
Osierocone gałęzie, czyli słów kilka o orphan branch w GIT

Pracując z GIT-em jesteśmy przyzwyczajeni do pracy z gałęziami. A to za sprawą bardzo prostej idei jaka za nimi stoi. Mamy gałąź główną master i na jej bazie tworzymy nowe gałęzie, które później scalamy. Proste, eleganckie i bardzo wygodne rozwiązanie. Jednak możliwe jest nieco inne podejście do tematu gałęzi. Podejście to pozwala przechowywać kilka różnych “projektów” w jednym repozytorium bez wzajemnych relacji pomiędzy poszczególnymi gałęziami.
Mam nadzieję że wstęp odrobinę Cię zaciekawił. Teraz zastanawiasz się o co właściwie chodzi. Już śpieszę z wyjaśnieniami. Otóż standardowe podejście do gałęzi w GIT jest takie jak widać poniżej.
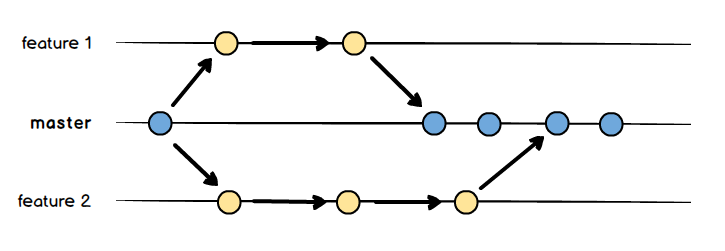
Czyli mamy gałąź główną master na której pracujemy, dodajemy do niej nowe commit-y rozwijające naszą aplikację. Gdy projekt staje się nieco bardziej skomplikowany, a praca nad nowymi funkcjonalnościami zajmuje coraz więcej czasu, zaczynamy pracować na osobnych gałęziach np. feature-1, feature-2 itd. W gałęziach rozwojowych dodajemy kolejne commit-y, a kiedy zakończymy pracę nad daną funkcjonalnością czy poprawką, możemy bezpiecznie scalić gałęzie.
Tak może wyglądać nasz bardzo prosty model pracy. Co jednak gdybyśmy chcieli w jednym repozytorium przechowywać oprócz bazowego projektu, także jego dokumentację oraz stronę internetową. Pewnie było by to problematyczne, ale na potrzeby tego przykładu zobaczymy jak mogło by to wyglądać gdybym zaczynali projekt od zera.
Standardowo zaczynamy od gałęzi master, do której dodajemy np. commit zawierający plik .gitignore w którym eliminujemy katalog naszego IDE.
git add .gitignore
git commit -m "Pierwszy commit"
Pierwsze polecenie dodaje plik .gitignore do repozytorium. Kolejne dodaje commit do repozytorium. W repozytorium będzie wyglądało następująco.

Skoro wiemy, że w repozytorium chcemy przechowywać projekt, dokumentację i stronę. To zakładamy trzy gałęzie, bazujące na gałęzi master i pierwszy commicie.
git branch projekt
git branch dokumentacja
git branch strona_www
Co zmieni wygląd naszego repozytorium w następujący sposób.
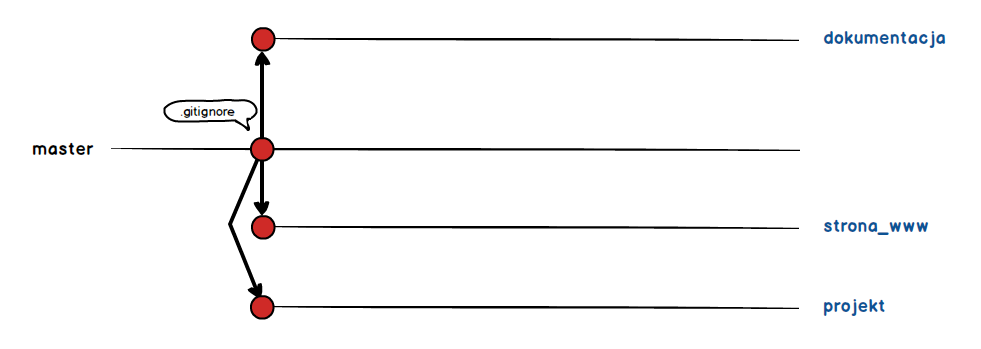
Mamy trzy nowe gałęzie, które bazują na gałęzi master. Zaznaczyłem to poprzez umieszczenie czerwonej kropki, która symbolizuje commit na bazie którego te gałęzie powstały.
Kiedy mamy już utworzone odpowiednie gałęzie, to możemy pracować nad poszczególnymi zadaniami w ramach danej gałęzi. Dzięki temu, że zaczęliśmy od czystego repozytorium to nie mamy bałaganu w historii. A samo repozytorium wygląda dość przejrzyście.
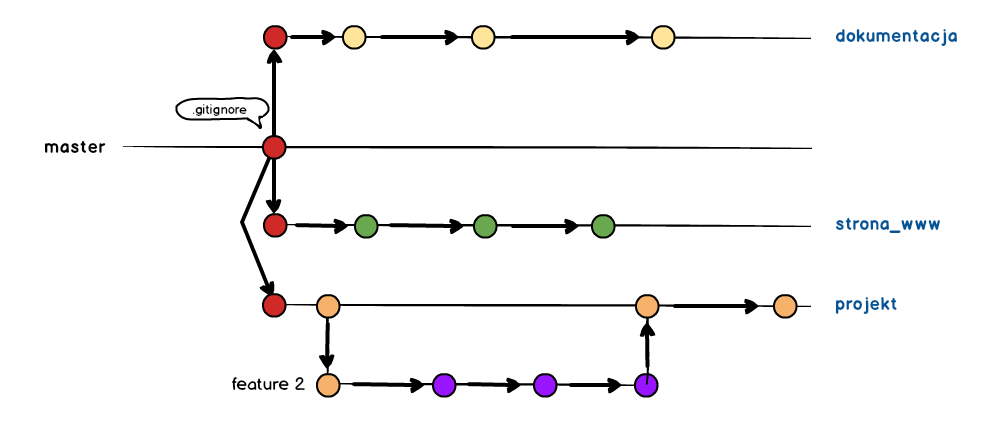
Jedynie dziwnie wygląda pustą gałąź master i zapewne będziemy musieli każdemu tłumaczyć dlaczego nasze repozytorium wygląda tak, a nie inaczej. Ten fakt powoduje, że rozwiązanie to jest mało intuicyjne :( Jednak idea prowadzenia w ten sposób repozytorium jest dość ciekawa, zwłaszcza przy małych projektach.
Orphan branch nadchodzi z pomocą
Można zauważyć, że problem jaki w takim podejściu mamy, to konieczność tworzenia gałęzi na bazie innej gałęzi. Gdybym tylko usunęli powiązania pomiędzy gałęziami to wyglądało by to zdecydowanie lepiej.
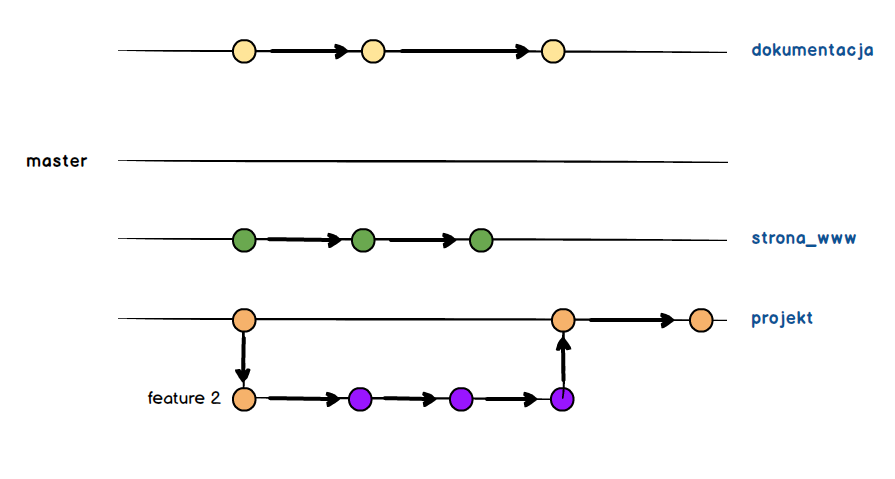
Mamy gałąź master oraz trzy gałęzie dla projektów powiązanych. Jest przejrzyście i swobodnie możemy pracować na poszczególnych gałęziach tak jak robiliśmy to do tej pory. Pytanie tylko czy GIT pozwala na zrobienie czegoś takiego ?
Kiedy zastanowimy się chwilę, to mamy gałąź która nie ma żadnych zależności oraz historii. Jest to gałąź master, w której pierwszy commit nie posiada rodzica (root commit). I teraz chcielibyśmy utworzyć kilka takich gałęzi, pytanie tylko jak ? Odpowiedzią jest orphan branch, czyli gałąź bez historii i powiązań z innymi gałęziami.
Zamiast standardowego polecenia do tworzenia gałęzi, które może wyglądać następująco.
git branch <nazwa_gałęzi>
Lub alternatywne polecenie kiedy chcemy się od razu przełączyć na nowo utworzoną gałąź.
git checkout -b <nazwa_gałęzi>
Teraz nieco zmodyfikujemy nasze drugie polecenie, tak aby tworzyło orphan branch, gdyż po utworzeniu nowej gałęzi będziemy musieli wykonać jedną operację.
git checkout --orphan <nazwa_gałęzi>
Po wykonaniu polecenia, wszystkie pliki z gałęzi na bazie której robiliśmy naszą nową gałąź zostały skopiowane i dodane do staging area. I teraz konieczne będzie usunięcie tych plików, gdyż chcemy w takiej gałęzi przechowywać całkowicie nowy projekt. Do tego celu wykorzystamy polecenie.
git rm -rf .
I teraz możemy zacząć pracować na tak utworzonej gałęzi :)
Do czego wykorzystuję orphan branch ?
Zapewne większość z was pomyśli:
Co ten koleś wymyśla, przecież to się do niczego nie przyda !
I tu was zaskoczę, gdyż o ile w projektach tego nie wykorzystuję ze względu na metodykę GIT Flow z której korzystam. O tyle przy prowadzeniu bloga, jest to bardzo przydatne podejście.
Jak zapewne zauważyliście prowadzę bloga w dość specyficzny sposób. Tworzę ścieżki, a w ramach danych ścieżek robię wpisy, które mają dać możliwość przyswojenia sobie wiedzy z danej dziedziny wiedzy. Mam ścieżkę w której dowiecie się jak obsługiwać ScreenFlow, jest ścieżka omawiająca back-end, gdzie dowiecie się jak pracować z ElasticSearch, RabbitMQ, wyrażeniami regularnymi i wiele więcej.
Takie podejście do pracy oznaczało, że musiałem stworzyć sobie strukturę katalogów odzwierciedlającą te wszystkie ścieżki. I w ramach katalogów musiałem dbać o odpowiedni porządek w plikach. Strukturę tą możecie zobaczyć poniżej.
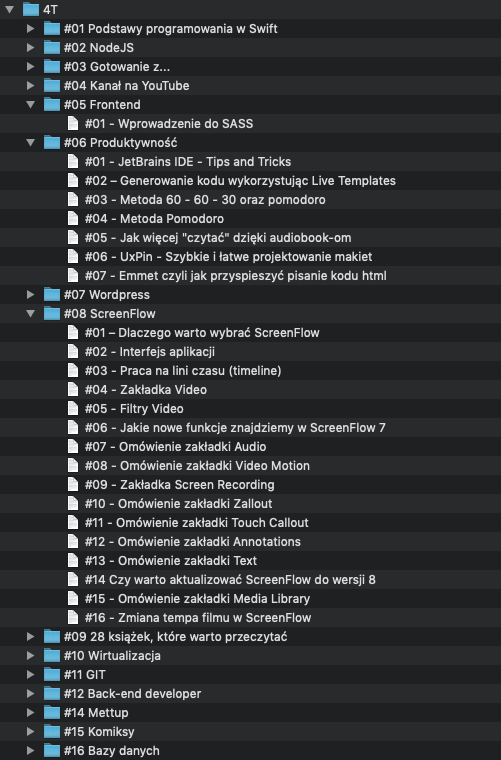
Wszystkie wpisy są zapisane w plikach txt a same wpisy są pisane z wykorzystaniem Markdown. Umożliwia to w bardzo prosty sposób konwersję do dowolnego systemu blogowego. Jednak struktura ta ma ograniczenia, bowiem dodawanie grafik oraz materiałów strasznie utrudniło by zarządzanie. Dlatego zdecydowałem się w pewnym momencie poszukać rozwiązania opartego o system kontroli wersji. Przecież na codzień tworzymy duże ilości kodu, a to przecież taki sam tekst jak wpis na blogu. Dlatego całą tę strukturę przekształciłem na osobne gałęzie w ramach których mogę spokojnie pracować.
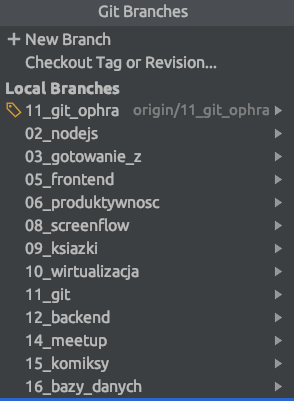
Jak widać mam ścieżki przełożone na gałęzie i kiedy rozpoczynam pracę nad nowym wpisem. To w ramach ścieżki w której znajdzie się wpis tworzę nową gałąź. W ten sposób mogę spokojnie pracować nad wpisem nie martwiąc się o zmiany jakie w nim wprowadzam. Kiedy wpis jest gotowy to scalam gałęzie i mogę publikować go na blogu. A zawartość samego katalogu kiedy pracuję na danej gałęzi jest bardzo minimalistyczna.
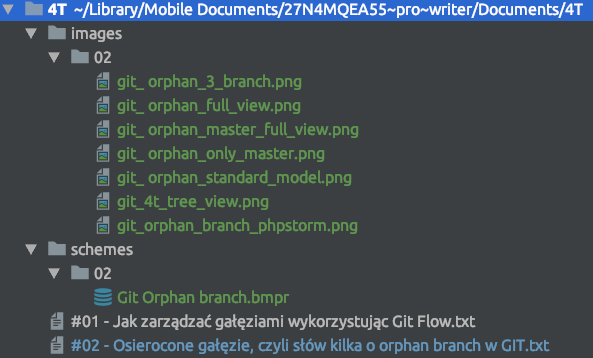
Oczywiście struktura katalogów nie jest ciągle rozwinięta, ale mam nadzieję że widzisz jak prosta ona jest. Takie podejście daje mi możliwość przechowywania wszystkiego w jednym repozytorium. Wraz ze wszystkimi materiałami jakie są mi potrzebne przy tworzeniu wpisów.
Podsumowanie
Mam nadzieję że wpis w wystarczający sposób pokazał Ci możliwości jakie daje ten sposób tworzenia gałęzi. A może już znałeś orphan branch i wykorzystujesz go w jakiś inny sposób ? Jeśli tak to daj znać w komentarzach jak jeszcze można kreatywnie wykorzystać orphan branch :)