
Wprowadzenie do RabbitMQ

Prędzej czy później większość programistów spotyka się z potrzebą kolejkowania zadań. Czy to w przypadku rozsyłania newsletter-ów do klientów, czy też generowania czasochłonnych raportów, plików PDF oraz innych operacji wymagających dłuższego czasu oczekiwania użytkownika.
CRON jest świetnym narzędziem pozwalającym nam obejść problem braku systemu kolejkowania. Zobaczmy jednak jak można go zastąpić na rzecz RabbitMQ.
Wprowadzenie do kolejkowania
Każdy z nas wie czym jest kolejka i nie w jednej takiej człowiek stał ;)

A teraz zamieńmy osoby w tej kolejce np. na maile do wysłania, zaś kasjera na naszą aplikacje rozsyłającą maile znajdujące się w kolejce.

Gdyby powyższa kolejka była realizowana przez CRON-a to nasza aplikacja (kasjer) dostawała by do obsłużenia tylko kilka / kilkanaście maili (klientów). Następnie czekała by bezczynnie minutę, dwie, pięć, zależy od wpisu w CRON-ie. Przy obsłudze kolejki przez RabbitMQ nasza aplikacja nie będzie musiała robić sobie przerw co zdecydowanie przyspieszy obsługę kolejki.
Uproszczony schemat systemu
Zobaczmy zatem jak wygląda uproszczony schemat obsługi maili, gdzie CRON-a zastępujemy systemem kolejkowania.
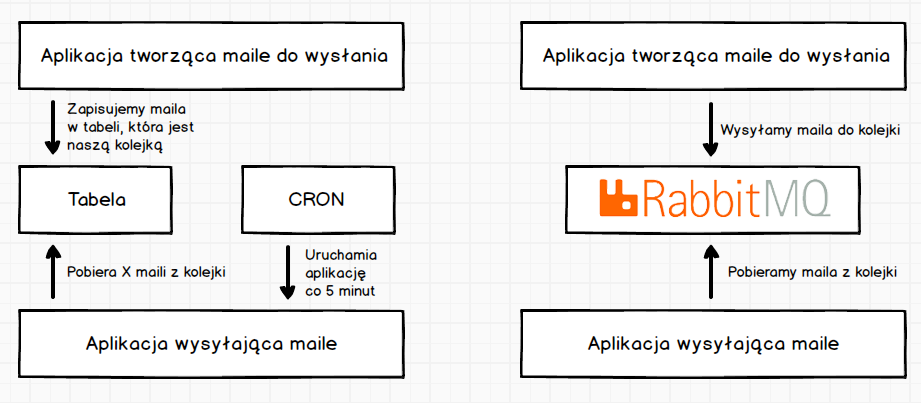
Obok siebie mamy porównanie realizację kolejki przez CRON-a oraz RabbitMQ. Na pierwszy rzut oka widać, że zastępując CRON-a Rabbit-em upraszczamy system. Dodatkową korzyścią jest uniezależnienie się od schematu bazy danych przez aplikację rozsyłającą nasze maile.
Przyjrzyjmy się zatem schematowi systemu wykorzystującego Rabbit-a.
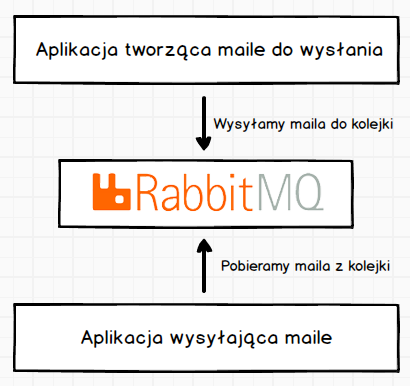
Mamy trzy elementy, pierwszy to aplikacja tworząca maile do wysłania i wysyłająca tę informację do Rabbit-a. Aplikację taką nazywamy producentem (producer).
Drugi element to sam system kolejkowania, gdzie otrzymuje on wiadomość od systemu tworzącego maile i umieszcza tę informację w kolejce.
Ostatni element to aplikacja przetwarzająca zawartość kolejki. Łączy się ona z Rabbit-em i pobiera zadania z kolejki. Taką aplikację nazywamy konsumentem (consumer).
Obsługa kolejki przez RabbitMQ
Już wiemy, że system wysyłający zadanie do Rabbit-a nazywamy producentem. Oczywiście system może produkować wiele zadań lub wiele systemów może przesyłać zadania do jednego systemu kolejkowania.
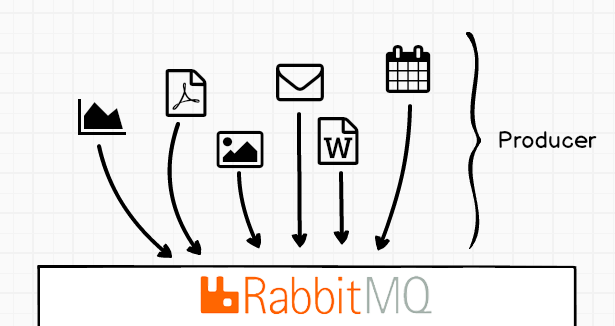
Gdy zadania trafiają do Rabbit-a zostają przypisane do określonej centrali wiadomości (exchange). Przypisanie to następuje poprzez podanie przez producenta nazwy centrali wiadomości do której chce wysłać zadanie.
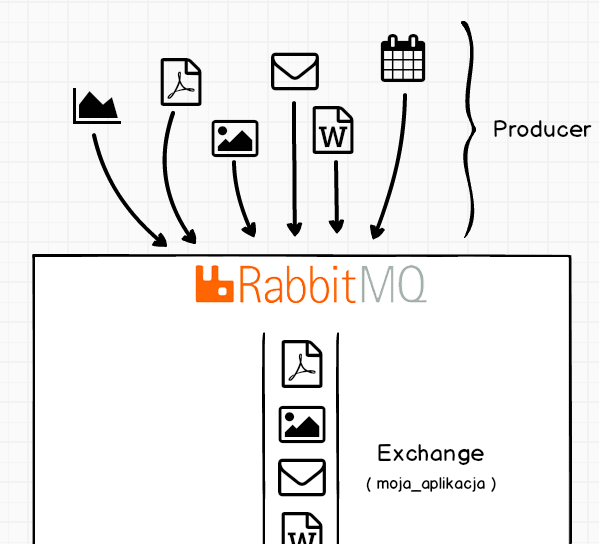
W tym przypadku wszyscy moi producenci wysyłają zadania do centrali wiadomości o nazwie moja_aplikacja. Jednak chciałbym, aby zostały utworzone osobne kolejki dla każdego typu zadania. Bowiem inaczej będę zajmował się generowaniem raportów, a inaczej wysyłaniem newsletter-a. Do tego celu służy mechanizm przypisywania (binding) elementów znajdujących się w centrali wiadomości do określonej kolejki.
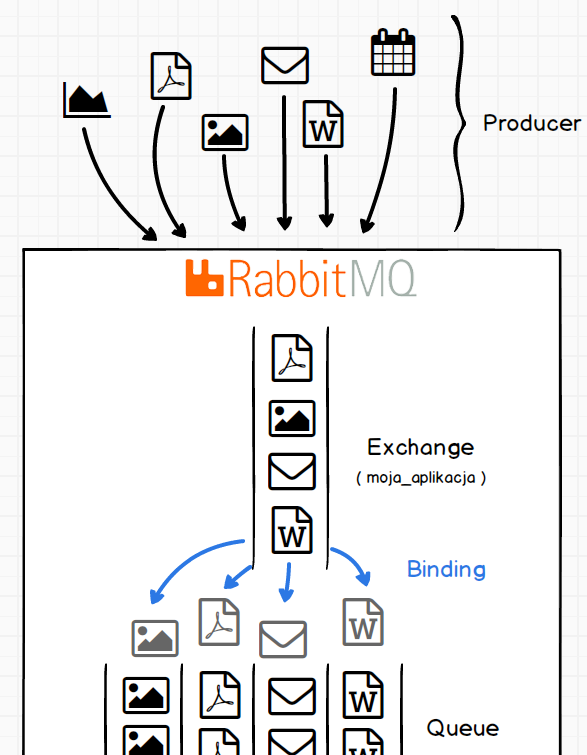
Skoro zadania trafiły do określonych kolejek to należało by je jakoś obsłużyć. Tym zadaniem zajmują się konsumenci (consumer) w naszym przypadku będą to aplikacje do wysyłania maili, generowania raportów itd.
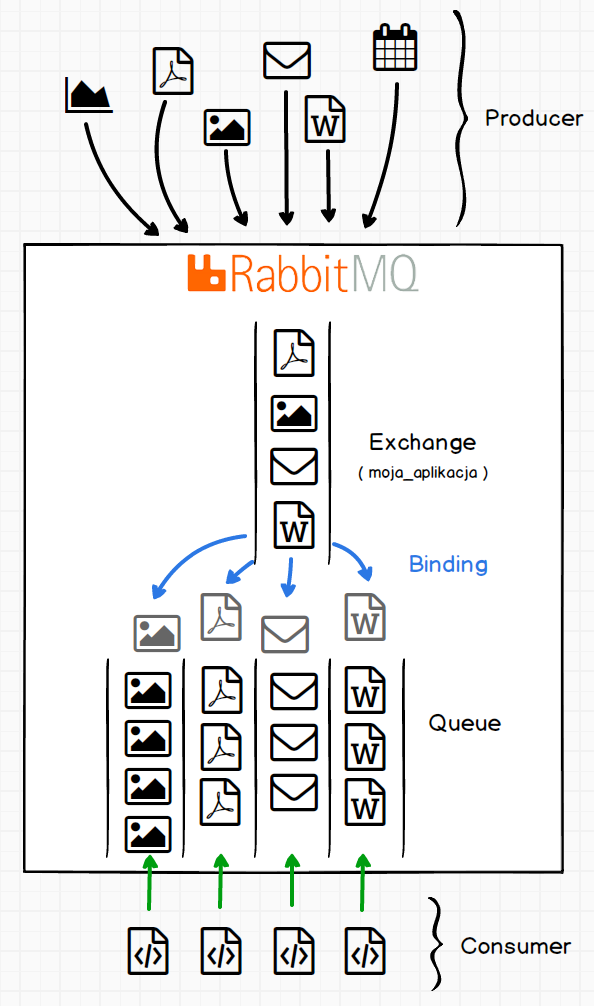
Konsumenci podłączają się do Rabbit-a i pobierają dane z odpowiednich kolejek. Zamykając tym samym cały cykl kolejkowania zadań z wykorzystaniem serwera RabbitMQ.
Opis ten jest dużym uproszczeniem całego procesu bez zagłębiania się w szczegóły dotyczących centrali wiadomości, sposobów przypisywania zadań do kolejek i wielu innych rzeczy. Jednak nie martwcie się będziemy zajmować się tym w kolejnych wpisach tej serii, dziś jedynie chciałem przybliżyć wam koncepcję do szczegółów przejdziemy później ;)
Instalacja RabbitMQ
W zależności od systemu operacyjnego na którym chcemy zainstalować RabbitMQ może to wyglądać nieco inaczej. Dlatego poniżej opisałem instalację opartą o Ubuntu, Mac OS X oraz Docker-a co w większości wypadków powinno być wystarczające.
Jeśli korzystacie z innej dystrybucji linux-a to zapewne w repozytoriach znajdziecie odpowiednie paczki. Ewentualnie możecie przejść na stronę https://www.rabbitmq.com/download.html skąd możecie pobrać gotowe paczki lub źródła do samodzielnej kompilacji.
Mac OS X
Jeśli korzystacie z systemu z logiem nadgryzionego jabłka to zawsze zalecam używanie menadżera pakietów Homebrew, który bardzo ułatwia życie. Jeśli z niego nie korzystacie to zapraszam na stronę https://www.rabbitmq.com/install-standalone-mac.html skąd możecie pobrać odpowiednie paczki.
Jeśli zaś korzystacie z Homebrew to zaczynamy instalację od uruchomienia konsoli i wpisania polecenia:
brew install rabbitmq
W rezultacie powinniście zobaczyć podobne podsumowanie u siebie:

Po instalacji, aby sprawdzić czy mamy działający serwer wystarczy wejść w przeglądarkę i otworzyć adres http://localhost:15672 pod którym powinien pojawić się ekran logowania.
Domyślny login i hasło to guest, które zalecał bym zmienić ;)
Ubuntu
Jak to bywa w linuksie opartym o Debian-a instalacja sprowadza się do instalacji odpowiedniej paczki z repozytorium. W tym przypadku nazywa się ona rabbitmq-server i instalujemy ją poleceniem:
sudo apt-get install rabbitmq-server
Co powinno skutkować zainstalowaniem RabbitMQ oraz zależności. Po instalacji możemy przetestować działanie serwera wywołując polecenie z poziomu linii komend:
sudo rabbitmqctl status
Po uruchomieniu polecenia zobaczycie spory zbiór informacji na temat serwera RabbitMQ. Będzie on zawierał informacje o zużyciu pamięci, czasie pracy serwera, wykorzystaniu przestrzeni dyskowej i wielu innych rzeczach.
Pomimo że instalacja ta daje nam juz możliwość pracy z serwerem RabbitMQ to przydatnym elementem jest interfejs webowy, który pozwala na łatwe zarządzanie i podglądanie tego co się z serwerem dzieje. Instalacja jest banalna i sprowadza się do wydania trzech poleceń:
Zatrzymanie aktualnie działającego serwera:
sudo service rabbitmq-server stop
Włączenie panelu zarządzającego RabbitMQ
sudo rabbitmq-plugins enable rabbitmq_management
Polecenie spowoduje włączenie 6 plugin-ów:

I ostatnie, to ponowne uruchomienie serwera:
sudo service rabbitmq-server start
Teraz możemy cieszyć się Rabbit-em z panelem do jego zarządzania ;)
Docker
W przypadku Docker-a mamy w oficjalnym repozytorium gotowy obraz do pobrania pod adresem: [https://hub.docker.com//rabbitmq/](https://hub.docker.com//rabbitmq/). W zależności od naszych potrzeb możemy wykorzystać obraz bez menadżera rabbitmq:3 lub obraz z menadżerem rabbitmq:3-management. Dla ułatwienia przygotowałem bardzo prosty plik docker-compose.yml
version: '2'
services:
rabbit:
image: rabbitmq:3-management
ports:
- "5672:5672"
- "15672:15672"
Jak widać został użyty obraz z menadżerem oraz ustawiono dwa przekierowania portów. Jeden dla menadżera 15678 oraz drugi dla samego serwera 5672. Teraz wystarczy uruchomić naszego Rabbit-a poleceniem:
docker-compose up
I jeśli wszystko przebiegło prawidłowo to powinieneś pod adresem http://localhost:15672
Rozpoczynamy pracę z RabbitMQ
Skoro teorię mamy już za sobą, serwer Rabbit-a zainstalowany czas przetestować kolejkowanie w praktyce. Do tego celu posłużymy się dwoma skryptami napisanymi w PHP. Jednak przed rozpoczęciem pisania skryptów upewnij się, że masz zainstalowane pakiety php7.0-mbstring oraz php7.0-bcmath.
Piszemy producenta (producer)
Pierwszy skrypt będzie tworzył zadania i dodawał je bezpośrednio do kolejki Rabbit-a pomijając centralę wiadomości. Jest to możliwe pod warunkiem, że wiemy do jakiej kolejki chcemy dodać zadania lub stworzymy ją dynamicznie. My wybierzemy drugą opcję i stworzymy sobie kolejkę ;)
Zaczynamy od instalacji pakietu dającego nam łatwą możliwość pracy z Rabbit-em z poziomy php. Do tego celu posłużymy się composer-em:
php composer.phar require php-amqplib/php-amqplib
Teraz możemy w łatwy sposób pracować z serwerem. Zaczynamy od importu potrzebnych skryptów:
require_once __DIR__ . '/vendor/autoload.php';
use PhpAmqpLib\Connection\AMQPStreamConnection;
use PhpAmqpLib\Message\AMQPMessage;
Następnie definiujemy stałe dla połączenia z serwerem oraz nazwę kolejki.
const RABBITMQ_HOST = 'localhost';
const RABBITMQ_PORT = '5672';
const RABBITMQ_USERNAME = 'guest';
const RABBITMQ_PASSWORD = 'guest';
const RABBITMQ_QUEUE_NAME = 'moja_kolejka';
Teraz już możemy nawiązać połączenie i otworzyć kanał komunikacyjny. Standardowo przy pracy z Rabbit-em nawiązujemy połączenie z serwerem tylko jeden raz, gdyż operacja ta jest kosztowna. Po nawiązaniu połączenia otwieramy kanał komunikacyjny, który po zakończeniu operacji zamykamy.
$connection = new AMQPStreamConnection(
RABBITMQ_HOST,
RABBITMQ_PORT,
RABBITMQ_USERNAME,
RABBITMQ_PASSWORD
);
$channel = $connection->channel();
Teraz pozostaje nam zdefiniować kolejkę co robimy w następujący sposób:
$channel->queue_declare(
$queue = RABBITMQ_QUEUE_NAME, // nazwa kolejki
$passive = false, // passive
$durable = true, // durable
$exclusive = false, // exclusive
$auto_delete = false, // auto deete
$nowait = false, // nowait
$arguments = null, // arguments
$ticket = null // ticket
);
Kiedy mamy kolejkę w systemie możemy przejść do wysyłania zadań do tej kolejki. Najlepszym sposobem, aby to zobrazować będzie nieskończona pętla wysyłająca zadania do kolejki. Jej implementacja może wyglądać następująco:
$taskId = 0;
while (true)
{
$taskId++;
$messageBody = 'Zadanie #'.$taskId;
$msg = new AMQPMessage($messageBody);
$channel->basic_publish($msg, '', RABBITMQ_QUEUE_NAME);
echo $messageBody . PHP_EOL;
sleep(1);
}
Zmienna $taskId przechowuje identyfikator który co przebieg pętli jest zwiększany dzięki czemu lepiej będzie widać które zadanie zostało obsłużone. Następnie tworzymy nową wiadomość i ją wysyłamy metodą basic_publish do określonej kolejki.
Nasz producent w działaniu:
Piszemy konsumenta (consumer)
W przypadku konsumenta początek jest dokładnie taki sam jak w przypadku producenta. Łączymy się z serwerem oraz otwieramy kanał komunikacji.
require_once __DIR__ . '/vendor/autoload.php';
use PhpAmqpLib\Connection\AMQPStreamConnection;
const RABBITMQ_HOST = 'localhost';
const RABBITMQ_PORT = '5672';
const RABBITMQ_USERNAME = 'guest';
const RABBITMQ_PASSWORD = 'guest';
const RABBITMQ_QUEUE_NAME = 'moja_kolejka';
$connection = new AMQPStreamConnection(
RABBITMQ_HOST,
RABBITMQ_PORT,
RABBITMQ_USERNAME,
RABBITMQ_PASSWORD
);
$channel = $connection->channel();
Teraz czas na funkcję, która będzie przetwarzała zadania z naszej kolejki.
$callback = function($msg) {
echo " [x] Received: ", $msg->body, "\n";
sleep(1);
};
W tym przypadku przypisujemy do zmiennej funkcję anonimową, która wypisuje zawartość zadania. Dla naszych zadań będzie to jedynie tekst, ale możemy tam zakodować JSON-a, XML-a lub tekst w innym formacie. Gdy mamy funkcję przetwarzającą zadania czas przypisać ją jako konsumenta poprzez metodę basic_consume:
$channel->basic_consume(
RABBITMQ_QUEUE_NAME,
'',
false,
true,
false,
false,
$callback
);
Robimy to w formie funkcji anonimowej, gdyż zadania z serwera są dostarczane nam asynchronicznie. W związku z czym wywołanie nastąpi dopiero, gdy serwer prześle do nas zadanie. My zaś musimy na owe zadania oczekiwać więc mamy prostą pętelkę ;)
while (count($channel->callbacks))
{
$channel->wait();
}
Zobaczmy jak działa w akcji nasz konsument.
Producent i konsument w działaniu
Podglądaliśmy jak działa producent i konsument obsługując kolejkę. Zobaczmy jak działają wspólnie:
Jeśli chcecie potestować to lokalnie to kod producenta i konsumenta są dostępne na GitHub
![]()
Podsumowanie
Systemy kolejkowania potrafią nam znacznie uprościć życie. Nie ma potrzeby sztucznej implementacji kolejek w systemie, wystarczy w prosty sposób przesłać zadanie do systemu kolejkowania. Nie musimy już się matrwić o zmiany w strukturze bazy danych, które mogą wpłynąć na kolejkowanie zadań. Po prostu życie staje się prostsze ;)
Mam nadzieję, że tym wstępem zachęciłem Cię do zapoznania się z RabbitMQ, a może używasz czegoś innego, lepszego ?? Podziel się tą informacją w komentarzu, może porównamy oba rozwiązania :)