
Wprowadzenie do REDIS-a

Bazy NoSQL istnieją już od dawna w świecie IT. Początkowo były traktowane jako ciekawostka, później zachwycaliśmy się ich wydajnością i stosowaliśmy w małych projektach. Lecz obecnie są to dojrzałe rozwiązania, które widzimy na codzień w dużych projektach gdzie wydajność jest stawiana na pierwszym miejscu.
Czym jest REDIS ?
REDIS jest bazą danych typu klucz – wartość, która przechowuje dane w pamięci RAM co czyni ją ekstremalnie wydajną. Jednak za wydajnością stoi ulotność danych, co w pewnych przypadkach jest niedopuszczalne. REDIS umożliwia nam w takim przypadku skonfigurowanie bazy w ten sposób żeby co pewien czas zrzucała dane do pliku na dysku. Ma to oczywiście pewne konsekwencje, a w tym przypadku będzie to zmniejszenie wydajności.
Zastosowanie
REDIS ma wiele zastosowań, ale postara się wam powiedzieć o tych z którymi możecie spotkać się najczęściej.
- Cache, jest to najczęstsze zastosowanie bazy ze względu na bardzo dużą wydajność. Dodatkowo dochodzi fakt, że utrata danych z cache nie jest dla nas bardzo bolesna. Zawsze możemy dodać dane ponownie 😉
- Obsługa kolejek, jest to nieco rzadziej spotykane rozwiązanie. Gdy myślimy o kolejkach to raczej do głowy przychodzi nam RabbitMQ, a nie REDIS. Jednak jeśli potrzebujecie bardzo prostego systemu kolejkowania to śmiało możecie skorzystać z REDIS-a.
- Przechowywanie sesji użytkowników, tutaj także jest to rozwiązanie alternatywne w stosunku do przechowywania sesji w plikach lub bazie danych. A w połączeniu z TTL mamy świetny sposób obsługi sesji oraz ich przedawniania.
- TTL Cache, czyli cache z możliwością ustawienia jak długo dany klucz ma być ważny. Kiedy jego ważność się skończy jest on usuwany, czyli bardzo łatwo możemy np. utrzymywać sesje użytkowników.
Środowisko testowe
Do dalszego poznawania REDIS-a przyda nam się środowisko w którym będziemy mogli się nieco pobawić. Jako że ja na codzień pracuję na Mackbook-u oraz różnych dystrybucjach Linux-a, to proponuję wam użycie Docker-a lub Linux-a. W przypadku Windowsa możecie albo zainstalować Docker-a lub Linux-a na wirtualnej maszynie.
Docker
Tutaj jest bardzo prosto ;) Cała operacja sprowadza się do uruchomienia demona Docker-a, a następnie w terminalu wpisujemy poniższe polecenie.
docker run --name testowy-redis -d redis
Powyższe polecenie uruchomi nam REDIS-a w kontenerze o nazwie testowy-redis. Po jego wykonaniu powinniśmy zobaczyć coś podobnego do poniższego komunikatu.

Dodatkowo możemy się upewnić czy rzeczywiście kontener działa wpisując polecenie.
docker ps
W odpowiedzi powinniśmy otrzymać listę działających kontenerów, w tym naszego o nazwie testowy-redis.

Kontener działa i możemy zobaczyć jak się do niego podłączyć i zacząć korzystać z REDIS-a.
Linux
Dystrybucji Linux-a jest bardzo dużo i nie chcę tutaj skupiać się na różnicach w instalacji i wersjach REDIS-a. Dlatego na potrzeby tego wpisu będę używał dystrybucji Ubuntu 18.04.
Instalacja jest bardzo prosta i sprowadza się do wydania poniższego polecenia.
sudo apt-get install redis-server
Po zakończeniu instalacji jeśli nie pojawił się żaden komunikat o błędzie, to REDIS powinien zostać zainstalowany i uruchomiony. Sprawdzamy to poniższym poleceniem.
sudo systemctl status redis
W rezultacie powinniśmy otrzymać poniższy komunikat.
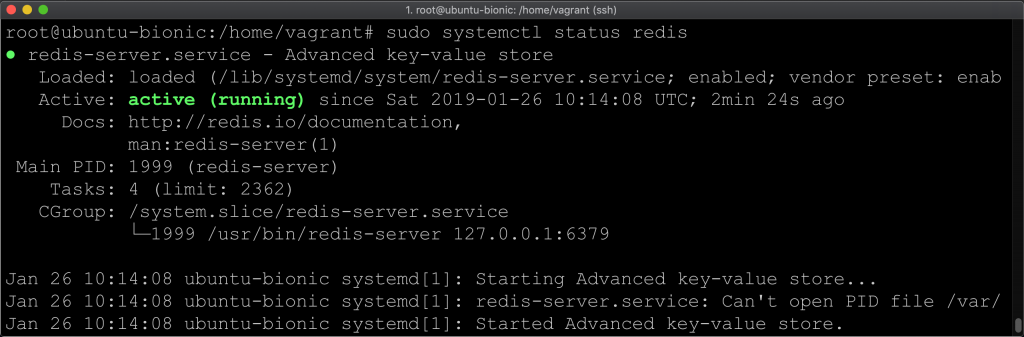
Gdyby jednak pojawił się jakiś problem, to dajcie znać w komentarzach, postaram się pomóc.
Podłączenie do serwera REDIS
Do REDIS-a możemy podłączyć się standardowo na porcie 6379. W zależności od języka programowania mamy do dyspozycji wiele bibliotek. Jednak my, aby uniezależnić się na chwilę od samego języka programowania posłużymy się dostarczonym klientem.
Klient REDIS-a
Wraz z serwerem REDIS-a jest dostarczana aplikacja kliencka, którą możemy wykorzystać do testów. W zależności od wybranego sposobu instalacji serwera będziemy nieco inaczej uruchamiali klienta.
Docker
W przypadku gdy wykorzystujemy konteneryzację i nasz serwer znajduje się w kontenerze. To uruchomienie sprowadza się do wpisania poniższego polecenia w terminalu.
docker run -it --link testowy-redis:redis --rm redis redis-cli -h redis -p 6379
W wyniku działania tego polecenia, w terminalu powinna ukazać się nam nowa linia komend aplikacji klienckiej.

Teraz możemy zacząć testować możliwości serwera.
Linux
Po zainstalowaniu serwera REDIS-a w Linuksie, powinniśmy mieć do dyspozycji dodatkową komendę.
sudo redis-cli
Po wywołaniu polecenia naszym oczą powinna pojawić się linia komend klienta REDIS-a.

Teraz możemy zacząć testować możliwości serwera.
Podstawowe polecenia
Skoro mamy już serwer oraz aplikację pozwalającą nam na pracę z REDIS-em to czas poznać podstawowe polecenia.
SET key
Ustawia wartość określonemu kluczowi.
SET country Poland
W tym przypadku klucz country będzie zawierał wartość Poland. Wykonanie polecenia powinno spowodować zwrócenie komunikatu o powodzeniu zapisania danych w bazie.

Jak widać ustawianie wartości jest bardzo proste, jednak SET ma nieco większe możliwości.
SET key value [EX seconds] [PX milliseconds] [NX XX]
Parametry EX i PX są odpowiedzialne za ustawienie czasu po jakim wygaśnie klucz. Jedyna różnica pomiędzy nimi to, że w parametrze EX czas podajemy w sekundach, a w PX w milisekundach.
SET user_1234 "Marcin Lewandowski" EX 3600
Powyższe polecenie spowoduje ustawienie czasu życia klucza user_1234 na 3600 sekund. Po tym czasie klucz straci ważność i zostanie usunięty. Oczywiście przechowywanie imienia i nazwiska nie ma większego sensu, jednak gdyby tam był identyfikator sesji to co innego ;)
Dwa ostatnie parametry NX i XX są odpowiedzialne za warunkowe ustawianie wartości. Czyli jeśli na końcu dodamy parametr NX, to klucz zostanie ustawiony jeśli wcześniej nie istniał. I jak się już pewnie domyślacie parametr XX ustawia wartość klucza, gdy ten był już zdefiniowany.
Wiemy jak parametry NX i XX działają, ale co w przypadku, gdy próbujemy ustawić coś nieprawidłowo. Chociażby klucz user_1234, który zdefiniowaliśmy wcześniej spróbujemy zaktualizować z parametrem NX. Co powinno być niemożliwe, gdyż klucz istnieje.
SET user_1234 "Jan Kowalski" NX
I w rezultacie otrzymamy komunikat (nil) jak widać to poniżej.

GET key
Odczytuje wartość pod podanym kluczem.
GET country
Wykonanie polecenia spowoduje zwrócenie nam wartości znajdującej się pod podanym kluczem.

W przypadku gdybym odwołali się do nieistniejącego klucza, to zostanie nam zwrócony błąd (nil).

DEL key
Polecenie usuwa klucz.
DEL country
Usuwamy klucz country, jeśli wszystko przebiegnie prawidłowo to zostanie nam zwrócony komunikat (integer) 1.

W przypadku, gdy operacja się nie powiedzie z jakiegokolwiek powodu to otrzymamy komunikat (integer) 0.

DUMP key
Pobiera zserializowaną wartość.
DUMP country
W rezultacie otrzymamy zserializowaną wartość słowa Poland.
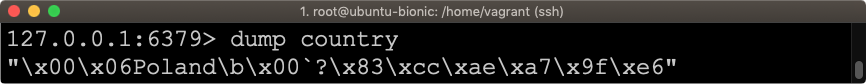
EXISTS key
Sprawdza czy istnieje określony klucz lub cała lista kluczy.
EXISTS country
Polecenie to zwróci nam wartość (integer) 1, gdy klucz istnieje. Kiedy klucz nie zostanie znaleziony otrzymamy wartość (integer) 0.

Oprócz sprawdzenia istnienia pojedynczego klucza, możemy przekazać całą listę kluczy.
EXISTS country test user_1234
W tym przypadku u mnie w bazie istnieje klucz country oraz user_1234. Zobaczmy co zostanie zwrócone.

Została zwrócona informacja ile kluczy istnieje. W tym przypadku są to dwa klucze stąd odpowiedź (integer) 2. I pewnie już widzicie wadę tego rozwiązania. Nie wiemy które klucze istnieją, a które nie :(
EXPIRE key seconds
Ustawia po jakim czasie klucz wraz z wartością mają zostać usunięte.
EXPIRE user_1234 60
Powyższe polecenie ustawia czas na 60 sekund dla klucza user_1234. W moim przypadku klucz ten odpowiada użytkownikowi o identyfikatorze 1234 i przechowywana jest tam jego sesja.

EXPIREAT key timestamp
Ustawia po jakim czasie klucz wraz z wartością mają zostać usunięte. Czyli działa dokładnie jak EXPIRE czas podajemy w formacie Unix.
EXPIREAT user_1234 1577836800
Rozwiązanie to w niektórych przypadkach jest wygodniejsze od komendy EXPIRE, gdyż pozwala nam na podanie konkretnej daty i czasu wygaśnięcia klucza.

Operacja się powiodła o czym świadczy zwrócona wartość (integer) 1. Ustawiony czas 1577836800 jest odpowiednikiem daty 2020-01-01 00:00:00 UTC. Należy jednak uważać, gdyż ustawienie daty z przeszłości spowoduje usunięcie klucza.
KEYS pattern
Wyszukuje wszystkie klucze pasujące do podanego wzorca.
KEYS user_*
Rezultatem działania polecenia jest zwrócenie listy kluczy pasujących do zdefiniowanego wzorca.

W przypadku gdy nic nie zostanie znalezione otrzymamy komunikat (empty list or set).
![]()
SELECT db
Polecenie pozwala nam przełączać się pomiędzy bazami w REDIS-ie. Domyślnie znajdujemy się w bazie onaczonej numerem 0.
SELECT 1
Zmieniamy bazę wpisując numer indeksu, a w odpowiedzi otrzymujemy komunikat OK.

Dodatkowo widzimy, że po numerze portu pojawił się numer indeksu bazy na której się znajdujemy.
MOVE key db
Przenosi klucz do bazy danych o podanym numerze.
MOVE user_1234 1
Gdy operacja przenoszenia klucza user_1234 się powiedzie, to otrzymamy odpowiedź (integer) 1.

Oczywiście gdy klucz który chcemy przenieść nie istnieje lub podaliśmy zamiast numeru bazy jakąś nazwę, to operacja przenoszenia ma prawo się nie powieść.
TTL key / PTTL key
Oba polecenia zwracają informacje o pozostałym czasie do wygaśnięcia klucza. TTL zwraca czas w sekundach, PTTL w milisekundach.
TTL user_1234
Gdy zostanie zwrócona wartość -1 oznacza to, że klucz nie ma ustawionej wartości wygaszenia. Możliwy jest także przypadek w którym zostanie zwrócona wartość -2, gdy klucz nie istnieje. W pozostałych przypadkach otrzymamy czas pozostały do wygaśnięcia klucza.

PERSIST key
Wyłącza wygaszanie klucza, a mówiąc prościej usuwa czas wygaśnięcia klucza.
PERSIST user_1235
Żeby lepiej zobrazować całość ustawimy czas wygaśnięcia klucza user_1235 na 120 sekund. Następnie sprawdzimy ile czasu pozostało i usuniemy czas wygaśnięcia. Po czym jeszcze raz sprawdzimy ile pozostało czasu do wygaśnięcia.
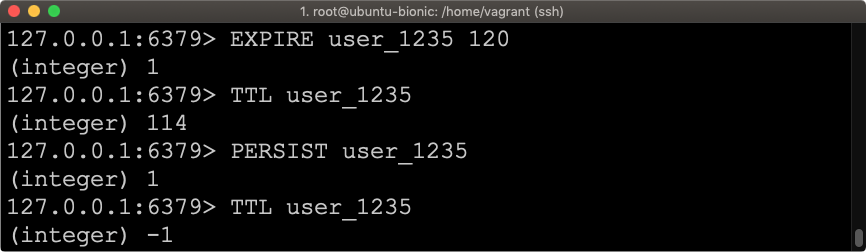
Na samym końcu widzimy, że polecenie TTL zwraca wartość -1. Co świadczy, że polecenie PERSIST rzeczywiście wyłączyło wygaszenie klucza.
RANDOMKEY
Zwraca losowy klucz z bazy danych. W przypadku gdy baza jest pusta zwracana jest wartość (nil).
RANDOMKEY
RENAME key newkey
Zmienia nazwę klucz.
RENAME contry countries

TYPE key
Zwraca typ wartości przechowywanej pod określonym kluczem.
TYPE countries
Do tej pory operowaliśmy tylko na ciągach znaków w związku z czym poniższy wynik nie będzie dla nas zaskoczeniem.

String nie jest jedynym typem jaki może przechowywać REDIS. A w zależności od typu możemy dodatkowo posługiwać się specyficznymi poleceniami dla danego typu danych.
Typy danych
Do tej pory operowaliśmy na ciągach znaków czyli stringach. Jednak nie jest to jedyny typ obsługiwany przez REDIS-a. Dzięki zaawansowanej obsłudze typów w REDIS-ie mamy dodatkowe polecenia specyficzne dla każdego typu co znacznie zwiększa możliwości tej bazy danych.
Przedstawiane listy poleceń przy każdym typie nie będą kompletnymi listami poleceń dostępnymi dla każdego typu. Wszystkie dostępne polecenia znajdziecie na stronie https://redis.io/commands
Strings - ciągi znaków
Ciągi znaków to chyba najczęściej wykorzystywany typ danych. Prawdopodobnie dlatego, że mamy możliwość umieszczenia tam JSON-a, XML-a i dowolny inny tekst co powoduje, że nie mamy prawie żadnych ograniczeń. Dodatkowo REDIS nie analizuje w żaden sposób zawartości przesyłanych danych co gwarantuje nam ich niezmienność.
Dla każdego typu danych znajdziemy polecenia, które są przeznaczona dla danego typu. Poniżej kilka przykładowych poleceń dla ciągów znaków.
| Polecenie | Opis |
| STRLEN key | zwraca długość ciągu znaków |
| APPEND key value | dodaje tekst do istniejącego klucza |
| MSET key value [key value…] | dodaje / aktualizuje wiele kluczy jednocześnie wraz z wartościami |
| MGET key1 [key2…] | zwraca wartość wszystkich kluczy jakie podaliśmy |
| GETRANGE key start end | zwraca fragment ciągu znaków od pozycji start do pozycji end |
| GETSET key value | ustawia nową wartość oraz zwraca poprzednią |
| INCR key | zwiększa wartość o 1 |
| DECR key | zmniejsza wartość o 1 |
Lists – listy
Z listą się już zetknęliśmy przy okazji polecenia KEYS, które właśnie zwróciło nam listę. Jest to typ, który możemy porównać do tablicy ciągów znaków. Dostęp do danych w liście odbywa się w kolejności dodawania lub na podstawie numeru indeksu. Same listy mogą być bardzo dużymi zbiorami, gdyż mogą mieć ponad 4 miliardy pozycji.
Listę tworzymy poprzez dodanie pierwszego elementu do niej. Możemy to zrobić wywołując polecenie LPUSH lub RPUSH. Oba te polecenia są odpowiedzialne za dodanie jednego lub wielu elementów do listy. Z tą różnicą, że LPUSH dodaje elementy na początek listy, a RPUSH dodaje elementy na końcu listy.
LPUSH name_list Marcin Piotr Jan Franek Grzegorz Adam
Polecenie spowoduje dodanie 6 elementów do listy o nazwie name_list.

Mając już zdefiniowaną listę możemy wyświetlić jej zawartość poleceniem LRANGE, które jako pierwszy argument przyjmuje nazwę listy. Kolejne parametry to numer indeksu od którego ma zostać wyświetlona lista oraz numer ostatniego indeksu jaki ma być wyświetlony.
LRANGE name_list 0 10
Polecenie w rezultacie powinno nam zwrócić wszystkie elementy listy.

Zwróćcie uwagę na kolejność elementów na liście, jest ona odwrotna od tego co podaliśmy w momencie jej definiowania. Wynika to właśnie z faktu, że polecenie LPUSH dodawało każdy element na początek. W związku z czym ostatni element jest pierwszym, dodając teraz nowy element poleceniem LPUSH powinien pojawić się jako pierwszy.
LPUSH name_list Dominik
I po wyświetleniu listy poleceniem LRANGE name_list 0 10 otrzymujemy następujący wynik.
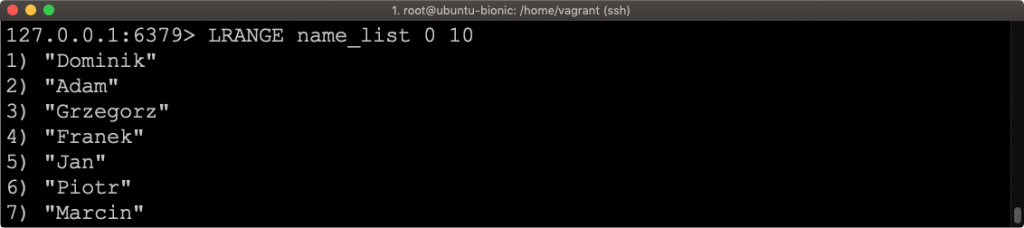
Gdybym użyli polecenia RPUSH to nowa pozycja została by dodana na koniec listy.
RPUSH name_list Mikołaj
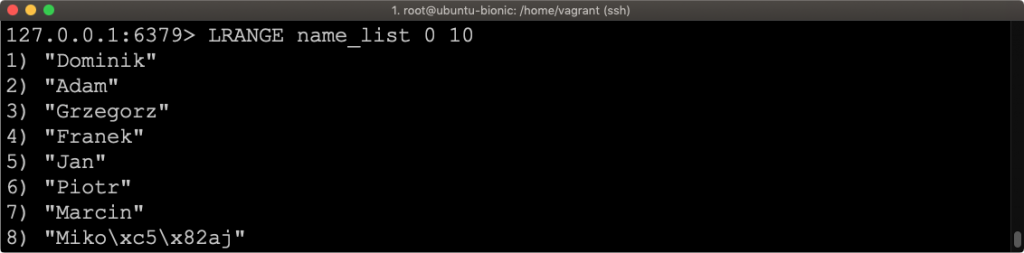
Widzimy że imię Mikołaj pojawiło się na końcu listy zgodnie z oczekiwaniami. Dodatkowo możemy w tym przypadku zobaczyć co się stało z polskimi znakami.
Oprócz pobierania wielu elementów z listy, możemy także odwołać się do konkretnego elementu poprzez polecenie LINDEX. Wystarczy przekazać nazwę listy oraz numer indeksu który nas interesuje, a otrzymamy wartość danego elementu.
LINDEX name_list 0

Ostatnią rzeczą jaką powinniśmy znać na początku pracy z listami jest usuwanie elementów z listy. A do tego celu służy polecenie LREM, którego prototyp wygląda następująco.
LREM key count value
- key – nazwa listy,
- count – ta wartość determinuje sposób usuwania elementów z listy. Jeśli ustawimy 0 (zero) to zostaną usunięte wszystkie elementy z listy o podanej wartości (value). Wpisanie liczby różnej od zera spowoduje usunięcie tylu właśnie elementów. Jeśli wpiszemy 3 to zostaną usunięte 3 pierwsze elementy o szukanej wartości. Gdy wpiszemy -2 to zostaną usunięte 2 ostatnie elementy.
- value – szukana wartość na liście
Aby lepiej zobrazować zasadę działania założę nową listę i na niej pokaże jak działa mechanizm usuwania.
RPUSH remove_list AAA BBB CCC AAA DDD WWW WWW CCC AAA
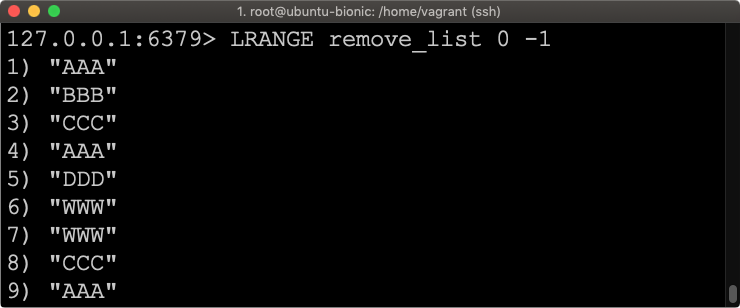
Zaczynając od najprostszej wersji, czyli usuwamy tylko to co dokładnie pasuje do wzorca.
LREM remove_list 0 "CCC"
W tym przypadku powinniśmy się pozbyć wszystkich pozycji zawierających wartość “CCC”.
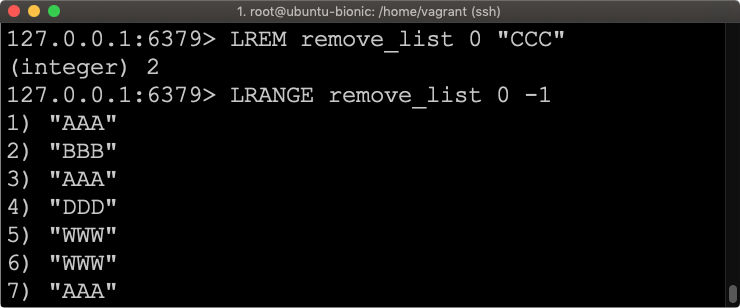
I rzeczywiście po wykonaniu polecenia nie mamy żadnego elementu z wartością “CCC”. Teraz usuńmy pierwszy element z początku listy, który ma wartość “AAA”.
LREM remove_list 1 "AAA"
I rzeczywiście na początku listy jeszcze przed chwila był element o wartości “AAA”, a teraz go tam nie ma ;) Ostatni przypadek to już formalność, usuwamy z końca listy element o wartości “AAA”.
LREM remove_list -1 "AAA"
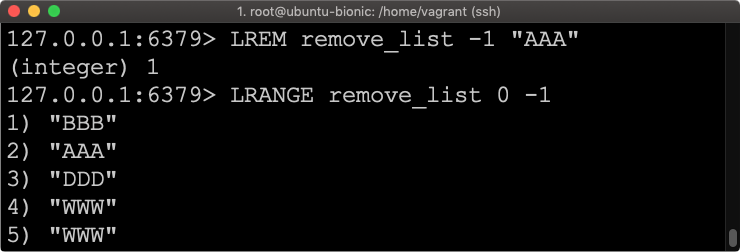
To są podstawowe operacje jakie potrzebujemy, aby zacząć przygodę z listami w REDIS-ie. Więcej o listach opowiem przy okazji implementacji prostego systemu kolejkowania opartego o listy.
Hashes – tablice asocjacyjne
Dodawane elementy do tej pory posiadały jedynie klucz i wartość. Tablice asocjacyjne rozszerzają możliwości o definiowanie atrybutów dla danego klucza. Taka struktura sprawia, że mamy wrażenie pracy z rekordami w bazie danych.
Zacznijmy od zdefiniowania nowego elementu, który będzie prostym odwzorowaniem użytkownika z bazy danych. Czyli będzie posiadał atrybut name, email, a kluczem będzie identyfikator poprzedzony prefiksem user_.
hmset user_1 name "Marcin Lewandowski" email marcin.lewandowski@czterytygodnie.pl
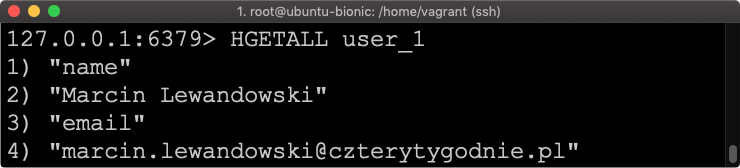
Mając tak dodanego użytkownika, chcieli byśmy wyświetlić wszystkie informacje jakie są w nim zawarte. Możemy to zrobić poleceniem HGETALL
HGETALL user_1
W rezultacie powinniśmy otrzymać listę, gdzie kolejno wyświetlane jest pole, a następnie wartość.
Na tej samej zasadzie mamy możliwość aktualizacji danych w tablicy asocjacyjnej. Aktualizację przeprowadzamy poleceniem HSET.
HSET user_1 email marcin@czterytygodnie.pl
W tym przypadku zmieniliśmy adres e-mail użytkownika.
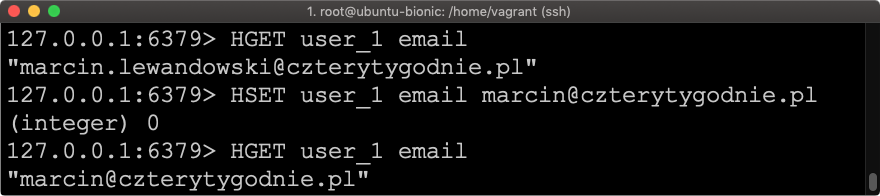
Powyżej widać adres przed modyfikacją, następnie modyfikujemy adres i wyświetlamy adres po modyfikacji.
Sets – zbiory
Zbiory są typem bardzo podobne do list, z tą różnicą że zawierają unikalne i nieuporządkowane wartości. Dzięki czemu jest to typ dużo bardziej wydajny od list i jeśli planujecie mieć dużo elementów, które będziecie często modyfikować lub przeszukiwać to powinniście użyć zbiorów.
Zbiór tworzymy poprzez dodanie elementów do zbioru poleceniem SADD.
SADD users marcin@czterytygodnie.pl ml@porady-it.pl ml@test.pl

W ten sposób powstaje nam zbiór adresów e-mail użytkowników. Na potrzeby tego przykładu zakładam, że użytkownicy w systemie mają unikalny adres e-mail. Teraz przydało by się zobaczyć zawartość naszej grupy, a robimy to poleceniem SMEMBERS.
SMEMBERS users

Do usuwanie elementów ze zbioru służy polecenie SREM, które jako parametry przyjmuje nazwę zbioru oraz wartość elementu, który ma zostać usunięty.
SREM users ml@test.pl

Widać, że element został usunięty po ponownym wyświetleniu listy. Jednak nie w tych standardowych operacjach tkwi moc zbiorów ;) Zbiory pokazują swoje możliwości, gdy mamy kilka zbiorów. Dlatego dodamy sobie drugi zbiór z listą adresów e-mail znajdujących się w newsletterze.
SADD newsletter marcin@czterytygodnie.pl
Mając dwa zbiory możemy w bardzo łatwy sposób ustalić elementy wspólne. Do tego celu wystarczy posłużyć się poleceniem SINTER, które zwraca część wspólną wielu zbiorów.
SINTER newsletter users

Jak widać powyżej dostaliśmy część wspólną, dla obu zbiorów. Wiem że dla tak małych zbiorów może nie mieć to sensu, ale wyobraźcie sobie, że kiedyś do newslettera zapiszą się tysiące osób. Porównywanie ręczne nie ma żadnego sensu, a utrzymywanie relacji w bazie relacyjnej jest kosztowne. Nie mówiąc o przypadkach, gdy przyjdzie nam porównywanie zbiorów dostarczone z systemów zewnętrznych.
Podsumowanie
REDIS ma duże możliwości jak na bazę typu klucz – wartość, a zawarte we wpisie rzeczy to dopiero wprowadzenie. Potrzebujemy go, aby przejść do bardziej zaawansowanych rzeczy jak chociażby implementacja cache dla naszej aplikacji, czy prostego systemu kolejkowego.
Gdyby coś nie zostało dość jasno wyjaśnione dawajcie znać w komentarzach, a postaram się uzupełnić braki.