-
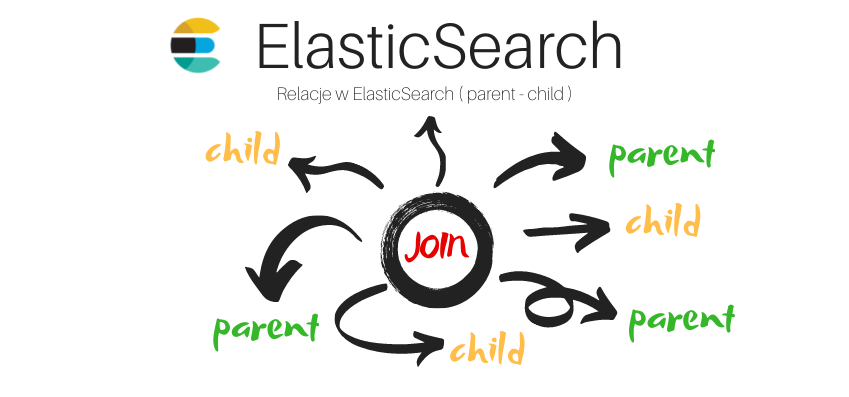 W relacyjnych bazach danych tworzenie relacji jest naturalnym sposobem odwzorowywania rzeczywistości. Jednak w przypadku, gdy mamy odczynienia z wyszukiwarką opartą o nierelacyjną bazę danych sprawy nieco się komplikują.
W relacyjnych bazach danych tworzenie relacji jest naturalnym sposobem odwzorowywania rzeczywistości. Jednak w przypadku, gdy mamy odczynienia z wyszukiwarką opartą o nierelacyjną bazę danych sprawy nieco się komplikują. -
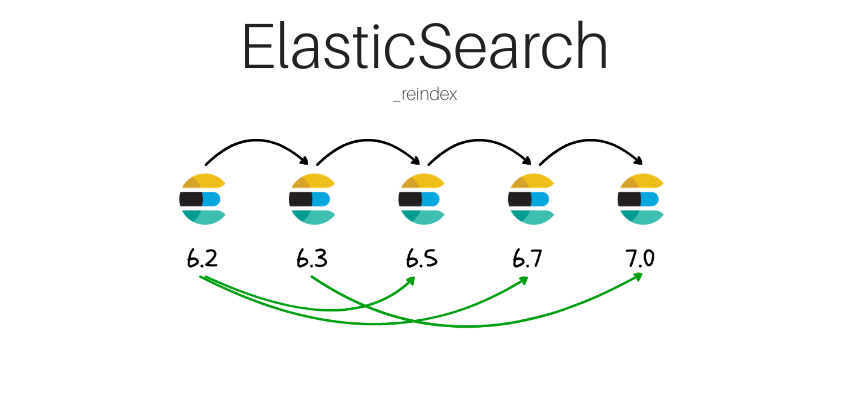 ElasticSearch rozwija się bardzo dynamicznie w związku z czym możemy zaobserwować dość częste wydawanie nowej wersje silnika. I pojawia się pytanie, czy aktualizować ? Osobiście chętnie aktualizuję, czy to ElasticSearch-a, czy też frameworki na których pracuję. Wyznaję przy tym kilka zasad, jedna z nich to stabilność działania. Dlatego w tym wpisie pokażę, jak w prosty sposób przenieść nasze indeksy do nowszej wersji ElasticSearch-a wykorzystując _reindex.
ElasticSearch rozwija się bardzo dynamicznie w związku z czym możemy zaobserwować dość częste wydawanie nowej wersje silnika. I pojawia się pytanie, czy aktualizować ? Osobiście chętnie aktualizuję, czy to ElasticSearch-a, czy też frameworki na których pracuję. Wyznaję przy tym kilka zasad, jedna z nich to stabilność działania. Dlatego w tym wpisie pokażę, jak w prosty sposób przenieść nasze indeksy do nowszej wersji ElasticSearch-a wykorzystując _reindex. -
 Tworząc wyszukiwarkę o wysokim poziomie trafności, musimy wziąć pod uwagę obsługę języka. A jak wiemy nasz język do najłatwiejszych nie należy. Sam silnik wyszukiwania także nie wspiera naszego języka, ale pokażę Ci jak pomimo tych przeszkód poradzić sobie z obsługą języka polskiego.
Tworząc wyszukiwarkę o wysokim poziomie trafności, musimy wziąć pod uwagę obsługę języka. A jak wiemy nasz język do najłatwiejszych nie należy. Sam silnik wyszukiwania także nie wspiera naszego języka, ale pokażę Ci jak pomimo tych przeszkód poradzić sobie z obsługą języka polskiego. -
 W pierwszym wpisie tej serii opisałem jak konstruować proste zapytania wyszukujące. Był to zaledwie przedsmak tego co można zrobić w ElasticSearch. Tym razem poszerzymy wiedzę o najczęściej wykorzystywane sposoby wyszukiwania oraz zobaczymy jakie problemy poszczególne sposoby rozwiązują.
W pierwszym wpisie tej serii opisałem jak konstruować proste zapytania wyszukujące. Był to zaledwie przedsmak tego co można zrobić w ElasticSearch. Tym razem poszerzymy wiedzę o najczęściej wykorzystywane sposoby wyszukiwania oraz zobaczymy jakie problemy poszczególne sposoby rozwiązują. -
 Oprócz zaawansowanego wyszukiwanie pełnotekstowego w ElasticSearch mamy także możliwość grupowania i zliczania dokumentów. Co ważne operacje zliczania mogą być wykonywane równolegle z operacjami przeszukiwania indeksu. Dzięki czemu możemy zmniejszyć ilość zapytań do wyszukiwarki.
Oprócz zaawansowanego wyszukiwanie pełnotekstowego w ElasticSearch mamy także możliwość grupowania i zliczania dokumentów. Co ważne operacje zliczania mogą być wykonywane równolegle z operacjami przeszukiwania indeksu. Dzięki czemu możemy zmniejszyć ilość zapytań do wyszukiwarki. -
 Jeśli mieliście kontakt z relacyjnymi bazami danych (MySQL, MSSQL, PostgreSQL) to przyzwyczaiły was one do definiowania schematów bazy danych. W takim schemacie bazę dzielimy na tabele, tabele na kolumny, którym z kolei przypisujemy określony typy danych. Odpowiednikiem tego podejścia jest mapping w ElasticSearch.
Jeśli mieliście kontakt z relacyjnymi bazami danych (MySQL, MSSQL, PostgreSQL) to przyzwyczaiły was one do definiowania schematów bazy danych. W takim schemacie bazę dzielimy na tabele, tabele na kolumny, którym z kolei przypisujemy określony typy danych. Odpowiednikiem tego podejścia jest mapping w ElasticSearch. -
 W przypadku, gdy żaden z wbudowanych analizer-ów nie spełnia naszych wymagań. ElasticSearch daje nam możliwość zbudowania własnych. Jednak jeśli mamy już stworzony indeks to dodanie nowego analizer-a wymaga odrobiny gimnastyki.
W przypadku, gdy żaden z wbudowanych analizer-ów nie spełnia naszych wymagań. ElasticSearch daje nam możliwość zbudowania własnych. Jednak jeśli mamy już stworzony indeks to dodanie nowego analizer-a wymaga odrobiny gimnastyki. -
 Podczas operacji wprowadzania danych czyli indeksacji, dane są analizowane przez mechanizm, który nazywa się analizerem. Elasticsearch dostarcza nam zestaw wbudowanych analizerów, które w większości przypadków będą wystarczające.
Podczas operacji wprowadzania danych czyli indeksacji, dane są analizowane przez mechanizm, który nazywa się analizerem. Elasticsearch dostarcza nam zestaw wbudowanych analizerów, które w większości przypadków będą wystarczające. -
 Niezależnie od języka w jakim piszemy aplikacje prędzej czy później możemy się spotkać z koniecznością przeszukiwania dużych ilości danych. Z reguły przeszukiwanie to ma być “inteligentne” czyli pozwalać na drobne błędy w pisowni oraz uwzględniać odmiany słów. Jak już zapewne część z was się domyśliła chodzi mi o wyszukiwanie pełnotekstowe.
Niezależnie od języka w jakim piszemy aplikacje prędzej czy później możemy się spotkać z koniecznością przeszukiwania dużych ilości danych. Z reguły przeszukiwanie to ma być “inteligentne” czyli pozwalać na drobne błędy w pisowni oraz uwzględniać odmiany słów. Jak już zapewne część z was się domyśliła chodzi mi o wyszukiwanie pełnotekstowe.