
Tworzenie klastra

Do tej pory wszystkie operacje wykonywaliśmy na jednej instancji RabbitMQ. Ma to kilka wady. Pierwsza i najważniejsza, to brak bezpieczeństwa. Co się stanie, gdy serwer RabbitMQ ulegnie awarii ?? Czy jesteś w stanie odzyskać dane z serwera, jak szybko jesteś w stanie uruchomić kolejną instancję ?? Wiele niewiadomych, a można sypiać spokojniej dzięki klastrowi ![]()
Budujemy klaster
Budowę klastra zaczniemy od postawienia jednego wymagania, a jest nim posiadanie zainstalowanego Docker-a. Dzięki niemu będziemy mogli szybko uruchomić wiele instancji Rabbit-a.
Klaster który będziemy budować będzie klastrem trzywęzłowym. Powód jest prosty, taki klaster może używać kolejek typu Quorum, ale im przyjrzymy się w kolejnym wpisie.
Pierwszy węzeł
Teraz zbudujmy nasz klaster. Do tego celu wykorzystamy oficjalny obraz https://hub.docker.com/_/rabbitmq z zainstalowanym plugiem panelu administracyjnego. Dlatego wybierzemy tag 3-management, co na moment pisania tego wpisu da nam wersję 3.9.
Pierwszy kontener uruchamiamy poniższym poleceniem:
docker run -d \
--hostname rabbit1 \
--name rabbit1 \
-p 5672:5672 \
-p 15672:15672 \
-p 25672:25672 \
rabbitmq:3-management
W powyższym poleceniu wykorzystałem trzy flagi:
- hostname - ustawia nazwę hosta dla kontenera, przydatne kiedy będziemy łączyli poszczególne kontenery w klaster,
- name - nazwa kontenera,
- p - przekierowanie portów, standardowo mamy do dyspozycji port 5672 (dla aplikacji), 15672 (dla panelu administracyjnego) oraz 25672 (dla CLI i klastrowania)
Przy pierwszym uruchomieniu polecenia, powinniśmy zobaczyć proces pobierania obrazu. Po jego zakończeniu nastąpi uruchomienie kontenera.
Unable to find image 'rabbitmq:3-management' locally
3-management: Pulling from library/rabbitmq
a39c84e173f0: Pull complete
7d3994c28245: Pull complete
516c2ecaa7df: Pull complete
b8c39ecfffe8: Pull complete
e8223e7f3587: Pull complete
98444526af3f: Pull complete
9c50dd104856: Pull complete
48ecdca9f061: Pull complete
687806557d7b: Pull complete
1f1e2bda2823: Pull complete
Digest: sha256:37f39d4af8ba92ccbc63043e4bdc89dd4e334cae045fd7d60182c23708de5f93
Status: Downloaded newer image for rabbitmq:3-management
17c1fe881f70e09f14aa26856b3a3961a9bdea06f1f30a60f0c845473c0562f4
Oczywiście identyfikatory będą u was inne, ale to nieistotne. Ważne, że po uruchomieniu polecenia docker ps, zobaczycie jeden uruchomiony kontener.
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
7b04beb1f056 rabbitmq:3-management "docker-entrypoint.s…" 4 minutes ago Up 4 minutes 4369/tcp, 5671-5672/tcp, 15671/tcp, 15691-15692/tcp, 25672/tcp, 0.0.0.0:15672->15672/tcp rabbit1
Widać, że ustawiliśmy przekierowanie portów 0.0.0.0:15672->15672, w związku z tym pod adresem http://localhost:15672 powinien być dostępny panel administracyjny. Logujemy się do niego za pomocą domyślnego użytkownika guest i hasła guest. Po zalogowaniu zobaczymy panel.
I tu musimy się na chwilę zatrzymać. A to dlatego, że na bazie pierwszego węzła będziemy tworzyli kolejne. Niestety tak stworzony węzeł nigdy nie połączy się z innym tworząc klaster. Winne jest Erlang Cookie o którym musimy sobie powiedzieć dwa słowa.
Erlang Cookie
W momencie, gdy instalujemy RabbitMQ i następuje pierwsze uruchomienie serwera, jest generowany plik .erlang.cookie z wartością losową. Plik ten nazywamy Erlang Cookie i służy on do uwierzytelnienia komunikacji pomiędzy węzłami Rabbit-a.
I teraz jeśli każdego Rabbit-a zainstalujemy i uruchomimy osobno, to każdy z nich będzie miał swój plik ze swoją wartością losową. Co oznacza, że nie da się takich węzłów połączy w jeden klaster ![]()
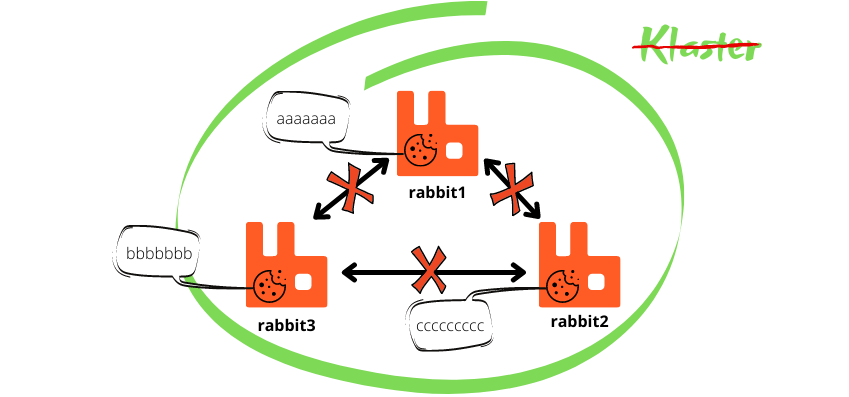
Rozwiązaniem jest posiadanie na wszystkich węzłach pliku o takiej samej wartości. Co da nam możliwość połączenia wszystkich węzłów w jeden klaster.
W systemach Unix-owych plik znajdziecie w lokalizacji /var/lib/rabbitmq/.erlang.cookie ( wykorzystywany przez serwer ) oraz $HOME/.erlang.cookie ( wykorzystywany przez CLI ).
Znając lokalizację pliku możecie zmienić jego zawartość i podłączyć nowy węzeł do już istniejącego klastra.
Erlang Cookie + Docker
Skoro wiemy, że konieczna jest taka sama zawartość pliku .erlang.cookie to musimy nadpisać plik znajdujący się wewnątrz kontenera. Do wersji RabbitMQ 3.9 była dostępna zmienna środowiskowa RABBITMQ_ERLANG_COOKIE. Niestety od wersji 3.9 ta zmienna nie jest już dostępna, przez co cały proces nieco bardziej się skomplikował ![]()
W związku z koniecznością nadpisania pliku wewnątrz kontenera musimy zastąpić polecenie docker run na rzecz docker service create. Nowe polecenie daje nam dostęp do flagi --secret, która jest nam potrzebna, aby nadpisać zawartość pliku .erlang.cookie.
Zaczynamy od zdefiniowania naszego sekretnego klucza, który znajdzie się w każdym pliku .erlang.cookie. W moim przypadku będzie to wartość czterytygodnie, którą ustawię pod nazwą app.erlang.cookie.
printf "czterytygodnie" | docker secret create app.erlang.cookie -
Mam już klucz, jednak to nie koniec rzeczy jakie muszę zrobić przed utworzeniem usługi z RabbitMQ. Kolejną rzeczą jest stworzenie sieci, do której podłączę wszystkie usługi. Dzięki temu, że wszystkie węzły będą w tej samej sieci, nie będzie problemu z ich widocznością.
docker network create -d overlay --attachable rabbit_cluster
Mając stworzoną sieć możemy przejść do polecenia, które będzie uruchamiało kontener. Polecenie jest bardzo podobne do tego co już widzieliśmy.
docker service create -d \
--hostname rabbit1 \
--name rabbit1 \
--network rabbit_cluster \
-p 5672:5672 \
-p 15672:15672 \
-p 25672:25672 \
--secret source=app.erlang.cookie,target=/var/lib/rabbitmq/.erlang.cookie,uid=999,gid=999,mode=0400 \
rabbitmq:3-management
Mamy dwie nowe flagi, pierwsza to --network, która wskazuje do której sieci należy podłączyć kontener. Druga --secret jest nieco bardziej rozbudowana. Ma kilka parametrów, których przeznaczenia zapewnię się domyślasz, ale dla pewności wyjaśnię co znaczą:
-
source, nazwa naszego sekretnego klucza dla
.erlang.cookie, - target, wskazujemy plik który chcemy nadpisać wartością z source,
- uid, identyfikator użytkownika, który ma stać się właścicielem pliku wskazanego w target,
- gid, identyfikator grupy, która ma być właścicielem pliku wskazanego w target,
- mode, uprawnienia z jakie ma mieć plik w target, uprawnienia są bardzo istotne, ponieważ do pliku może mieć tylko dostęp właściciel. Czyli w naszym przypadku użytkownik rabbitmq
Jedyną kwestią nad jaką możesz się zastanawiać to skąd wziąłem identyfikator użytkownika i grupy. Pytanie jest w pełni zasadne, otóż zalogowałem się do kontenera. Możesz to zrobić poleceniem za pomocą docker exec.
docker exec -it <identyfikator kontenera> bash
I kiedy byłem już zalogowany to uruchomiłem polecenie id rabbitmq. Co zwróciło mi w rezultacie taką odpowiedź.
uid=999(rabbitmq) gid=999(rabbitmq) groups=999(rabbitmq)
Skoro już wiemy jak pobrać identyfikator użytkownika i grupy to możemy wywołać nasze polecenie docker service create. Jeśli nic złego się nie wydarzyło to otrzymamy identyfikator usługi. Listę usług możemy podejżeć za pomocą docker service ls.
ID NAME MODE REPLICAS IMAGE PORTS
mba22j8xhifn rabbit1 replicated 1/1 rabbitmq:3-management *:5672->5672/tcp, *:15672->15672/tcp
U mnie na razie jest bieda ![]() Jednak za chwilę dodam kolejne węzły, co poszerzy listę usług.
Jednak za chwilę dodam kolejne węzły, co poszerzy listę usług.
Drugi węzeł
Dodawanie kolejnych węzłów znając pierwsze polecenie to bajka. Musimy jedynie pamiętać o zmianie wartości hostname, name i portów.
docker service create -d \
--hostname rabbit2 \
--name rabbit2 \
--network rabbit_cluster \
-p 5673:5672 \
-p 15673:15672 \
-p 25673:25672 \
--secret source=app.erlang.cookie,target=/var/lib/rabbitmq/.erlang.cookie,uid=999,gid=999,mode=0600 \
rabbitmq:3-management
Po utworzeniu usługi i jej starcie podglądamy listę uruchomionych kontenerów poleceniem docker ps. Na liście powinien znajdować się kontener, którego nazwa rozpoczyna się na rabbit2.1…
Logujemy się do tego kontenera, aby dołączyć go do klastra.
docker exec -it rabbit2.1... bash
Teraz musimy wydać 4 poniższe polecenia w celu podłączenia węzła do klastra rabbit@rabbit1.
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl join_cluster rabbit@rabbit1
rabbitmqctl start_app
Przy poleceniu rabbitmqctl join_cluster rabbit@rabbit1 może pojawić się ostrzeżenie lub błąd taki jak poniżej.
19:34:18.818 [warn] Feature flags: the previous instance of this node must have failed to write the `feature_flags` file at `/var/lib/rabbitmq/mnesia/rabbit@rabbit2-feature_flags`:
19:34:18.818 [warn] Feature flags: - list of previously disabled feature flags now marked as such: [:maintenance_mode_status]
19:34:18.956 [warn] Feature flags: the previous instance of this node must have failed to write the `feature_flags` file at `/var/lib/rabbitmq/mnesia/rabbit@rabbit2-feature_flags`:
19:34:18.956 [warn] Feature flags: - list of previously enabled feature flags now marked as such: [:maintenance_mode_status]
19:34:18.968 [error] Failed to create a tracked connection table for node :rabbit@rabbit2: {:node_not_running, :rabbit@rabbit2}
19:34:18.968 [error] Failed to create a per-vhost tracked connection table for node :rabbit@rabbit2: {:node_not_running, :rabbit@rabbit2}
19:34:18.969 [error] Failed to create a per-user tracked connection table for node :rabbit@rabbit2: {:node_not_running, :rabbit@rabbit2}
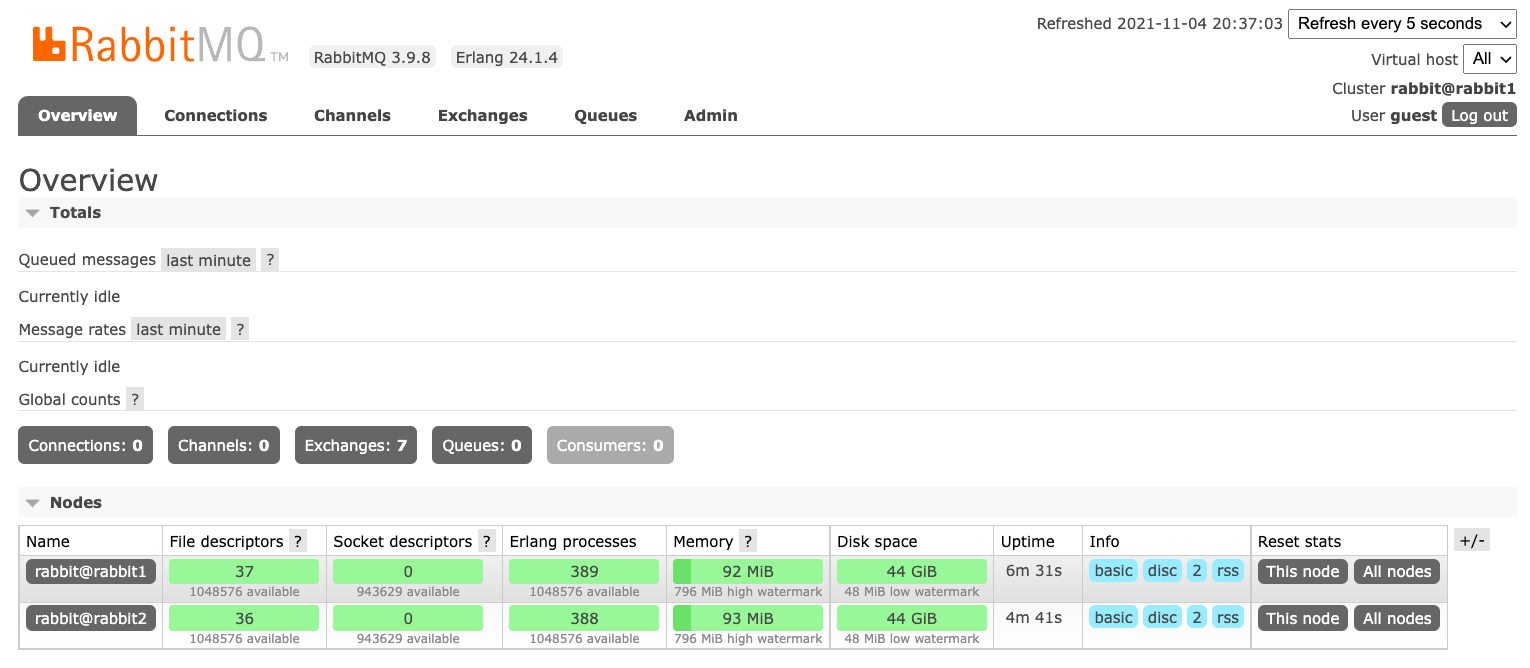
Nie panikujcie, prawdopodobnie nie będzie on miał znaczenia. Wykonajcie uruchomienie aplikacji rabbitmqctl start_app i sprawdźcie czy w panelu administracyjnym pojawił się kolejny węzeł http://localhost:15672.
Trzeci węzeł
Tu już znasz całą procedurę ![]()
docker service create -d \
--hostname rabbit3 \
--name rabbit3 \
--network rabbit_cluster \
-p 5674:5672 \
-p 15674:15672 \
-p 25674:25672 \
--secret source=app.erlang.cookie,target=/var/lib/rabbitmq/.erlang.cookie,uid=999,gid=999,mode=0600 \
rabbitmq:3-management
Tym razem nazwa kontenera rozpoczyna się od rabbit3.1… Logujemy się do kontenera.
docker exec -it rabbit3.1... bash
I dołączamy go do klastra.
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl join_cluster rabbit@rabbit1
rabbitmqctl start_app
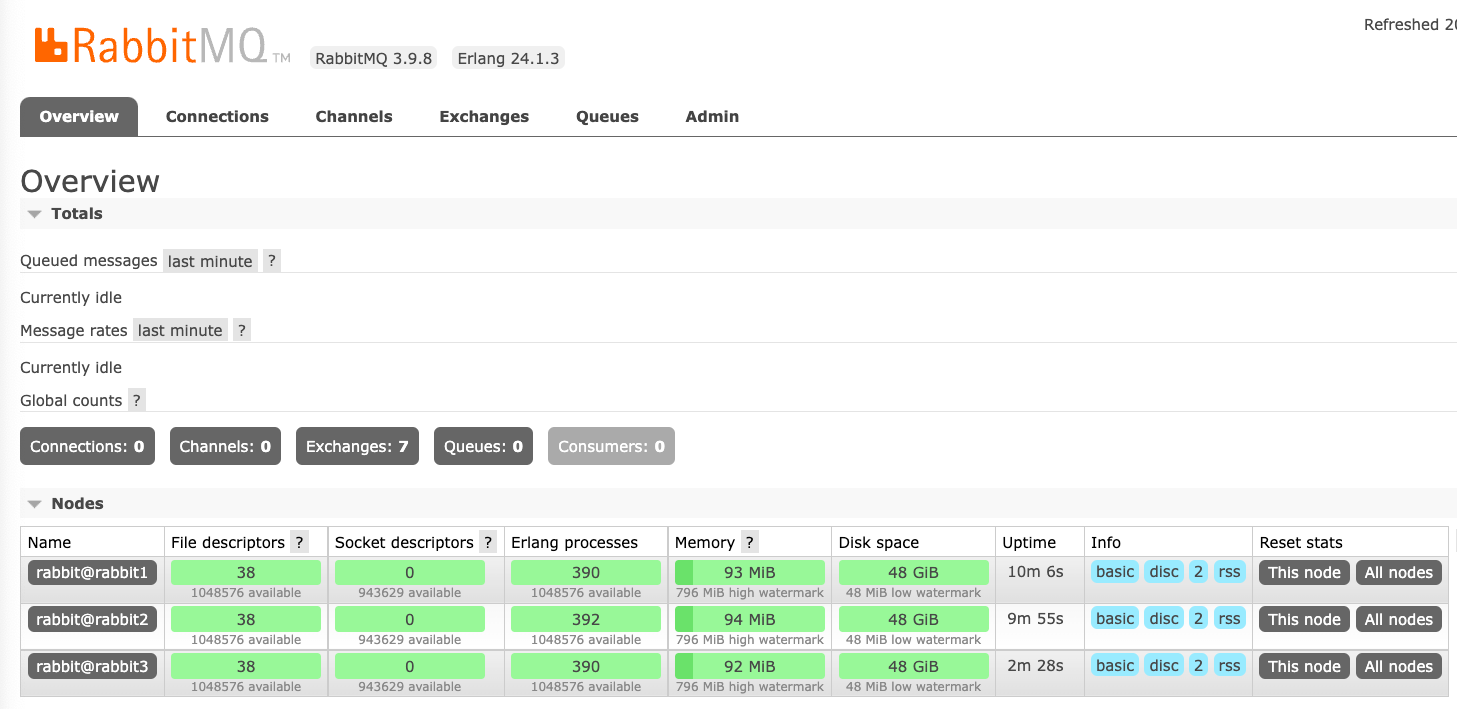
Widzisz u siebie to samo co na powyższym screenie ?? To masz trzywęzłowy klaster ![]() Niestety troszeczkę trzeba było się napracować. Odtworzenie tego przez kogoś bez instrukcji może skończyć się porażką. Dlatego musi być łatwiejsza droga. W kolejnej części wpisu pokażę Ci jak zautomatyzować proces budowania klastra.
Niestety troszeczkę trzeba było się napracować. Odtworzenie tego przez kogoś bez instrukcji może skończyć się porażką. Dlatego musi być łatwiejsza droga. W kolejnej części wpisu pokażę Ci jak zautomatyzować proces budowania klastra.
Zanim jednak zaczniesz usuń usługi które do tej pory stworzyliśmy, aby uniknąć konfliktów portów. Usługi usuwamy poleceniem docker service rm <nazwa usługi>.
Automatyzujemy budowę klastra
Automatyzacja budowy klastra opartego o Docker-a jest możliwa dzięki plikowi docker-compose.yml. Plik ten opisuje wszystkie usługi jakie mają być stworzone.
Spójrz na poniższy plik i zastanów się czy poszczególne jego elementy nie wyglądają znajomo.
docker-compose.yml
version: '3.9'
services:
rabbit1:
image: rabbitmq:3-management
hostname: rabbit1
ports:
- "5672:5672"
- "15672:15672"
- "25672:25672"
volumes:
- ./rabbitmq.conf:/etc/rabbitmq/rabbitmq.conf
secrets:
- source: erlang_cookie
target: /var/lib/rabbitmq/.erlang.cookie
uid: "999"
gid: "999"
mode: 0400
rabbit2:
image: rabbitmq:3-management
hostname: rabbit2
ports:
- "5673:5672"
- "15673:15672"
- "25673:25672"
volumes:
- ./rabbitmq.conf:/etc/rabbitmq/rabbitmq.conf
secrets:
- source: erlang_cookie
target: /var/lib/rabbitmq/.erlang.cookie
uid: "999"
gid: "999"
mode: 0400
rabbit3:
image: rabbitmq:3-management
hostname: rabbit3
ports:
- "5674:5672"
- "15674:15672"
- "25674:25672"
volumes:
- ./rabbitmq.conf:/etc/rabbitmq/rabbitmq.conf
secrets:
- source: erlang_cookie
target: /var/lib/rabbitmq/.erlang.cookie
uid: "999"
gid: "999"
mode: 0400
secrets:
erlang_cookie:
file: ./erlang_cookie.txt
Pewnie niewiele rzeczy było w stanie Cię zaskoczyć. Wynika to z faktu, że plik ten opisuje to co wcześniej zrobiliśmy za pomocą ustawienia flag. Mamy też definicję secrets, która tym razem pod kluczem erlang_cookie ukrywa zawartość pliku erlang_cookie.txt. Plik ten musimy stworzyć i wrzucić do niego jakiś losowy ciąg znaków. Ja pozostanę przy swojej poprzedniej frazie, ale produkcyjnie należy wrzucić to coś losowego ![]()
erlang_cookie.txt
czterytygodnie
Oczywiście to nie koniec. W pliku docker-compose.yml nie ma tworzenie klastra. I być nie może, plik ten jest uniwersalny i nie może posiadać tak specyficznych ustawień. Jednak w pliku znajdziemy nadpisanie pliku konfiguracyjnego RabbitMQ.
volumes:
- ./rabbitmq.conf:/etc/rabbitmq/rabbitmq.conf
I to właśnie tutaj znajduje się informacja o tym jak należy zbudować klaster. Ja skorzystałem z najprostszej wersji rabbit_peer_discovery_classic_config, która pozwala na zdefiniowanie listy węzłów w pliku konfiguracyjnym. Gdyby ktoś miał ochotę się pobawić, to może zmienić mechanizm na inny. Szczegóły znajdziecie w dokumentacji.
Pierwsza linia jest nieistotna w kontekście tworzenia klastra. Mówi ona czy można logować się na użytkownika guest zdalnie. Cała zabawa rozpoczyna się w kolejnej linii cluster_formation.peer_discovery_backend, gdzie wybieramy sposób klastrowania. Ja wykorzystałem plik konfiguracyjny, w którym jak widzisz, wymieniłem wszystkie węzły klastra.
rabbitmq.conf
loopback_users = none
cluster_formation.peer_discovery_backend = rabbit_peer_discovery_classic_config
cluster_formation.classic_config.nodes.1 = rabbit@rabbit1
cluster_formation.classic_config.nodes.2 = rabbit@rabbit2
cluster_formation.classic_config.nodes.3 = rabbit@rabbit3
Mamy wszystko gotowe więc możemy uruchomić przygotowane środowisko.
docker stack deploy -c docker-compose.yml rabbitmq
Co w odpowiedzi powinniśmy dostać informację o tworzeniu sieci, klucza i trzech usług.
Creating network rabbitmq_default
Creating secret rabbitmq_erlang_cookie
Creating service rabbitmq_rabbit1
Creating service rabbitmq_rabbit2
Creating service rabbitmq_rabbit3
Gdyby wystąpił jakiś problem przy tworzeniu usługi, to zawsze możemy podejrzeć jej logi.
docker service logs rabbitmq_rabbit1
To polecenie wyświetla logi usługi rabbitmq_rabbit1 w waszym przypadku tę nazwę musicie zmienić na taką, jaką widzicie w konsoli. Kiedy wszystkie usługi zostały utworzone otwieramy stronę http://localhost:15672, gdzie naszym oczom powinien ukazać się widok podobny do tego poniżej. Czyli klaster z trzema węzłami uruchomiony jednym poleceniem.
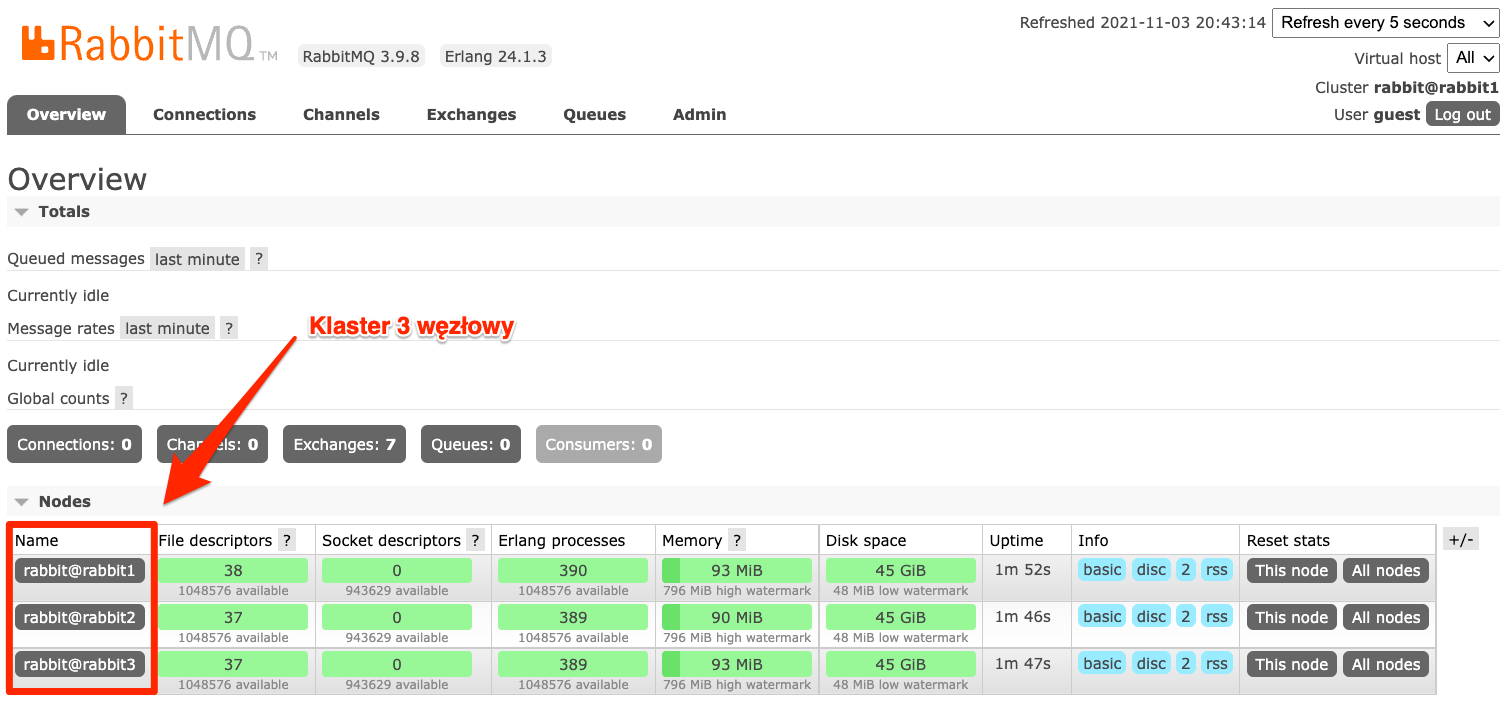
Taki sam panel powinien być dostępny pod dwoma pozostałymi portami, czyli:
W każdej chwili możemy zakończyć pracę środowiska za pomocą polecenia:
docker stack rm rabbitmq
Podsumowanie
Po wielu przejściach jesteśmy szczęśliwymi posiadaczami klastra RabbitMQ. Będzie on punktem wyjściowym dla kolejnych naszych zmagań. A będą nimi, zabezpieczenie przed awarią jednego z węzłów oraz poznanie kolejek typu Quorum.