
Wprowadzenie do Elasticsearch

Niezależnie od języka w jakim piszemy aplikacje prędzej czy później możemy się spotkać z koniecznością przeszukiwania dużych ilości danych. Z reguły przeszukiwanie to ma być “inteligentne” czyli pozwalać na drobne błędy w pisowni oraz uwzględniać odmiany słów. Jak już zapewne część z was się domyśliła chodzi mi o wyszukiwanie pełnotekstowe.
I w przypadku operacji na niewielkich ilościach rekordów możemy skorzystać z przeszukiwania pełnotekstowego, które znajdziemy w silnikach bazodanowych. Jednak jeśli ilości te są znaczne konieczne jest skorzystanie z dedykowanych rozwiązań takich jak Elasticsearch czy Sphinx.
Czym jest Elasticsearch?
Mówimy że Elasticsearch jest silnikiem wyszukiwania pełnotekstowego, jednak jeśli przyjrzymy się dokładniej temu rozwiązaniu. To dowiemy się, że sam Elasticsearch jest bazą danych, która do wyszukiwania wykorzystuje Apache Lucene. Ta kombinacja daje nam dostęp do potężnego narzędzia umożliwiającego przeszukiwanie, grupowanie oraz filtrowanie ogromnych zbiorów danych niemal w czasie rzeczywistym. Jeśli dodamy do tego jeszcze rozproszony model pracy oraz REST-owe API to ciężko będzie znaleźć lepsze rozwiązanie ;)
Nie oznacza to oczywiście, że jest to jedyne i słuszne rozwiązanie. Jak wspominałem wcześniej mamy wyszukiwarkę Sphinx oraz Apache Solr, która także bazuje na Apache Lucene.
Jak zbudowany jest Elasticsearch?
Zanim przejdziemy do pracy z wyszukiwarką powinniśmy nieco bliżej poznać jej budowę. Nie będę tutaj rozbierał na czynniki pierwsze budowy Elasticsearch, a jedynie skupię się na elementach podstawowych potrzebnych do późniejszej pracy. Bardziej zaawansowane rzeczy poznamy nieco później, gdy będziemy je wykorzystywać w praktyce.
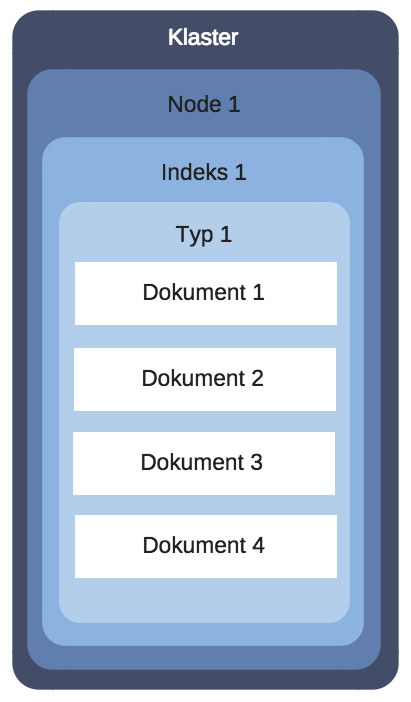
Node – tą nazwą określamy pojedynczy serwer. Każdy serwer posiada swoją nazwę oraz port na którym działa, standardowy port to 9200. To tutaj następuje przetwarzanie oraz przeszukiwanie danych.
Cluster – jest zbiorem jednego lub więcej node-ów.
Index – to kolekcja dokumentów o zbliżonej charakterystyce. Nazwa indeksu jest kluczowym elementem, gdyż to na jej podstawie odwołujemy się do określonego indeksu i wyszukujemy dokumenty czy też dodajemy / usuwamy dokumenty. W relacyjnej bazie danych indeks traktowali byśmy jako bazę danych.
Type - typ jest kolejnym poziomem grupowania danych po indeksie. W relacyjnej bazie danych powiedzieli byśmy że jest tabelą, z tą różnicą że w relacyjnej bazie danych mamy sztywno zdefiniowaną strukturę tabeli. W przypadku typów struktura ta jest zależna od przechowywanych w nich dokumentów.
Document – dokumenty są rekordami, które dodajemy tak jak byśmy dodawali rekordy do tabeli w relacyjnej bazie danych. Przy czym dokumenty są zapisywane w formacie JSON.
Jeśli chcielibyśmy sobie to jakoś zwizualizować to mogło by to wyglądać w następujący sposób:
Instalacja i konfiguracja Elasticsearch
Instalacja i konfiguracja dla różnych systemów operacyjnych może wyglądać nieco inaczej jeśli korzystamy z menadżerów pakietów. Jednak jeśli pobierzemy paczkę ZIP ze strony elastic.co, a następnie rozpakujemy archiwum. To pozostaje nam wejść do katalogu do którego został rozpakowany Elasticsearch, a następnie do katalogu bin i uruchomić plik elasticsearch lub elasticsearch.bat dla systemu Windows. Prawda że proste ;)
Mac OS X
Jeśli nie chcemy skorzystać z przygotowanej paczki ZIP na stronie elastic.co to możemy do instalacji wykorzystać menadżer pakietów. Polecenie instalacji będzie wyglądało wtedy następująco:
brew install elasticsearch
Jeśli otrzymacie komunikat o konieczności instalacji pakietu Java to możecie to zrobić poleceniem:
brew cask install java
Po czym możemy uruchomić Elasticsearch poleceniem:
elasticsearch
Linux
Tutaj polecenia mogą być różne w zależności od dystrybucji na jakiej pracujecie. Tak więc poniższe polecenie powinno zadziałać na Debianie i pochodnych w tym Ubuntu.
Zaczynamy od instalacji Java, jeśli mamy już pakiet w systemie to możemy pominąć ten krok.
sudo add-apt-repository ppa:webupd8team/java -y
sudo apt-get update
sudo apt-get install -y oracle-java8-installer
Przechodzimy teraz do instalacji samego Elasticsearch-a.
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
Dodajemy repozytorium z wersją 5.x
echo "deb https://artifacts.elastic.co/packages/5.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-5.x.list
Po czym przechodzimy do właściwej instalacji.
sudo apt-get update
sudo apt-get install -y elasticsearch
Po zakończeniu instalacji przechodzimy do katalogu Elasticsearch-a i edytujemy plik konfiguracyjny elasticsaerch.yml
sudo nano /etc/elasticsearch/elasticsearch.yml
Należy od komentować poniższe linie:
bootstrap.memory_lock: true
network.host: localhost
http.port: 9200
Zapisujemy i wychodzimy, teraz edytujemy serwis poleceniem:
sudo nano /usr/lib/systemd/system/elasticsearch.service
W pliku od komentowujemy linię:
LimitMEMLOCK=infinity
Po czym zapisujemy i wychodzimy. I przechodzimy do edycji ostatniego pliku:
sudo nano /etc/default/elasticsearch
I tutaj także od komentowujemy jedną linię oraz upewniamy się że wartość jest ustawiona na “unlimited”.
MAX_LOCKED_MEMORY=unlimited
Po zapisaniu i wyjściu konieczny jest restart usługi.
sudo systemctl daemon-reload
sudo systemctl enable elasticsearch
sudo systemctl start elasticsearch
Windows
W przypadku Windows-a sprawa jest dość prosta i sprowadza się do ściągnięcia instalatora ze strony Elasticsearch-a. Dostępny jest on w sekcji download pod skrótem MSI, po ściągnięciu kilka razy next i gotowe ;)
Docker
Jak że powoli staje się fanem wirtualizacji i prostoty stawiania środowisk programistycznych wykorzystując Vagrant-a i Docker-a tak więc i tutaj pokaże jak prosto można to wykonać.
Zakładam że macie zainstalowanego Docker-a, który jest konieczny do działania kontenerów. Jeśli tak to tworzymy plik docker-compose.yml z zawartością:
version: '2'
services:
elasticsearch:
image: elasticsearch:5.5
ports:
- "9200:9200"
Po czym przechodzimy do konsoli i uruchamiamy plik poleceniem:
docker-compose up -d
I na tym kończy się nasza praca, usługa jest dostępna pod standardowym adresem localhost:9200
Komunikacja z Elasticsearch
Kiedy mamy już zainstalowanego Elasticsearch-a możemy przejść do komunikacji z nim. Jako że komunikacja jest oparta o REST-owe API więc na początek wystarczy przeglądarka internetowa i CURL.
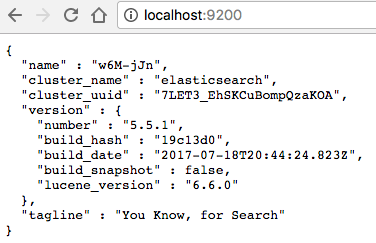
Zacznijmy od czegoś prostego, zweryfikujemy czy nasz serwer działa wchodząc po prostu pod adres http://localhost:9200. Jeśli wszystko jest działa prawidłowo to powinnismy zobaczyć coś podobnego do poniższego zrzutu.
Dodawanie dokumentów
Zanim dodamy dokument do indeksu konieczne jest utworzenie indeksu o określonej nazwie. Na potrzeby tego przykładu stworzymy prosty indeks z listą krajów w związku z czym nazwiemy nasz indeks countries.
Request tworzący indeks countries w CURL będzie wyglądała następująco:
curl -XPUT '127.0.0.1:9200/countries'
W odpowiedzi dostaniemy coś takiego:
{"acknowledged":true,"shards_acknowledged":true,"index":"countries"}
Parametry mają wartość true co świadczy o powodzeniu operacji. Jednak czytelność jest słaba, ale można ją poprawić dodając do zapytania ?pretty, czyli po modyfikacji będzie wyglądało następująco:
curl -XPUT '127.0.0.1:9200/countries?pretty' -H 'Content-Type: application/json'
I teraz otrzymamy czytelniejszą odpowiedź:
{
"acknowledged":true,
"shards_acknowledged":true,
"index":"countries"
}
Tylko nie wykonujcie tych dwóch poleceń po sobie, aby porównać wyniki działania. Taka operacja skończy się niepowodzeniem, gdyż indeks o podanej nazwie już istnieje. Jeśli chcecie powtórzyć operację tworzenia indeksu konieczne jest uprzednie jego skasowanie poleceniem:
curl -XDELETE '127.0.0.1:9200/countries?pretty' -H 'Content-Type: application/json'
Kiedy mamy już założony indeks czas dodać do niego dokumenty. Jednak zanim dodamy pierwszy dokument musimy pamiętać jak wygląda struktura w Elasticsearch indeks -> typ -> dokument. Przy czym indeks zdefiniowaliśmy, zaś typ definiowany jest dynamicznie przy dodawaniu dokumentu, a od nas jest jedynie wymagane podanie nazwy typu. Na nasze potrzeby typ nazwiemy country, a request dodający pierwszy dokument będzie wyglądał następująco:
curl -XPOST '127.0.0.1:9200/countries/country?pretty' -H 'Content-Type: application/json' -d '
{
"code": "PL",
"name": "Polska"
}'
Co powinno przynieść poniższy rezultat:
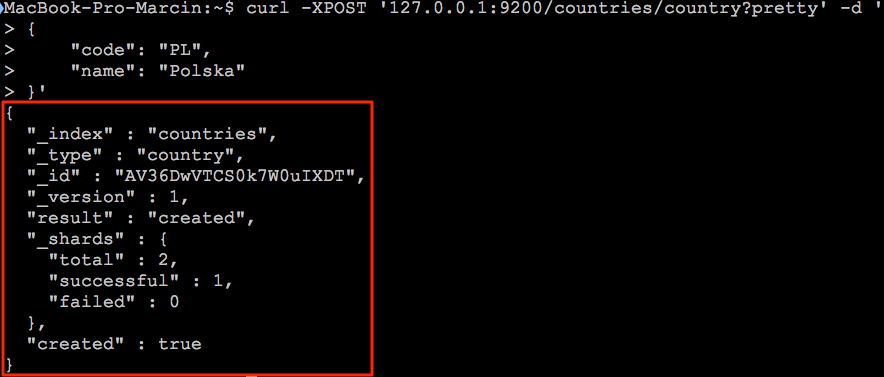
Odpowiedz zaznaczona na czerwono przynosi nam komplet informacji na temat dodanego dokumentu. Mamy informację o indeksie “_index”, typie “_type”, identyfikatorze “_id” oraz kilka innych informacji, które na tym etapie nas nie interesują. Najbardziej interesuje nas klucz “created”, który powinien posiadać wartość “true”.
Dodatkowo powinniśmy wiedzieć, że identyfikator automatycznie wygenerowany przez Elasticsearch będzie przydatny przy operacjach usuwania i aktualizacji. W związku z czym może zaistnieć potrzeba ustawiania jego wartości ręcznie co robimy poprzez dodanie go do adresu url.
curl -XPOST '127.0.0.1:9200/countries/country/1?pretty' -H 'Content-Type: application/json' -d '
{
"code": "PL",
"name": "Polska"
}'
Teraz dodany dokument będzie miał ustawiony identyfikator na wartość “1”. Co w przyszłości ułatwi nam aktualizację i usuwanie dokumentu.
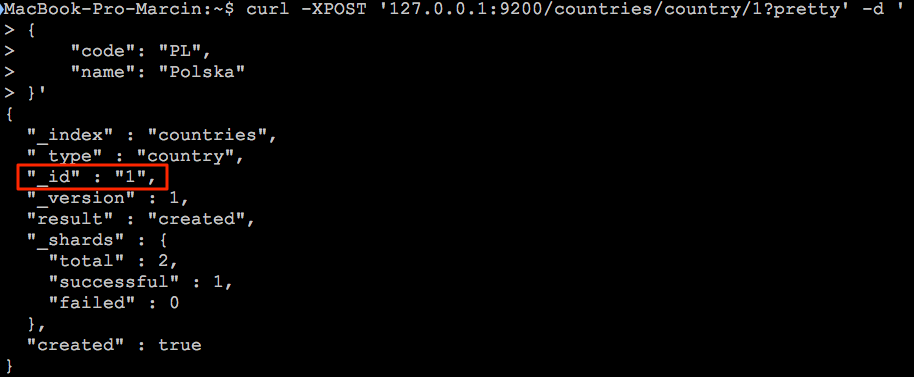
Po dodaniu pierwszego dokumentu do danego indeksu i typu Elasticsearch ustalił strukturę typu dokumentu wraz z formatem pól. Możemy podejrzeć wygenerowaną strukturę wysyłając następującego request-a:
curl -XGET '127.0.0.1:9200/countries/_mapping?pretty' -H 'Content-Type: application/json'
Żądanie odwołuje się do indeksu countries i prosi o zwrócenie informacji z _mapping. Rezultat powinien być zbliżony do poniższego:
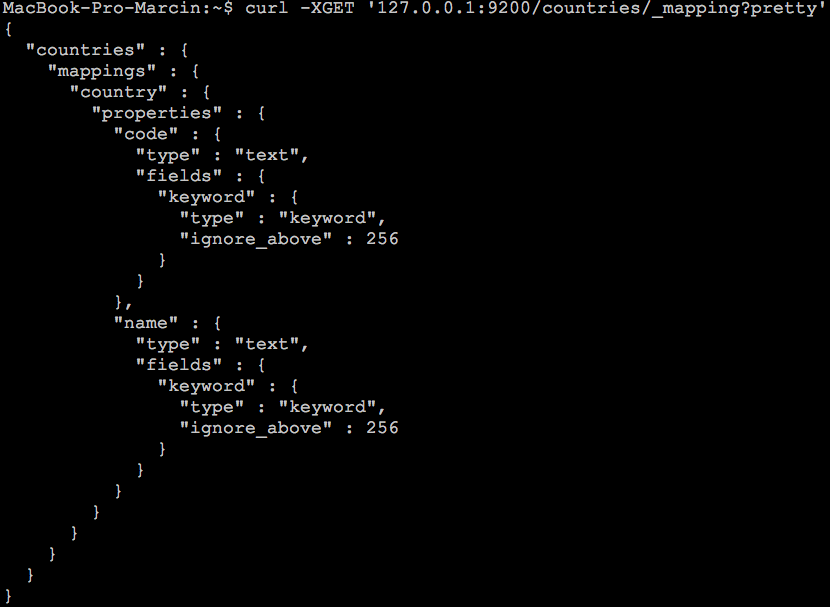
Skoro potrafimy dodawać rekordy dodajmy kilka krajów z kodami. Przyda nam się taki zbiór, gdy będziemy przeszukiwali indeks.
curl -XPOST '127.0.0.1:9200/countries/country?pretty' -H 'Content-Type: application/json' -d '
{
"code": "AF",
"name": "Afghanistan"
}'
curl -XPOST '127.0.0.1:9200/countries/country?pretty' -H 'Content-Type: application/json' -d '
{
"code": "FR",
"name": "Francja"
}'
curl -XPOST '127.0.0.1:9200/countries/country?pretty' -H 'Content-Type: application/json' -d '
{
"code": "DE",
"name": "Niemcy"
}'
curl -XPOST '127.0.0.1:9200/countries/country?pretty' -H 'Content-Type: application/json' -d '
{
"code": "MX",
"name": "Meksyk"
}'
curl -XPOST '127.0.0.1:9200/countries/country?pretty' -H 'Content-Type: application/json' -d '
{
"code": "MT",
"name": "Malta"
}'
curl -XPOST '127.0.0.1:9200/countries/country?pretty' -H 'Content-Type: application/json' -d '
{
"code": "PE",
"name": "Peru"
}'
curl -XPOST '127.0.0.1:9200/countries/country?pretty' -H 'Content-Type: application/json' -d '
{
"code": "PT",
"name": "Portugal"
}'
curl -XPOST '127.0.0.1:9200/countries/country?pretty' -H 'Content-Type: application/json' -d '
{
"code": "TH",
"name": "Tailandia"
}'
Wyszukiwanie
Skoro mamy już wprowadzone dane do naszego indeksu czas coś wyszukać. Zacznijmy od najprostszego wyszukiwania, czyli wyszukiwanie bez ustawiania kryteriów.
curl -XGET '127.0.0.1:9200/countries/country/_search?pretty' -H 'Content-Type: application/json'
W rezultacie powinniśmy otrzymać wszystkie wprowadzone rekordy. Jeśli byśmy chcieli ograniczyć wynik wyszukiwania do pierwszych 3 dokumentów to dodajemy parametr size
curl -XGET '127.0.0.1:9200/countries/country/_search?size=3&pretty' -H 'Content-Type: application/json'
Możemy także pominąć określoną liczbę dokumentów dodając parametr from. W poniższym przypadku pomijamy pierwszy dokument wpisując wartość 1, gdyż dokumenty są numerowane od zera.
curl -XGET '127.0.0.1:9200/countries/country/_search?from=1&size=3&pretty' -H 'Content-Type: application/json'
Potrafimy już pobrać dokumenty z indeksu jednak niczego jeszcze nie wyszukaliśmy. Czas przejść do kolejnego parametru jakim jest parametr q, przyjmuje on jako wartość nazwę pola oraz wartość.
curl -XGET '127.0.0.1:9200/countries/country/_search?q=name:Polska&pretty' -H 'Content-Type: application/json'
W powyższym przykładzie powiedzieliśmy aby Elasticsearch wyszukał w polu name wartości Polska. Co jeśli nie uwzględnimy wielkości liter i każemy naleźć słowo polska?
curl -XGET '127.0.0.1:9200/countries/country/_search?q=name:polska&pretty' -H 'Content-Type: application/json'
W takim przypadku Elasticsearch także sobie poradził beż żadnych problemów :)
Ten sposób wyszukiwania, który zastosowaliśmy powyżej nazywamy URI Search i świetnie się w prostych przypadkach jak powyżej. Jednak gdy poziom skomplikowania zapytań rośnie ciężko jest zapisać je w formie adresów url. Z pomocą przychodzi nam wtedy język zapytań DSL wbudowany w Elasticsearch. Zobaczmy jak wyglądały by masze zapytania zapisane w języku DSL.
Listujemy wszystkie dokumenty
curl -XPOST '127.0.0.1:9200/countries/country/_search?pretty' -H 'Content-Type: application/json' -d '{
"query": {
"match_all": {}
}
}'
Listujemy pierwsze 3 dokumenty
curl -XPOST '127.0.0.1:9200/countries/country/_search?pretty' -H 'Content-Type: application/json' -d '{
"query": {
"match_all": {}
},
"size": 3
}'
Listujemy 3 dokumenty z pominięciem pierwszego
curl -XPOST '127.0.0.1:9200/countries/country/_search?pretty' -H 'Content-Type: application/json' -d '{
"query": {
"match_all": {}
},
"size": 3,
"from": 1
}'
Wyszukujemy dokument o nazwie Polska
curl -XPOST '127.0.0.1:9200/countries/country/_search?pretty' -H 'Content-Type: application/json' -d '{
"query": {
"match": {
"name": "Polska"
}
}
}'
Na tym dziś zakończymy przygodę z wyszukiwaniem, pokazane tutaj metody to absolutne podstawy i dopiero wprowadzenie do wyszukiwania w Elasticsearch. Kolejnym razem zajmiemy się bardziej zaawansowanymi sposobami przeszukiwania dokumentów.
Usuwanie
Każdy dokument może kiedyś przestać być użyteczny, co wiąże się z jego usunięciem z systemu oraz wyszukiwarki. Usuwanie jest tak samo prostą operacją jak dodawanie dokumentu. Wywołujemy requesta i następuje operacja usunięcia dokumentu, jedynie co potrzebujemy znać to identyfikator usuwanego dokumentu.
Identyfikator dokumentu możemy pobrać z rezultatu wyszukiwania lub innego źródła jeśli nadawaliśmy go ręcznie.
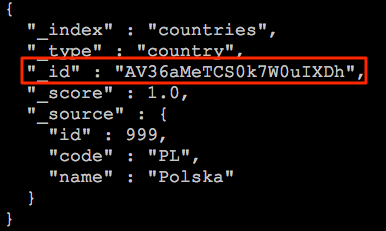
Nie jest on zbyt przyjazny jeśli jest definiowany automatycznie przez co konieczne jest najpierw odnalezienie w systemie odpowiedniego dokumentu, pobranie jego identyfikatora i dopiero usunięcie poniższym poleceniem:
curl -XDELETE '127.0.0.1:9200/countries/country/AV36aMeTCS0k7W0uIXDh?pretty' -H 'Content-Type: application/json'
Na szczęście nie jest to jedyny sposób na usuwanie dokumentów z indeksu. Możliwe jest usuwanie w oparciu o rezultat wyszukiwania co znacznie ułatwia całą operację.
curl -XPOST '127.0.0.1:9200/countries/country/_delete_by_query?pretty' -H 'Content-Type: application/json' -d '{
"query": {
"match": {
"name": "Polska"
}
}
}'
Prawda że od razu lepiej, a w odpowiedzi otrzymamy takie informacje:
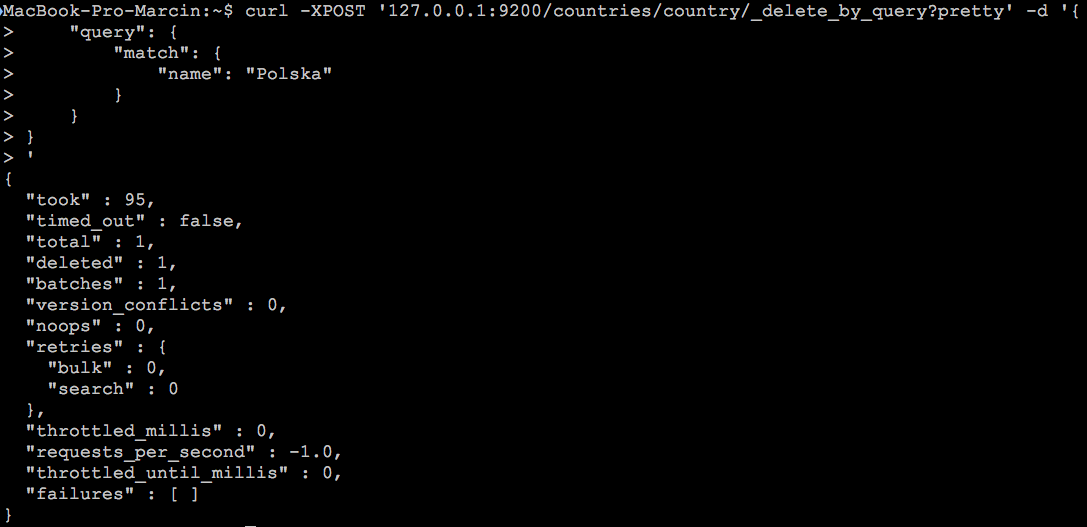
Nas w tej odpowiedzi najbardziej interesuje klucz deleted mówiący ile dokumentów zostało usuniętych.
Aktualizacja
Ostatnia operacja to aktualizacja danych w indeksie. Jest ona podobna do operacji usuwania dokumentu bowiem w tym przypadku potrzebujemy także identyfikatora dokumentu. Zaś request aktualizacji wygląda następująco:
curl -XPUT '127.0.0.1:9200/countries/country/AV36fQHvCS0k7W0uIXDm?pretty' -H 'Content-Type: application/json' -d '{
"code": "PL",
"name": "Poland"
}'
W odpowiedzi otrzymamy informacje o powodzeniu operacji znajdującej się w kluczu result
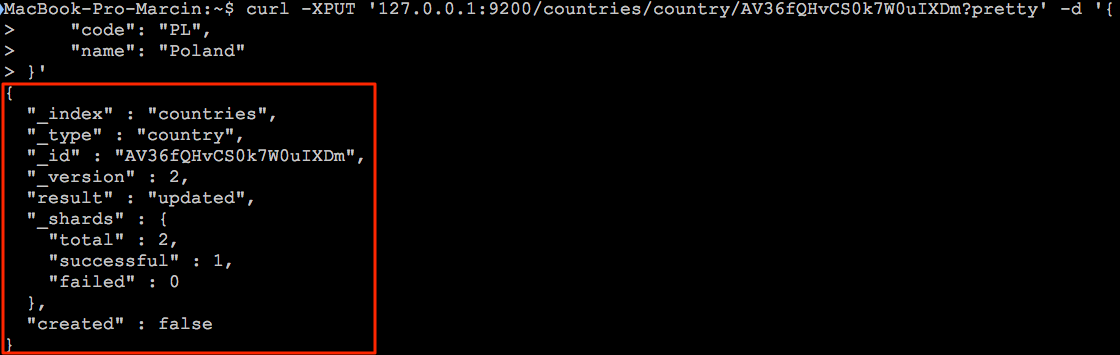
Oczywiście są inne sposoby aktualizacji dokumentów w indeksie jednak są one nieco bardziej skomplikowane w związku z czym zajmiemy się tym tematem w osobnym wpisie.
Podsumowanie
Jak widać Elasticsearch nie jest taki straszny jak mogło by się wydawać. Dzięki REST-owemu API praktycznie każdy web developer jest w stanie szybko się zaprzyjaźnić z tym rozwiązaniem. Sama budowa tego rozwiązania jest także zbliżona do koncepcji bazy danych co na początku może ułatwić zrozumienie czym jest node, index, type oraz document. Oczywiście to dopiero początek przygody z tym rozwiązaniem i czym dokładniej będziemy je poznawali tym bardziej skomplikowane problemy uda nam się rozwiązać. Tak więc trzymajcie rękę na pulsie, już niedługo kolejny wpis :)