela users powstała później więc to ona musi zawierać klucz obcy, który jednocześnie będzie kluczem głównym ;)
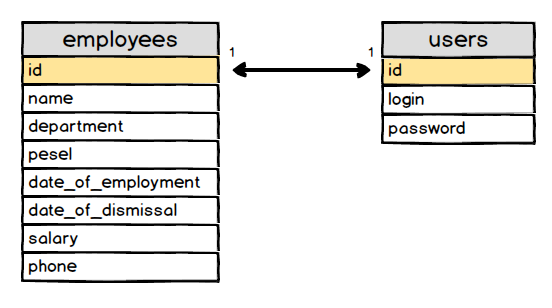
Nową kolumnę dodajemy wykonując poniższe polecenie SQL.
ALTER TABLE `users` ADD `id` INT NOT NULL FIRST, ADD PRIMARY KEY (`id`);
Teraz tylko zdefiniowanie relacji i zadanie zakończone :) Relacje definiujemy następująco.
ALTER TABLE users
ADD FOREIGN KEY (id)
REFERENCES employees(id)
ON DELETE CASCADE
ON UPDATE CASCADE;
Teraz drobne wyjaśnienie, jak definiujemy relacje. ALTER TABLE znamy i wiemy, że odpowiada za modyfikację tabeli. Modyfikujemy tabelę ponieważ to na poziomie tabeli określamy relacje względem innej tabeli. Kolejny krok to dodanie relacji FOREIGN KEY pomiędzy kluczem obcym, w tym przypadku kolumną id, a jakąś tabelą REFERENCES. U nas tą tabelą jest employees. Określając z którą tabelą będziemy tworzyli powiązanie, musimy wskazać kolumnę wiążącą.
Pozostałe parametry ON DELETE i ON UPDATE są opcjonalne i mówią tyle, że jeśli w tabeli powiązanej nastąpi usunięcie / aktualizacja rekordu to należy usunąć / zaktualizować rekord powiązany.
Pierwszy typ relacji za nami :) Czas poznać najczęściej wykorzystywany rodzaj relacji !!!
Relacja 1:wielu
Kolejny rodzaj relacji to relacja jeden do wielu. Jest to najczęściej spotykany rodzaj relacji. W tym typie relacji mamy rekordy w tabeli A, łączące się z wieloma rekordami z tabeli B.
Patrząc na naszą tabelę z pracownikami, możemy dojść do bardzo prostego wniosku. W firmie są działy, a w tych działach pracują określeni pracownicy. Jest to bardzo prosta relacja, dzięki której unikniemy błędów na poziomie wprowadzania / edycji danych. Wpisując nazwę działu z palca nie trudno o błąd ;)
Mając taką wiedzę w naturalny sposób możemy wyodrębnić listę działów i dodać ją do nowej tabeli. Nowa tabela będzie bardzo prosta. Znajdziemy w niej jedynie identyfikator działu oraz jego nazwę.

Kod potrzebny do jej wygenerowania znajdziecie poniżej.
CREATE TABLE `departments` (
`id` SMALLINT UNSIGNED NOT NULL AUTO_INCREMENT ,
`name` VARCHAR(255) NOT NULL ,
PRIMARY KEY (`id`)
) ENGINE = InnoDB;
Dodatkowo wypełnimy sobie tabelę już istniejącymi działami, wykorzystując podzapytanie.
INSERT INTO `departments`(`name`)
(SELECT DISTINCT `department` FROM `employees`);
Mając taką tabelę możemy zastąpić kolumnę z nazwami działów, kluczem obcym łączącym tabelę employees z tabelą departments. Aby zrobić to jak najbardziej bezboleśnie, to dodamy sobie nową kolumną, a gdy będziemy pewni, że wszystko przebiegło prawidłowo to usuniemy nadmiarową kolumnę z nazwą działu.
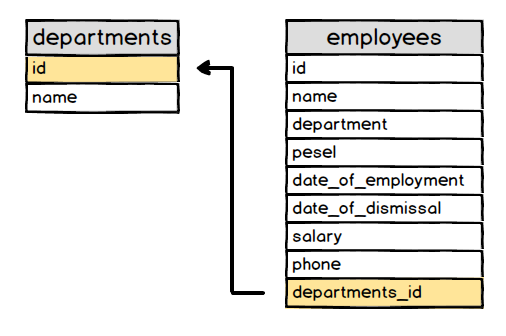
Widzimy do czego dążymy, teraz czas na kod, który pozwoli te dążenia zrealizować.
Dodajemy nową kolumnę departments_id będącą kluczem obcym tabeli. Na tym etapie musimy podjąć pierwszą ważną decyzję. Mianowicie czy możliwe jest, aby pracownik nie był przypisany do żadnego działu ?? W zależności od odpowiedzi kolumna będzie mogła przyjmować wartość NULL lub nie.
Jeśli myślisz, że przecież każdy pracownik ma swój dział to pomyśl o prezesie firmy. Do jakiego działu go przypiszesz ??
My wybierzemy bardziej uniwersalną opcję, czyli pracownik nie musi być przypisany do żadnego działu. W skrócie, wartość NULL jest dozwolona.
ALTER TABLE `employees` ADD `departments_id` SMALLINT UNSIGNED NULL AFTER `phone`;
Następnie nakładamy indeks na kolumnę będącą kluczem obcym. Każda kolumna będąca kluczem obcym powinna taki indeks posiadać.
ALTER TABLE `employees` ADD INDEX(`departments_id`);
Przed zdefiniowanie relacji ustawimy wartości dla nowo zdefiniowanego klucza obcego. W tej wersji ten krok mogli byśmy wykonać później, jednak jeśli ktoś się zdecydował na wersję gdzie każdy pracownik musi być przypisany do działu. To ten krok musi zostać wykonany przed zdefiniowanie relacji. Gdyż w innym przypadku otrzymamy błąd.
UPDATE
`employees`
SET
`departments_id` = (
SELECT
`id`
FROM
`departments`
WHERE
`departments`.`name` = `employees`.`department`
);
Po wykonaniu zapytania, nowa kolumna powinna zostać wypełniona identyfikatorami rekordów z tabeli departments.
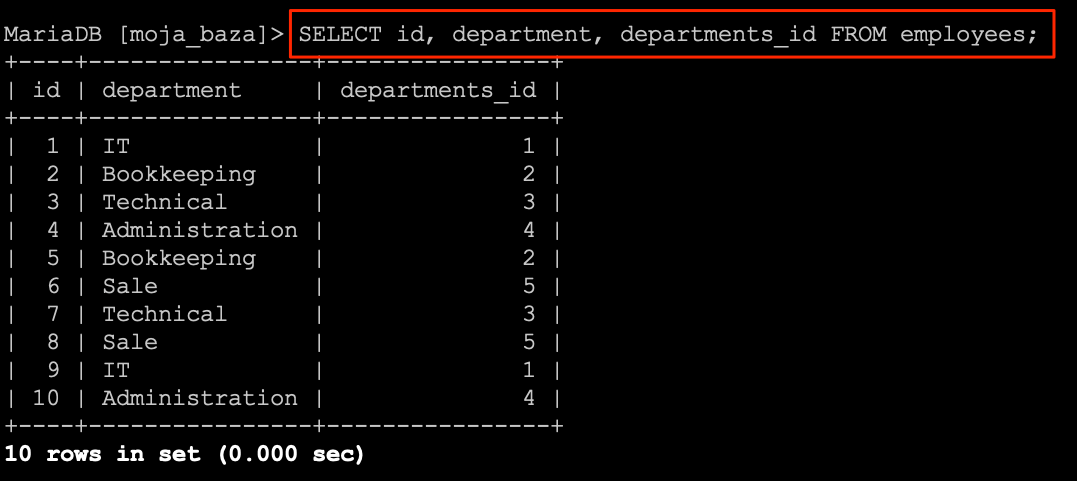
Teraz możemy zdefiniować relację pomiędzy tabelami.
ALTER TABLE `employees`
ADD FOREIGN KEY (`departments_id`)
REFERENCES `departments`(`id`)
ON DELETE CASCADE
ON UPDATE CASCADE;
Skoro wszystko gotowe to usuwamy zbędną kolumnę department.
ALTER TABLE `employees` DROP `department`;
Relacja wiele:wielu
Ostatni rodzaj relacji, jednak nie oznacza że najgorszy ;) A można wręcz powiedzieć, że najbardziej wymagający. Gdyż wymaga dodatkowej tabeli, aby go zrealizować.
Zacznijmy od początku. Załóżmy że w firmie mamy flotę samochodów. I chcemy móc w systemie przypisywać pracownikom samochody do których mają dostęp. W tym celu tworzymy tabelę przechowującą listę pojazdów cars.
CREATE TABLE `cars` (
`id` SMALLINT UNSIGNED NOT NULL AUTO_INCREMENT ,
`description` VARCHAR(255) NOT NULL ,
PRIMARY KEY (`id`)
) ENGINE = InnoDB;
Postawione wymaganie wydaje się prostą relacją jeden do wielu, jeden pracownik ma dostęp do wielu samochodów.
Powyższy projekt ma jednak ograniczenie, nie można przypisać jednego pojazdu do wielu pracowników. To może kolejna relacja, tylko w przeciwnym kierunku niż poprzednia.
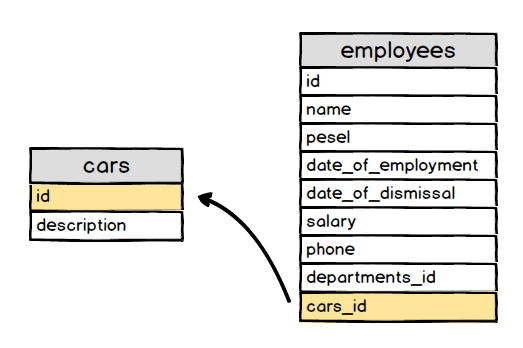
Ta relacja niestety ma ograniczenie w drugą stronę 🙁 A gdyby te dwa podejścia połączyć ?? Przecież chcemy dać możliwość przypisania dowolnej ilości pracowników do samochodów i dowolnych samochodów do pracowników 😉 Do takich celów służy relacja wiele do wielu. I tego typu relacja wymaga tabeli pośredniej.
Kod tworzący taką tabelę będzie wyglądał następująco.
CREATE TABLE `cars_employees` (
`cars_id` SMALLINT UNSIGNED NOT NULL ,
`employees_id` INT NOT NULL ,
PRIMARY KEY (`cars_id`, `employees_id`)
) ENGINE = InnoDB;
Jak zapewne zauważycie, tabela ta ma klucz podstawowy składający się z dwóch kluczy obcych. Dzięki czemu mamy zabezpieczenie na poziomie bazy danych, przed przypisaniem jednej osobie dwa razy tego samego samochodu.
Ostatni krok to zdefiniować relacje ;)
Pierwsza relacja z tabelą cars.
ALTER TABLE `cars_employees`
ADD FOREIGN KEY (`cars_id`)
REFERENCES `cars`(`id`)
ON DELETE CASCADE
ON UPDATE CASCADE;
Druga relacja z tabelą employees.
ALTER TABLE `cars_employees`
ADD FOREIGN KEY (`employees_id`)
REFERENCES `employees`(`id`)
ON DELETE CASCADE
ON UPDATE CASCADE;
I w ten oto sposób mamy stworzoną relację wiele do wielu.
Aliasy
Zanim przejdziemy do łączenia tabel na podstawie relacji konieczne jest poznanie aliasów. Aliasy pozwalają na przypisanie tabeli alternatywnej nazwy przez którą możemy się do niej odwoływać.
Zobaczmy jak wygląda proste zapytanie listujące pracowników.
SELECT * FROM `employees`;
Równoważne zapytanie do tego powyżej może wyglądać następująco.
SELECT `employees`.* FROM `employees`;
A co będzie gdy chcemy zwrócić tylko określone kolumny.
SELECT
`employees`.`id`,
`employees`.`name`
FROM
`employees`;
Zapytanie robi się coraz dłuższe i mniej czytelne, zwłaszcza gdy nie będzie ono tak ładnie sformatowane jak powyżej.
Jeśli zastanawiasz się po co używać nazwy tabeli w zapytaniach to śpieszę z odpowiedzią. W przypadku, gdy będziemy łączyli kilka tabel i będziemy chcieli wyświetlić tylko niektóre kolumny. Musimy powiedzieć, które kolumny chcemy wyświetlić i z której tabeli ;)
Alternatywą dla powyższego zapytania jest dodanie po nazwie tabeli aliasu pod którym tabela będzie dostępna. W najprostszej postaci będzie wyglądało to następująco.
SELECT * FROM `employees` AS e;
Po nazwie tabeli pojawił się operator AS, a po nim nazwa do której możemy się odwoływać. Przy czym operator AS jest opcjonalny i można go pominąć ;)
SELECT
e.id,
e.name
FROM
`employees` AS e;
Prawda że czytelniej, a dodatkowo aliasy można definiować także dla kolumn. Przykład poniżej ;)
SELECT
e.id AS employees_id,
e.name
FROM
`employees` AS e;
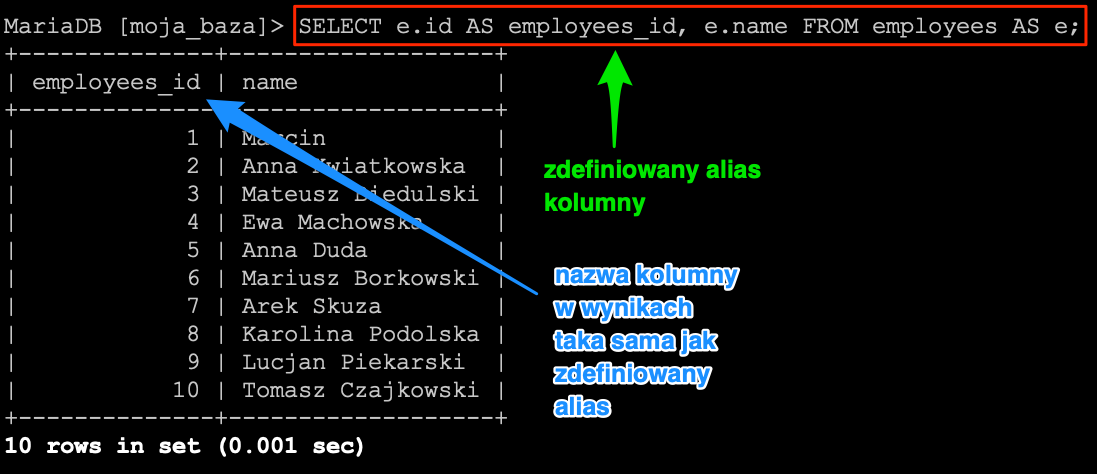
Łączenie tabel
Kiedy mamy juz relacje w naszej bazie danych to przydało by się jakoś je wykorzystać ;) Do tego celu będziemy musieli poznać kilka rodzajów złączeń tabel oraz o zgrozo czym jest iloczyn Kartezjański.
Iloczyn Kartezjański
Może zastanawiasz się, po co właściwie będę opisywał czym jest iloczyn Kartezjański we wpisie dotyczącym SQL-a ?? Otóż to właśnie iloczyn Kartezjański jest wykorzystywany w przypadku łączenia kilku tabel. I warto wiedzieć jak to się dzieje że dane z kilku tabel są łączone oraz jak to wpływa na wydajność pisanych przez nas zapytań.
Zacznijmy od teorii, no prawie teorii ;) Mamy uproszczoną tabelę z pracownikami, która wygląda następująco.
id imie
---------- ----------
1 Marcin
2 Krzysztof
3 Tomasz
Druga tabela z działami będzie wyglądała bardzo podobnie.
id nazwa
---------- ----------
6 IT
8 Sprzedaż
9 Administracja
I teraz iloczyn kartezjański to zbiór, w którym każdy wiersz pierwszej tabeli będzie połączony z każdym wierszem drugiej tabeli. A wyniku tego połączenia otrzymamy poniższy wynik.
id imie id nazwa
---------- ---------- ---------- ----------
1 Marcin 6 IT
1 Marcin 8 Sprzedaż
1 Marcin 9 Administracja
2 Krzysztof 6 IT
2 Krzysztof 8 Sprzedaż
2 Krzysztof 9 Administracja
3 Tomasz 6 IT
3 Tomasz 8 Sprzedaż
3 Tomasz 9 Administracja
Nie musimy oczywiście sami wypisywać wszystkich kombinacji bo baza może to zrobić za nas. Wystarczy zobaczyć wynik działania poniższego zapytania.
SELECT
employes.id,
employes.first_name,
departments.id,
departments.name
FROM
employes,
departments;
Teraz odpowiedź na najważniejsze pytanie. Dlaczego o tym piszę ?? Otóż w pierwszym kroku każdego złączenia wykonywany jest iloczyn kartezjański dwóch tabel. W wyniku czego powstaje wirtualna tabela i to na niej przeprowadzane jest kolejne złączenie i tak aż do wyczerpania wszystkich zdefiniowanych złączeń. Więc jak już się domyślasz jest to operacja dość kosztowna. Czym więcej złączeń tym większa tabela wirtualna powstanie w ich wyniku powstanie. I tym więcej kombinacji trzeba będzie wygenerować przy kolejnym złączeniu.
Rodzaje złączeń
Wiemy że każdy rodzaj złączeń jest oparty o iloczyn kartezjański, jednak nadal nie potrafimy wykonać żadnego złączenia. Zanim przejdziemy do samych złączeń wykonamy dwie operacje. Pierwsza to dodanie pracownika, który nie będzie przypisany do żadnego działu.
INSERT INTO `employees` (`id`, `name`, `pesel`, `date_of_employment`, `date_of_dismissal`, `salary`, `phone`, `departments_id`) VALUES (NULL, 'Tomasz', '84052384376', '2018-06-01', NULL, '15000.00', '12345678', NULL);
I druga operacja to dodanie działu, który nie będzie posiadał pracowników.
INSERT INTO `departments` (`id`, `name`) VALUES (NULL, 'HR');
Teraz możemy zacząć tworzyć zapytania ze złączeniami :D
INNER JOIN
Złączenie wewnętrzne jest rodzajem złączenia, które zwraca tylko te rekordy dla których wynik będzie spełniony.
Spójrzmy na tabelę pracowników oraz działów.
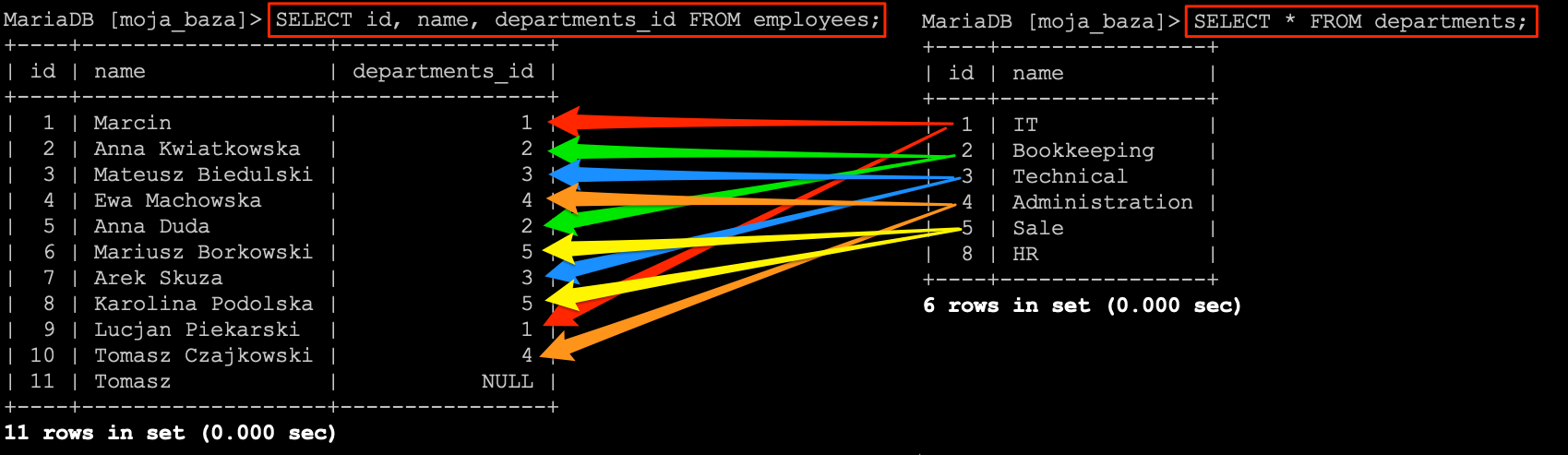
I teraz chcemy te dwie tabele połączyć, aby otrzymać nazwy działów. Dla każdego pracownika.
SELECT
e.id,
e.name,
e.departments_id,
d.id AS d_id,
d.name AS d_name
FROM
employees AS e
INNER JOIN
departments AS d ON e.departments_id = d.id;
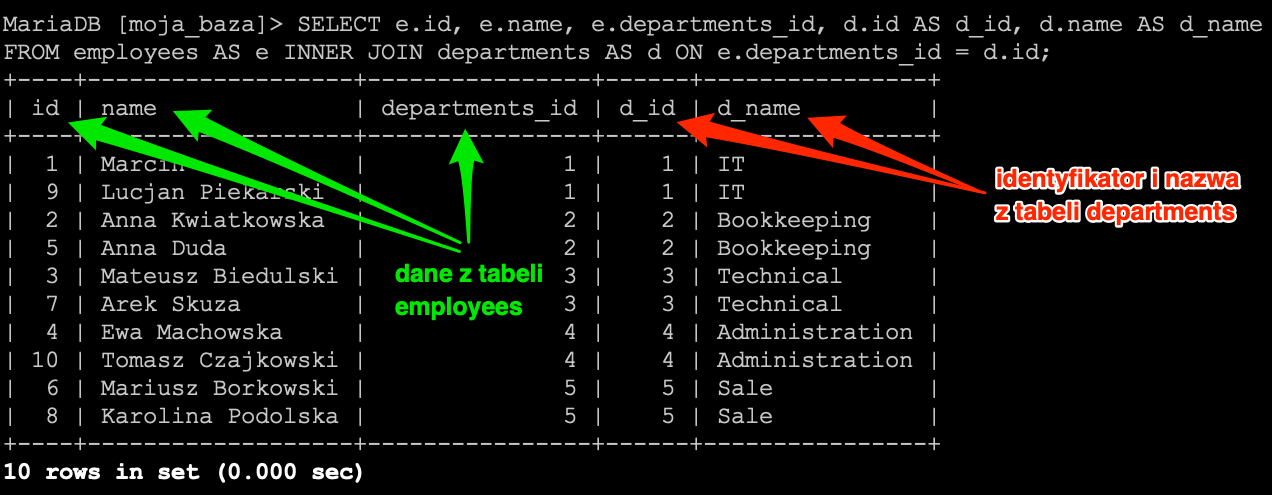
Po złączeniu widzimy, że pojawiła się nazwa działu. Jednak co się stało z pracownikami, którzy nie mieli przypisanego działu ?? Okazuje się, że nie ma ich na liście. I jest to prawidłowe zachowanie, gdyż dla pracowników warunek zawarty w ON jest nieznany, ze względu na wystąpienie NULL-a. A INNER JOIN akceptuje rekordy dla których warunek JEST spełniony.
OUTER JOIN
Drugim rodzajem złączeń są złączenia zewnętrzne. W SQL-u mamy trzy rodzaje złączeń zewnętrznych tzw. OUTER JOIN.
- LEFT OUTER JOIN
- RIGHT OUTER JOIN
- FULL OUTER JOIN
Co ciekawe w złączeniach zewnętrznych baza danych wykonuje dokładnie takie same kroki jak w przypadku złączeń wewnętrznych. Po czym wykonywany jest dodatkowy krok dopełnienia zbioru dodatkowymi rekordami zależnymi od rodzaju złączenia.
LEFT OUTER JOIN
Złączenie LEFT OUTER JOIN, czy krócej LEFT JOIN, w pierwszym kroku są wyszukane rekordy spełniające warunek. A następnie taki zbiór jest dopełniony, brakującymi rekordami z tabeli znajdującej się po LEWEJ stronie operatora JOIN.
SELECT
e.id,
e.name,
e.departments_id,
d.id AS d_id,
d.name AS d_name
FROM
employees AS e
LEFT JOIN
departments AS d ON e.departments_id = d.id;
W wyniku otrzymujemy pełną listę pracowników niezależnie czy mają przypisany dział czy nie.
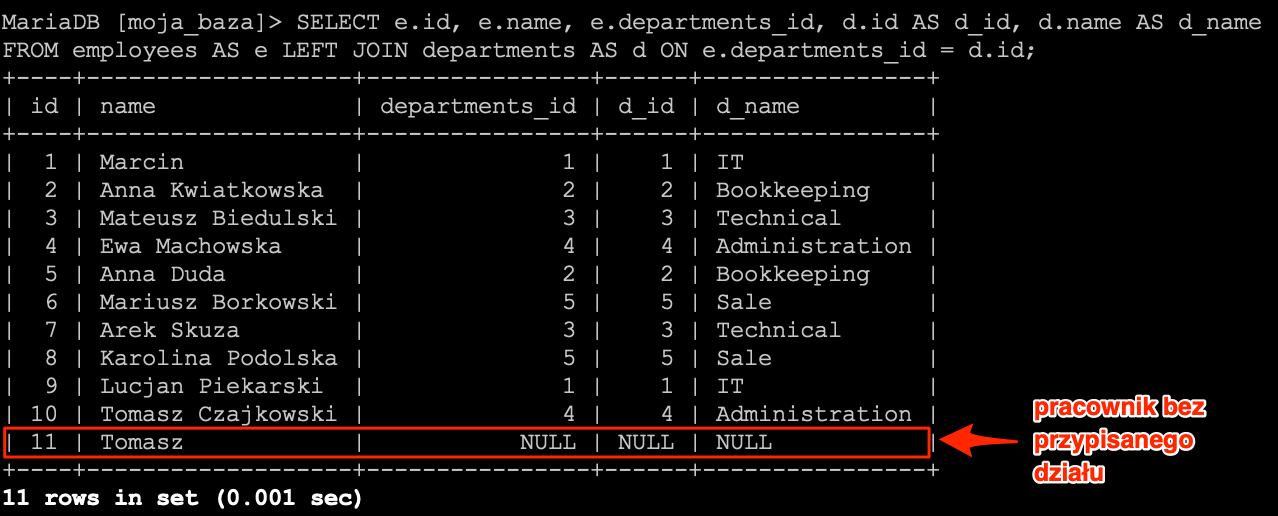
RIGHT OUTER JOIN
RIGHT JOIN jest odwrotnością złączenia LEFT JOIN. Z tą różnicą, że dopełnienie następuje z tabeli znajdującej się po PRAWEJ stronie operatora JOIN.
SELECT
e.id,
e.name,
e.departments_id,
d.id AS d_id,
d.name AS d_name
FROM
employees AS e
RIGHT JOIN
departments AS d ON e.departments_id = d.id;
W wyniku otrzymamy listę wszystkich działów niezależnie czy ktokolwiek w nim pracuje.
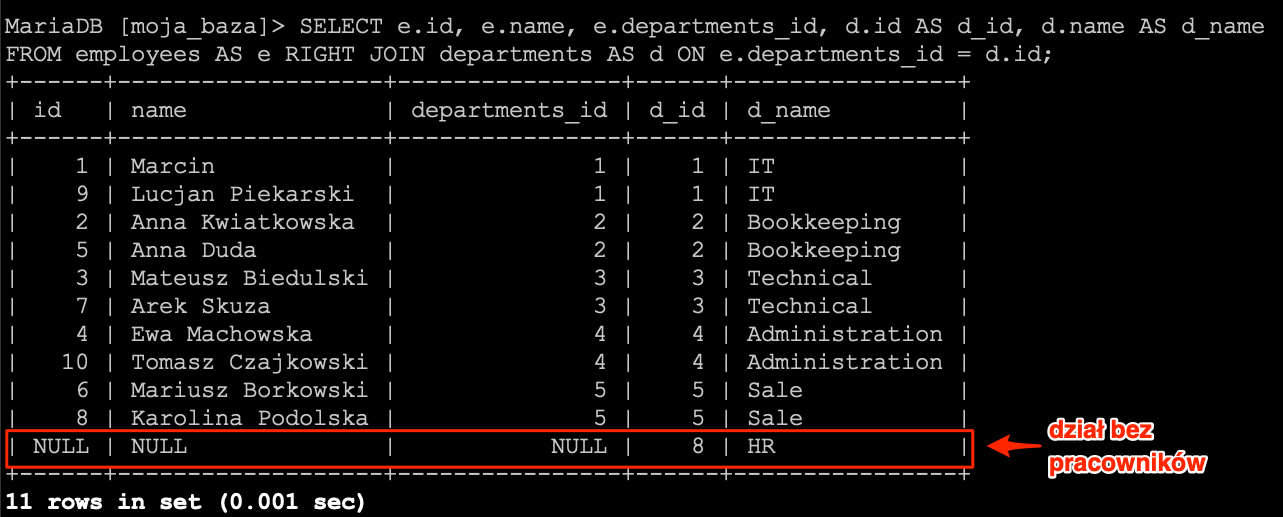
FULL OUTER JOIN
Ostatni rodzaj złączenia, czyli FULL JOIN standardowo rozpocznie od określenia zbioru spełniającego warunek, a następnie dopełni go rekordami z tabeli znajdującej się po LEWEJ i PRAWEJ stronie operatora JOIN.
Niestety MySQL i MariaDB nie wspierają tego rodzaju złączenia :( Dlatego, aby osiągnąć tego rodzaju efekt należy posłużyć się złączeniem LEFT JOIN oraz RIGHT JOIN, a następnie wyniki tych zapytań połączyć za pomocą UNION
SELECT
e.id,
e.name,
e.departments_id,
d.id AS d_id,
d.name AS d_name
FROM
employees AS e
LEFT JOIN
departments AS d ON e.departments_id = d.id
UNION
SELECT
e.id,
e.name,
e.departments_id,
d.id AS d_id,
d.name AS d_name
FROM
employees AS e
RIGHT JOIN
departments AS d ON e.departments_id = d.id;
W wyniku otrzymamy połączenie zapytania LEFT JOIN i RIGHT JOIN w jedno ;)
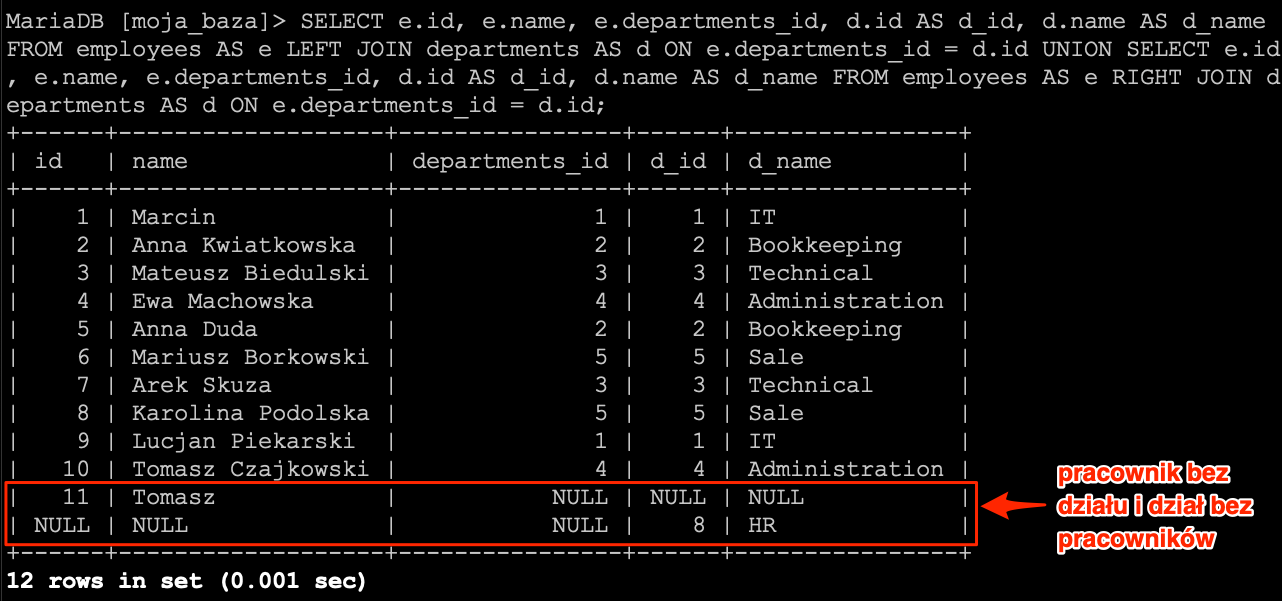
Podsumowanie
Ten wstęp do SQL-a miał za zadanie jedynie pokazać podstawy pracy z SQL-em i bazami danych. Po zapoznaniu się z treścią i zrobieniu wszystkiego co zostało pokazane w tym wpisie. Masz podstawową wiedzę, aby:
- tworzyć / modyfikować / usuwać tabelę,
- definiować relacje pomiędzy tabelami,
- pisać proste zapytania SQL,
- wykorzystywać funkcję w zapytaniach,
- dodawać podzapytania do zapytań SQL,
- wykorzystywać grupowanie w celu zliczania rekordów, wyciągania średniej lub wartości minimalnych i maksymalnych,
- i najważniejsze, pisać zapytania wykorzystujące relacje pomiędzy tabelami
Pamiętaj jednak że ta wiedza w żadnym momencie nie wyczerpuje tematu samego SQL-a, czy też baz danych. A kolejne materiały będą poszerzały tę podstawową wiedzę. Więc jeśli któryś temat Cię szczególnie interesuje to daj znać w komentarzach ;)