
Patrzenie w przód i tył w wyrażeniach regularnych

We wprowadzeniu do wyrażeń regularnych pisałem, że tekst przeanalizowany przez silnik nie może być analizowany ponownie. Jednak nie do końca była to prawda. Wyrażenia regularne dostarczają nam mechanizm lookaround, który pozwala nam rozejrzeć się z poziomu aktualnie analizowanego miejsca.
Możemy spojrzeć wstecz za pomocą lookbehind i sprawdzić czy tekst przed spełnia określony przez nas wzorzec. Możemy także spojrzeć w przód lookahead i sprawdzić czy jest spełniony określony przez nas wzorzec. Zobaczmy jak to będzie wyglądało w praktyce.
Lookaround
Do zabawy potrzebujemy jakiegoś tekstu na którym będziemy pracować.
Przykładowy tekst zawierający linki do strony <a href="https://czterytygodnie.pl">czterytygodnie.pl</a> oraz nazwę czterytygodnie.pl
Załóżmy, że chcemy znaleźć wszystkie linki, gdzie tekst to czterytygodnie.pl. Najprościej będzie posłużyć się poniższym wyrażeniem
(<a.*?>)(czterytygodnie\.pl)(<\/a>)
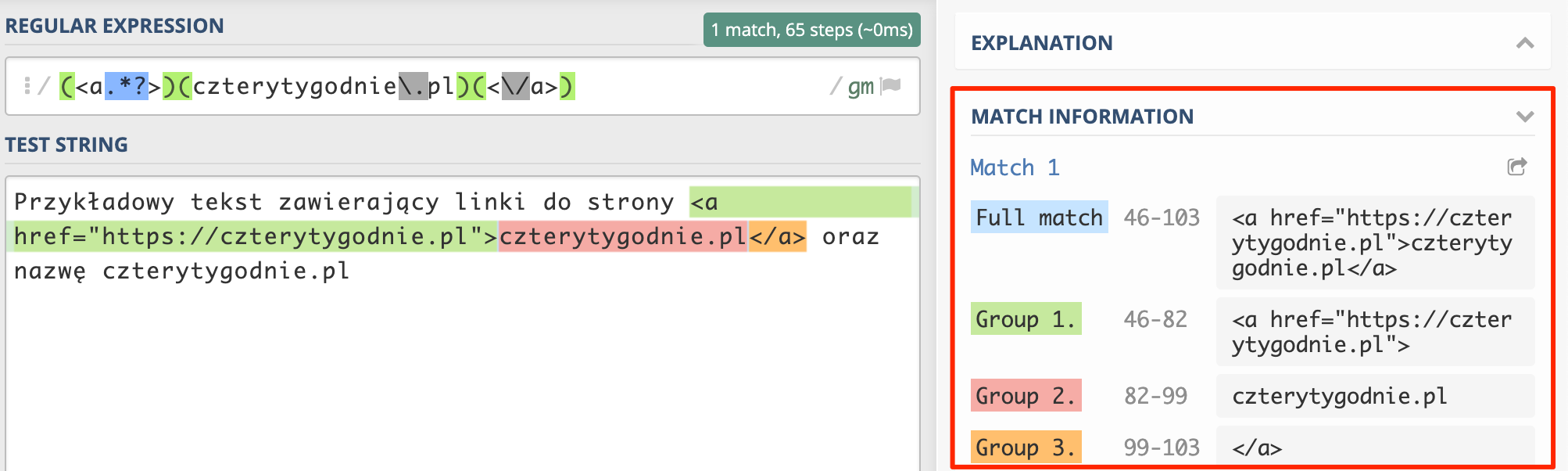
Powyższe zapytanie działa i spełnia nasze założenia, jednak ma drobną wadę. Wyrażenia zwraca zbyt dużą ilości danych.
W związku z czym użyjemy grup nienazwanych, aby z wyników pozbyć się niepotrzebnych grup. Robimy to w bardzo prosty sposób,
mianowicie stawiamy na początku grupy ?:.
(?:<a.*?>)(czterytygodnie\.pl)(?:<\/a>)
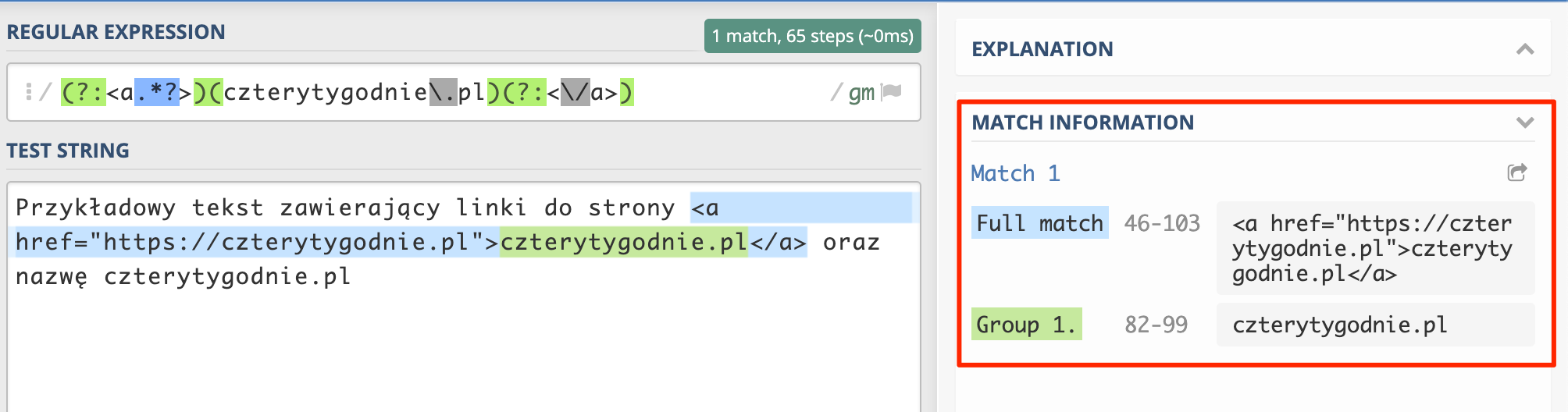
I w tym momencie mamy tylko dwa wyniki. Pierwszy to pełne dopasowanie zawierające znacznik otwierający a, nasz tekst
i znacznik zamykający a. Drugi wynik to grupa przechwytująca zawierająca sam tekst bez znaczników a. I prawdopodobnie
w dużej części przypadków to rozwiązanie będzie wystarczające. Jednak co w przypadku, gdy chcemy, aby pełne dopasowanie
zwracało nam od razu poprawny tekst ??
W takim przypadku możemy właśnie skorzystać z dobrodziejstw lookaround, które pozwala nam na spojrzenie do tyłu lub przodu. Pamiętamy bowiem z wpisu wprowadzającego do wyrażeń regularnych, że gdy jesteśmy w jakimś miejscu tekstu to nie możemy ponownie przeanalizować tego co już zostało przeanalizowane. Tym samym nie spojrzymy wstecz, aby sprawdzić co było wcześniej. Jednak mechanizm lookbehind daje nam taką możliwość.
Lookbehind
Lookbehind, czyli patrzenia w tył pozwoli na wyeliminować znacznik otwierający a. Zapis jest bardzo prosty i sprowadza
się do (?<=) co możemy łatwo zapamiętać jako strzałkę w tył. Zmodyfikujmy więc nasze wyrażenie wprowadzając patrzenie
w tył w pierwszej grupie.
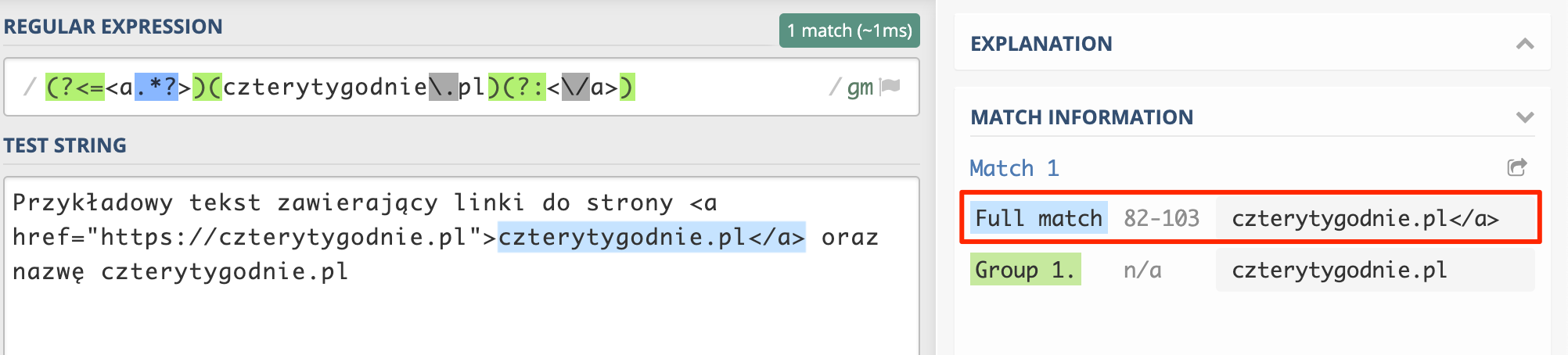
Czyli pierwsza grupa zmienia się z (?:<a.*?>) na (?<=<a.*?>), a całe zapytanie będzie wyglądało następująco:
(?:<a.*?>)(czterytygodnie\.pl)(?:<\/a>)
Co w rezultacie spowoduje usunięcie otwierającego znacznika a w pełnym dopasowaniu.
Lookahead
Skoro mamy z głowy znacznik otwierający to czas pozbyć się znacznika zamykającego. I jak już pewnie się domyślasz
do tego celu wykorzystamy lookahead, czyli patrz w przód. Zapis takiej grupy jest bardzo prosty (?=) i niestety twórcy
nie zachowal konsekwencji bo o ile prościej by było, gdyby to była pełna strzałka w przód ??
Zmieńmy więc naszą grupę, która wyglądała do tej pory (?:<\/a>) na (?=<\/a>). A tym samym nasze wyrażenie
po zmianach będzie wyglądało następująco:
(?<=<a.*?>)(czterytygodnie\.pl)(?=<\/a>)
Co w rezultacie powinno wyeliminować znacznik zamykający a z pełnego dopasowania.
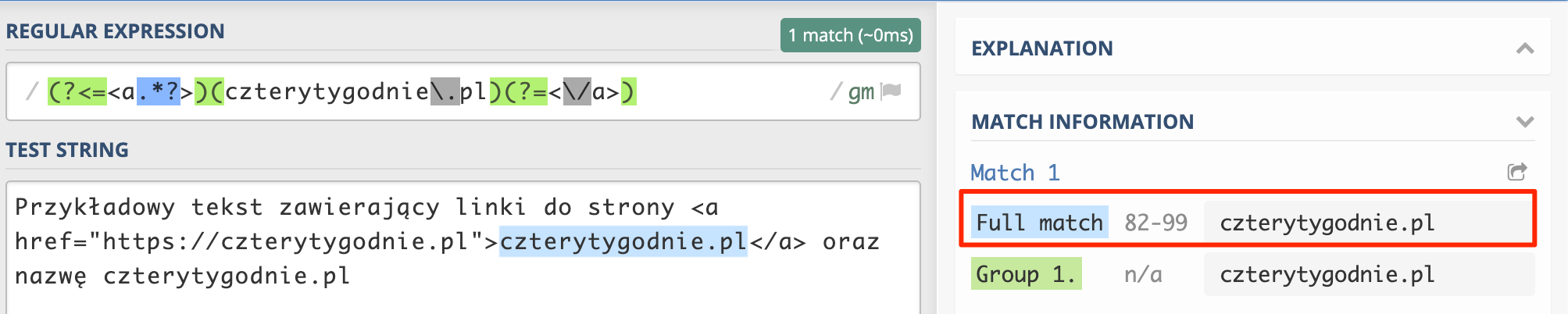
Rzeczywiście się tak stało, czyli sukces 😉 I tak i nie, gdyż w przypadku wyrażeń regularnych i ich implementacji
często okazuje się, że gdzieś jedno rozwiązanie działa, a gdzie indziej już nie. Podobnie jest w tym przypadku.
Otóż w przypadku patrzenia w tył, może się okazać, że nie możecie używać zapisu .* lub co nieco komplikuje nasze rozwiązanie.
Bo, gdybym nie mógł skorzystać z gwiazdki moje wyrażenie wyglądało by jak to poniżej.
(?<=<a href="https:\/\/czterytygodnie.pl">)(czterytygodnie\.pl)(?=<\/a>)
Widzicie, musiałem przepisać całą zawartość znacznika otwierającego a, co utrudnia czytanie wyrażenia.
Więc jak widzicie nie ma róży bez kolców ;)
Negative lookaround
Wiedząc już jak działa rozglądanie się w wyrażeniach regularnych naturalną koleją rzeczy będzie możliwość negacji tego mechanizmu. Zostaniemy przy wyrażeniu, które już opracowaliśmy.
(?<=<a.*?>)(czterytygodnie\.pl)(?=<\/a>)
Tylko tym razem będziemy chcieli, aby tekst czterytygodnie.pl nie był linkiem. Co sprowadzi się do przeprowadzenia negacji dla obu grup. Zanim jednak to zrobimy zobaczmy jak wygląda różnica w zapisie lookbehind i lookahead dla dopasowania i negacji dopasowania.
| loohbehind | lookahead | |
|---|---|---|
| positive | (?<=) | (?=) |
| negative | (?<!) | (?!) |
Jak łatwo zauważyć znak równa się = zmienia się na wykrzyknik !. A skoro wiemy co należy zmienić to czas na wprowadzenie modyfikacji.
(?<!<a.*?>)(czterytygodnie\.pl)(?!<\/a>)
Co w rezultacie rzeczywiście nie powoduje znalezienia tekstu zawierającego się w znacznikach a.
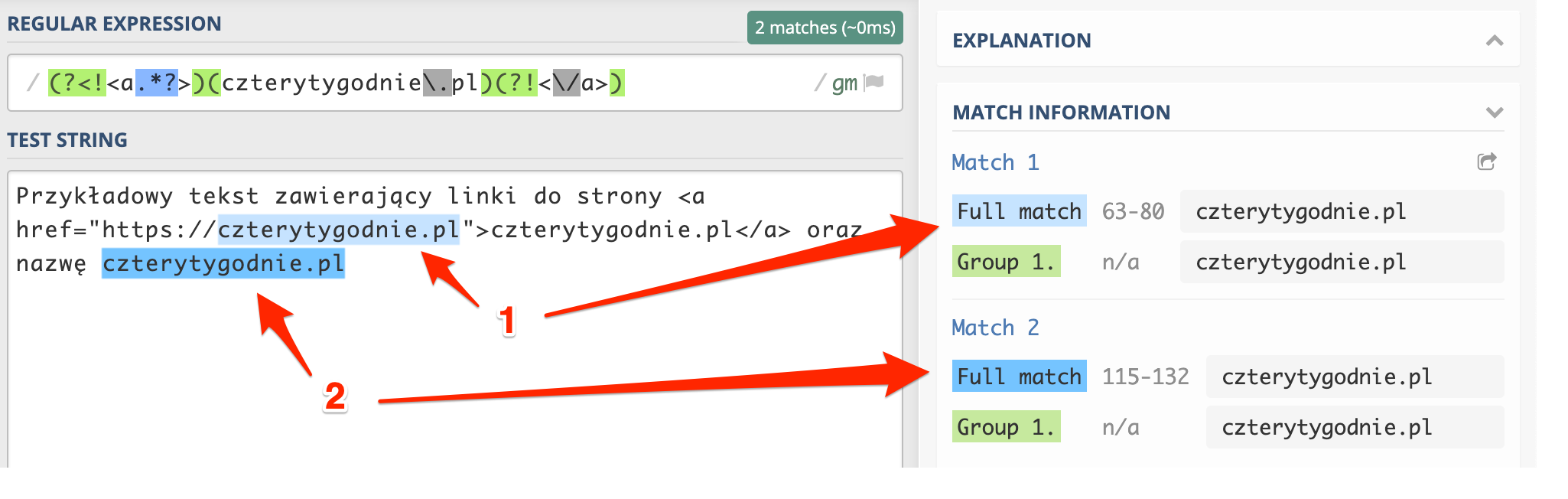
Jedyne z czego możemy być niezadowoleni to zwrócenie dwóch wyników. My moglibyśmy chcieć, aby tekst znajdujący się w atrybucie href nie był znajdowany. Można to bardzo łatwo rozwiązać, ale zostawię was z tym zadaniem ;) Chętni mogą wrzucić rozwiązanie w komentarzu, a na pewno dam znać czy jest ok ;)
Podsumowanie
W ten sposób poznaliśmy mechanizm lookaround, który pozwala nam odnaleźć określony wzorzec w określonym kontekście. Ten mechanizm może się przydać, gdy parsujecie strony internetowe za pomocą wyrażeń regularnych (czego osobiście nie polecam).