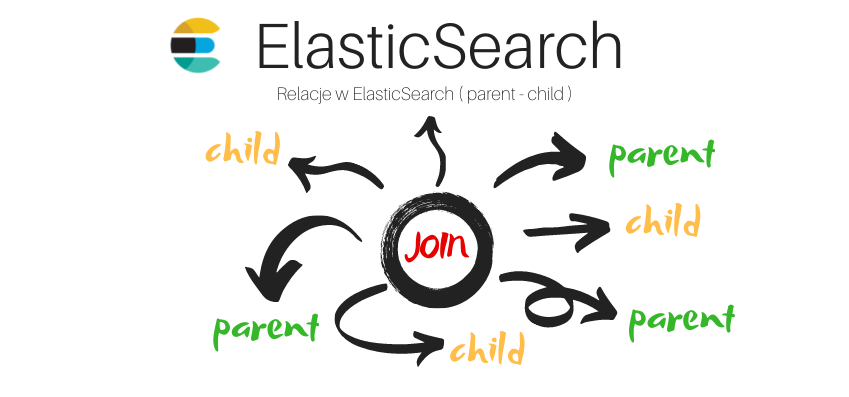
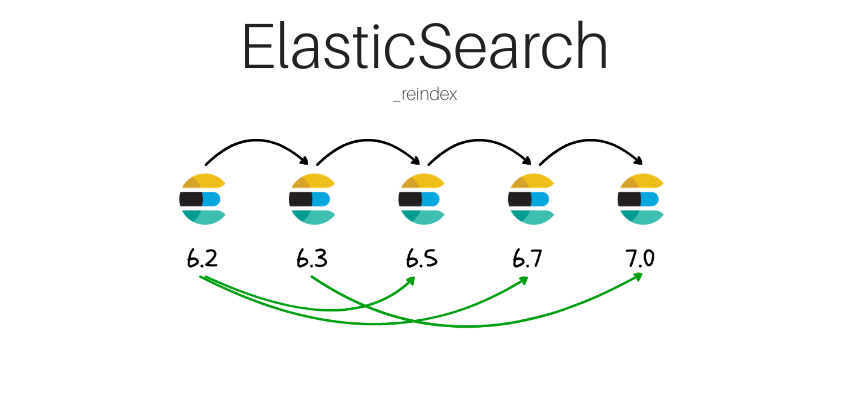
Lekcji :
37 wideo
Czas : 6 godz.
Kurs wprowadzi Cię w świat systemu kolejkowania RabbitMQ. Zaczniemy od instalacji i konfiguracji serwera. Następnie poznamy wszystkie rodzaje central wiadomości, kolejki i ich parametry. Skończymy na stworzeniu i zabezpieczeniu klastra.