
Wprowadzenie do wyrażeń regularnych

RegEx czyli wyrażenia regularne to potężne narzędzie pozwalające na zaawansowaną pracę z tekstem. Najczęściej spotkamy się z nimi, przy walidacji danych wprowadzanych przez użytkowników. Jednak nie jest to ich jedyne zastosowanie, za ich pomocą możemy odnaleźć wzorzec w tekście, pociąć tekst na fragmenty, czy też zamienić tekst zgodny ze wzorcem na inny.
Skopiowałem wyrażenie regularne ze strony XYZ i nie zawsze działa tak jak chciałem.
Wygląda znajomo ? Nie będę rzucał kamieniem, bo w przeszłości sam często tak robiłem. Wyrażenia regularne były dla mnie czarną magią i nadal zdarzają się wpadki. Jednak teraz wiem, gdzie popełniłem błąd i jak go naprawić. A moja przygoda zaczęła się od tej książki:

Czy ta książka jest dobra? Tak, jednak bardzo ciężko się ją czyta i wymaga od czytającego bardzo dużego skupienia. Najlepiej w momencie przerabiania jakiegoś przykładu od razu podglądać wyniki w jakimś narzędziu np. regex101.com
Czym są wyrażenia regularne?
Otóż wyrażenia regularne są opisem jakiegoś ciągu znaków. Taki opis nazywamy wzorcem i przy pierwszym zetknięciu może nieco przerażać. Jednak nie martw się, kiedy skończysz czytać ten wpis wszystko będzie dużo jaśniejsze.
Co właściwie znaczy, że wyrażenia regularne są opisem jakiegoś ciągu znaków? Wyobraźmy sobie, że dostajesz zadanie opisania jak wygląda kod pocztowy np. 00-935. Co powiesz ?
Mój opis by mówił: “Kod pocztowy składa się z 6 znaków, dwie cyfry, myślnik, trzy cyfry”. Niestety na razie żaden komputer tego by nie zrozumiał, dlatego mamy opisową formę wyrażeń regularnych. Taki opis mógłby wyglądać następująco:
\d\d-\d\d\d
lub
[0-9]{2}-[0-9]{3}
lub
\d{2}-\d{3}
lub wiele innych możliwości. Podobnie jak w języku naturalnym fragment tekstu możemy opisać na wiele różnych sposobów.
Dostępność wyrażeń regularnych w różnych językach programowania
Wyrażenia regularne występują właściwie w każdym języku programowania, znajdziesz je zapewne pod nazwą RegEx lub RegExp. Jednak mogą nieco różnić się składnią oraz możliwościami. Wynika to z faktu, że wyrażenia regularne wywodzą się z Perla, a następnie zostały napisane silniki dla innych języków. W większości wypadków twórcy nie wymyślali koła na nowo i skopiowali prawie wszystkie rozwiązania, dzięki czemu mamy bardzo duży stopień zgodności pomiędzy różnymi silnikami.
Jeśli na tym etapie martwisz się czy twój język programowania wspiera wszystko o czym będę tutaj mówił. To nie martw się zapewne tak jest, a jeśli nie to powiem Ci z czego skorzystać.
Perl – tutaj mamy rozwiązanie wbudowane od którego to wszystko się zaczęło,
C - dostępna jest biblioteka open source o nazwie PRCE, którą wykorzystuje chociażby interpreter PHP,
C++ - mamy do dyspozycji wiele bibliotek. Jednak polecam przyjrzeć się: PCRE (napisana w C w związku z czym potrzebny jest wrapper), RegEx Boost,
PHP - interpreter wykorzystuje bibliotekę PCRE, w związku z czym powinno wszystko działać,
JavaScript - niestety sam język nie wspiera wszystkiego o czym będzie tutaj mowa, ale możesz pobrać bibliotekę xRegEx, która dostarczy brakujące elementy,
.NET - wbudowana obsługa wyrażeń regularnych,
Java - wbudowana obsługa wyrażeń regularnych,
Więc jak widzisz mamy tutaj większość popularnych języków programowania, które nie mają problemu z obsługą wyrażeń regularnych.
W czym może pomóc Ci RegEx?
Otóż wyrażenia regularne mogą pomóc Ci nie tylko w walidacji danych z formularzy. Zobaczmy pełen przegląd tego do czego mogą Ci się przydać wyrażenia regularne:
Sprawdzenie tekstu ze wzorcem, czyli popularna walidacja danych. Sprawdzenie czy użytkownik wpisał kod pocztowy we właściwym formacie np. 00-935
Odnajdowanie wzorca w tekście, załóżmy że mamy jakiś tekst np. zawartość strony internetowej. Chcemy znaleźć w jej treści wszystkie adresy mailowe i wyświetlić je w formie listy. Nie ma problemu, wyrażenia regularne mogą nam w tym pomóc.
Pocięcie tekstu na fragmenty, bardzo często spotykane w przypadku konieczności wyciągnięcia poszczególnych fragmentów daty czy też czasu.
I ostatnie zastosowanie, czyli zamiana testu. Dzięki wyrażeniom regularnym nie będziecie mieli problemu ze zmianą formatowania dowolnego ciągu znaków na inny. Przydatne przy analizowaniu różnego typu logów, czy też transformacji dat, czasu.
Jak działa silnik RegEx
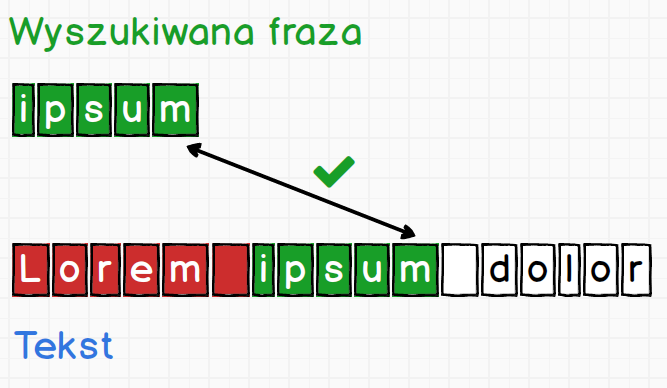
Silnik RegEx patrzy na wprowadzony przez nas wzorzec oraz tekst dokładnie tak samo jak my (do pewnego momentu). Oznacza to, że wpisując wzorzec ipsum będzie on widziany przez silnik w następujący sposób:
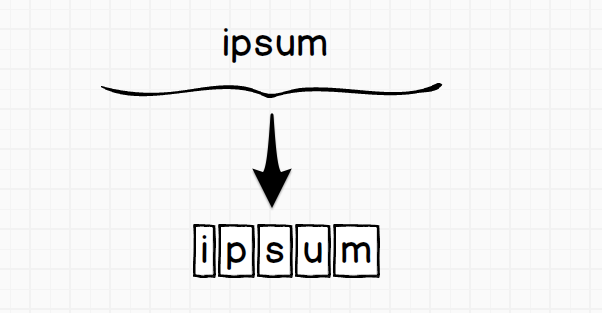
Czyli nastąpiło rozbicie na znaki dokładnie tak jak my to robimy przy porównywaniu tekstów. Tekst jest widziany w ten sam sposób, więc fraza Lorem ipsum dolor zostanie rozbity na znaki tak jak pokazano to poniżej.
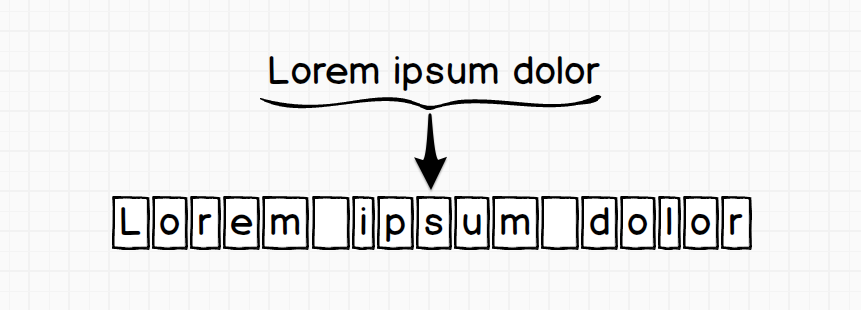
Przy zastosowaniu takiego podziału bardzo łatwo jesteśmy sobie w stanie wyobrazić działanie silnika. Analiza tekstu zaczyna się od lewej strony i biegnie ku prawej. Tekst i wzorzec są porównywane znak po znaku, co jest także naturalne dla ludzi. Zobaczmy jak to wygląda na konkretnym przykładzie.
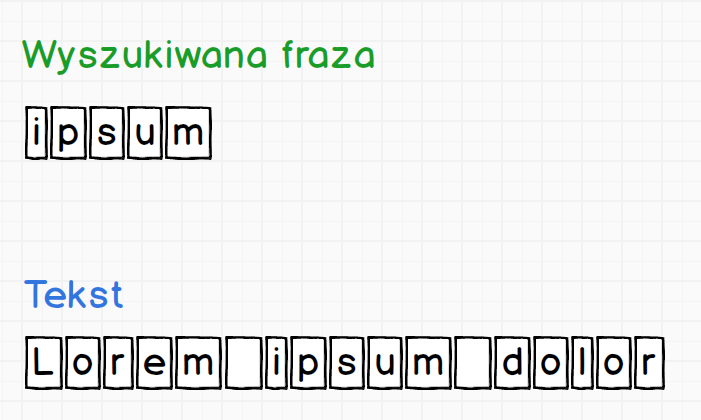
Teraz zaczynając od pierwszego znaku wyszukiwanej frazy ipsum będziemy sprawdzać czy udało się dopasować znak do tekstu.
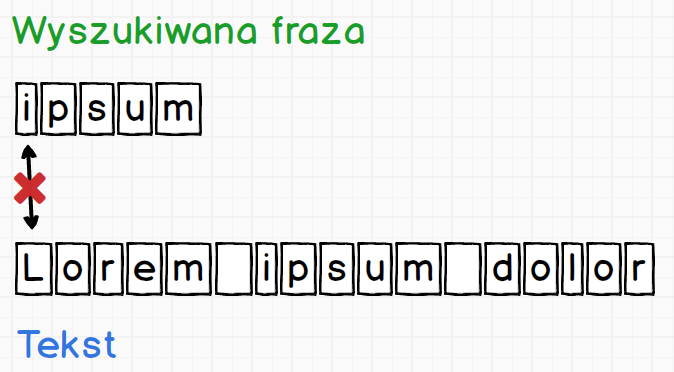
Widzimy że znak i nie jest równy pierwszemu znakowi tekstu L. Dopasowanie nie powiodło się w związku z czym oznaczamy sobie tę informację kolorem czerwonym i przechodzimy do kolejnego znaku.
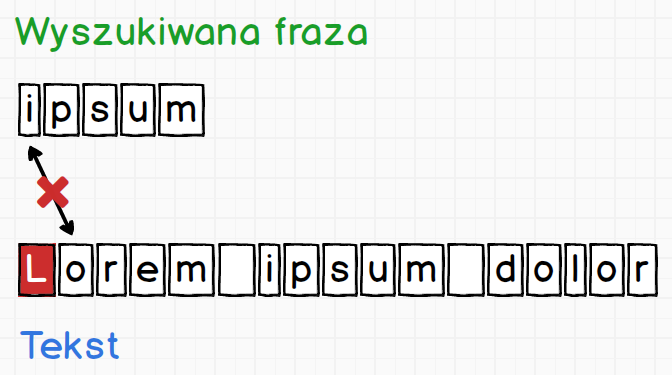
Tutaj mamy identyczną sytuację, i silnik postępuje identycznie jak w poprzednim przypadku. Tak będzie się działo, aż trafimy na jakieś dopasowanie.
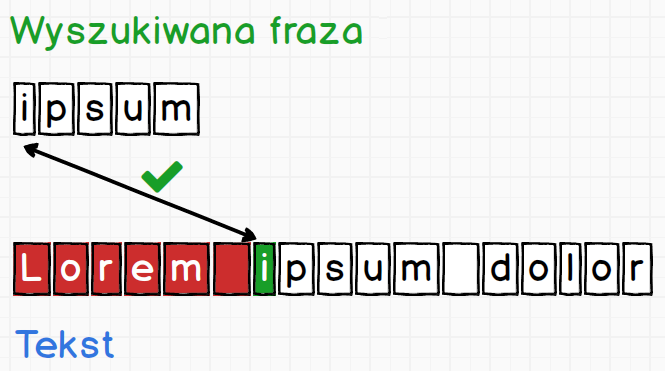
Gdy uda się dopasować pierwszy znak, silnik zapisuje pozycję za tym znakiem dodając specjalny znacznik. Znacznik dodawany jest także do wyszukiwanej frazy.
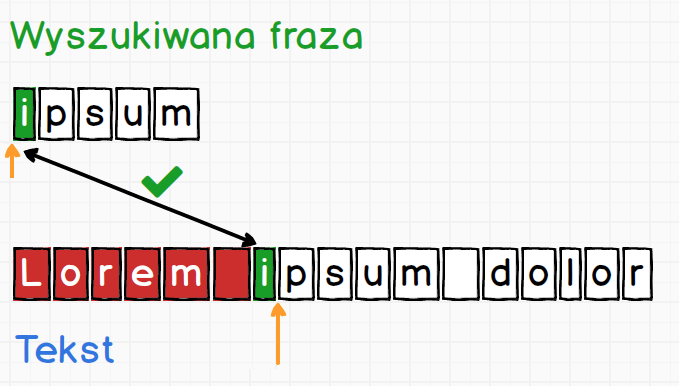
Znacznik jest reprezentowany przez pomarańczową strzałkę. Silnik robi tak na wypadek, gdyby dopasowanie całej wyszukiwanej frazy się nie powiodło. Wtedy jest w stanie wrócić do znacznika i kontynuować porównywanie od zapamiętanego miejsca. Dalej proces wygląda identycznie jak do tej pory, czyli porównujemy znak po znaku.
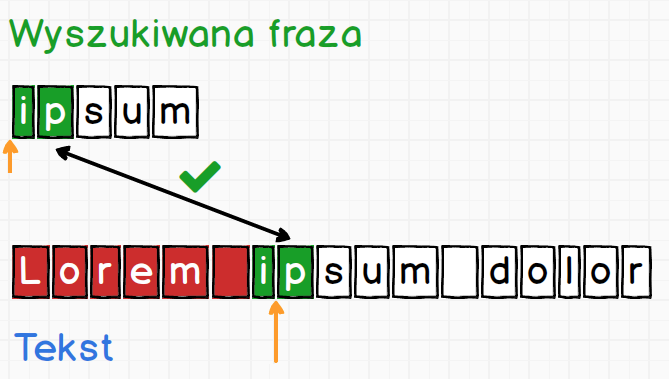
Kiedy zostanie dopasowana cała fraza silnik może zakończyć pracę, lub jeśli była ustawiona flaga g Global kontynuować pracę szukając kolejnego dopasowania w dalszej części treści.
Narzędzia
Do testowania pisanych wyrażeń regularnych polecam stronę regex101.com. Oczywiście jest wiele innych narzędzi tego typu dostępnych online, ale dlaczego polecam właśnie to ?
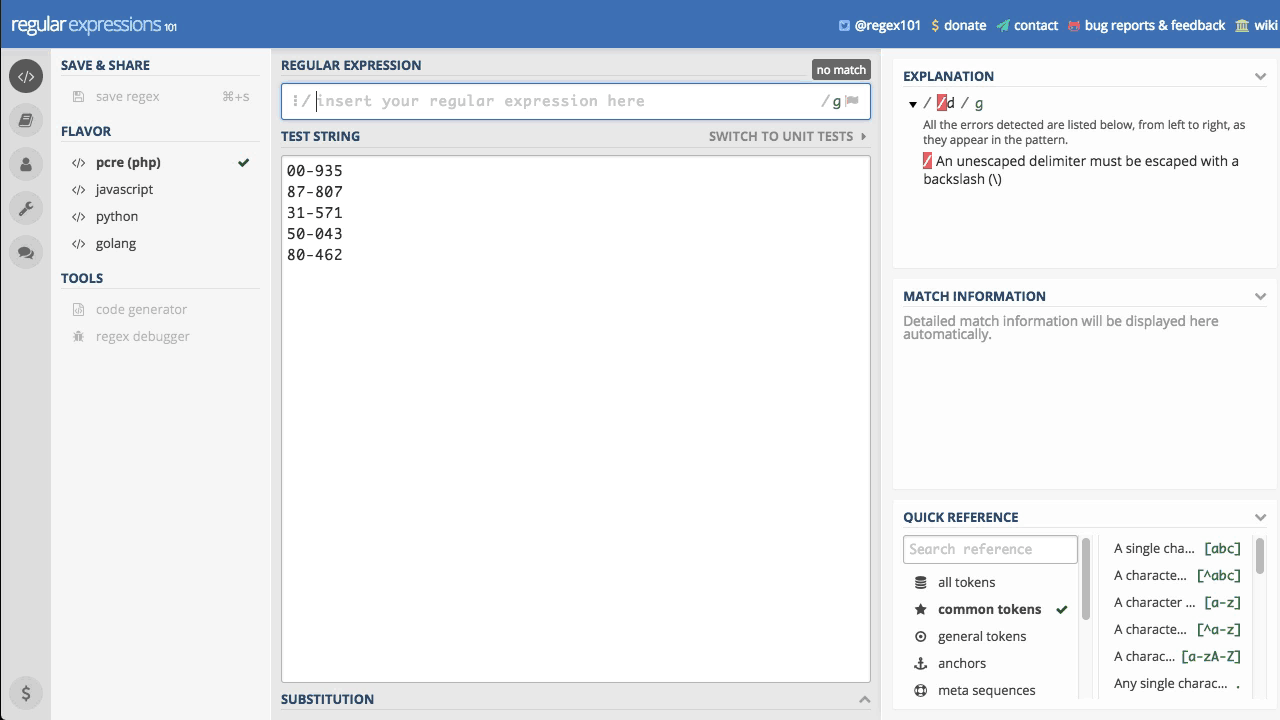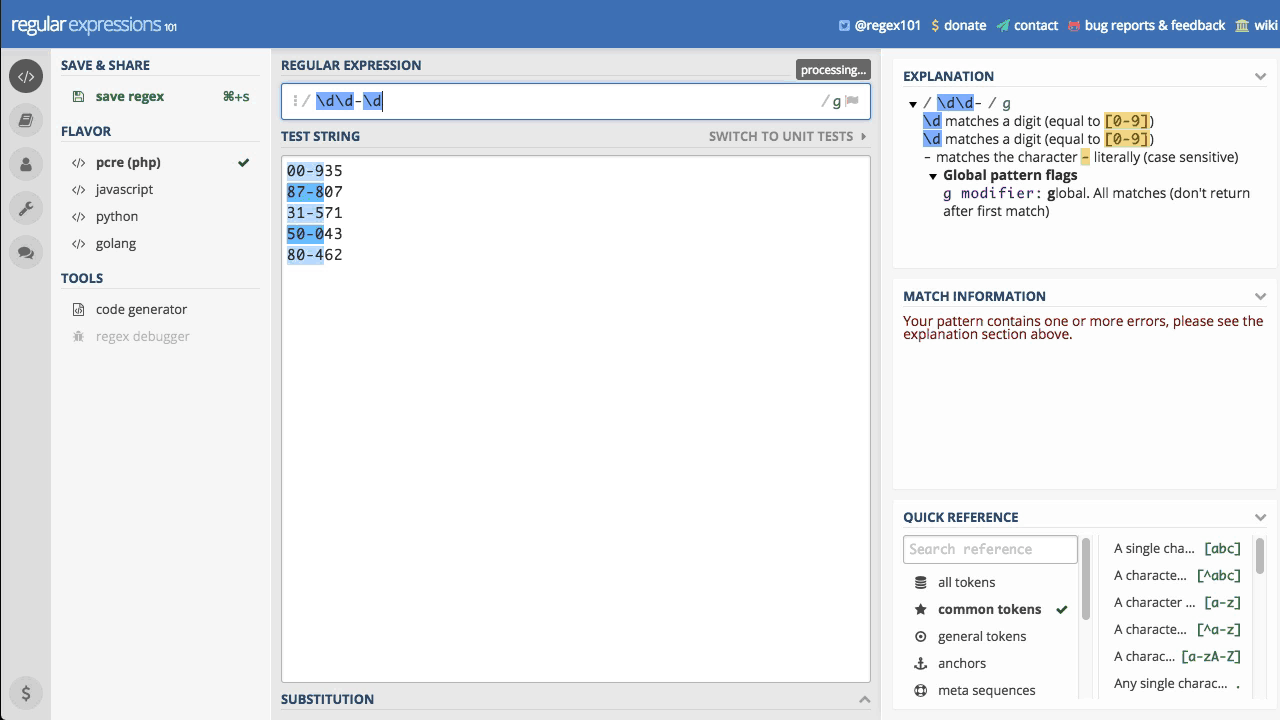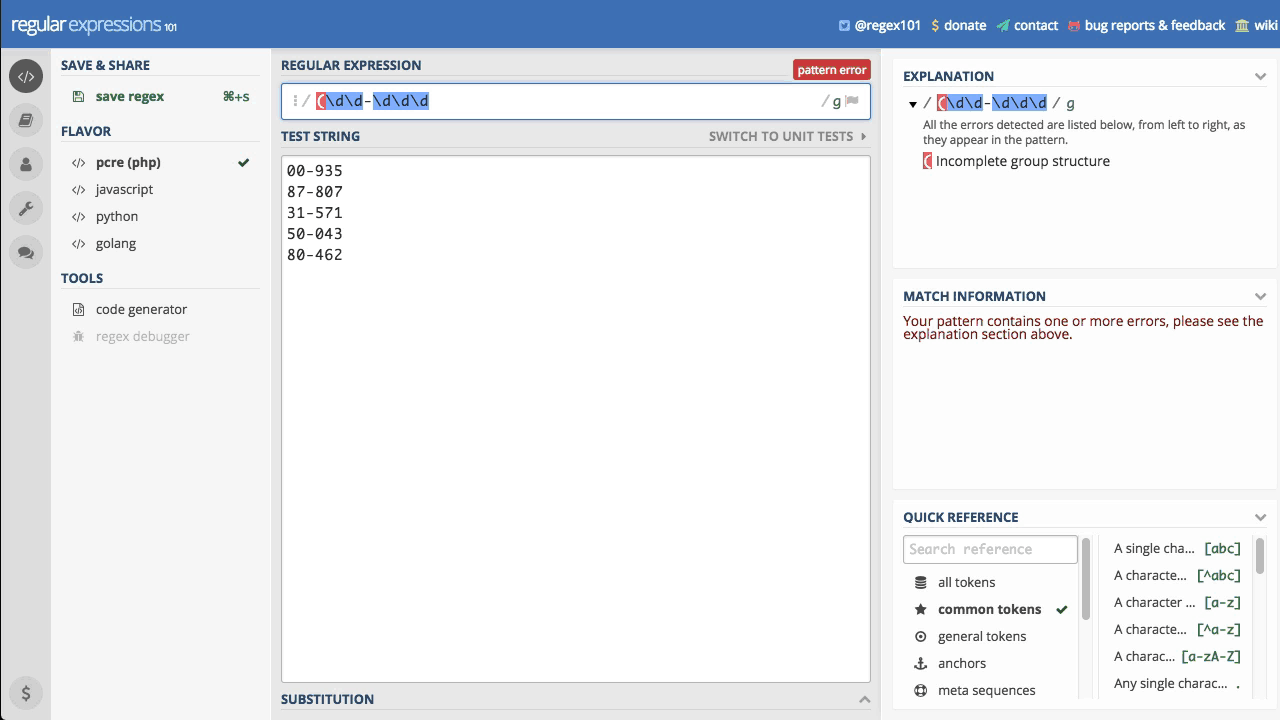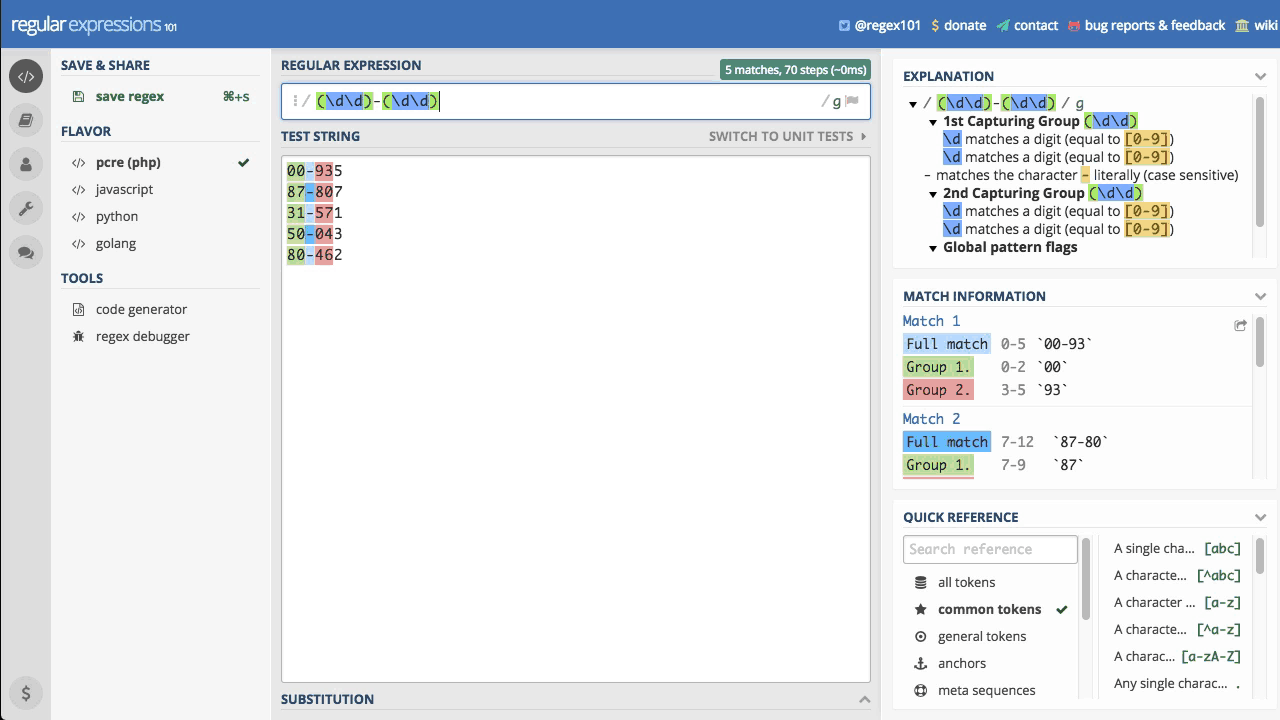
Przede wszystkim ze względu na interaktywność działania. To co widzicie powyżej niesamowicie przyspiesza pracę z wyrażeniami regularnymi. Drobna modyfikacja wzorca i od razu widzicie jak zmiana wpłynie na trafność dopasowań.
Poza tym, serwis ten ma bardzo przyjazny interfejs, który nie odstrasza. Przygodę zaczynamy od pola Regular Expression, gdzie będziemy pisali nasze wyrażenia regularne.
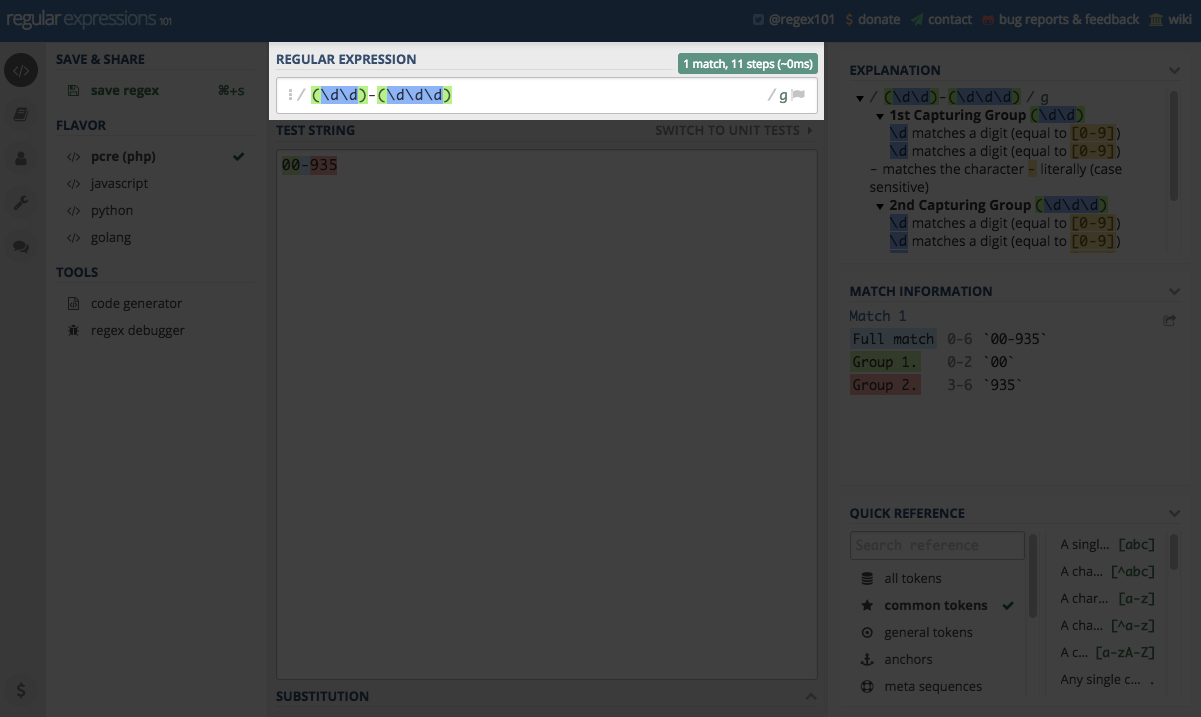
Kolejne istotne pole to Test String w którym umieszczamy treść na której będziemy testować nasze wyrażenie.
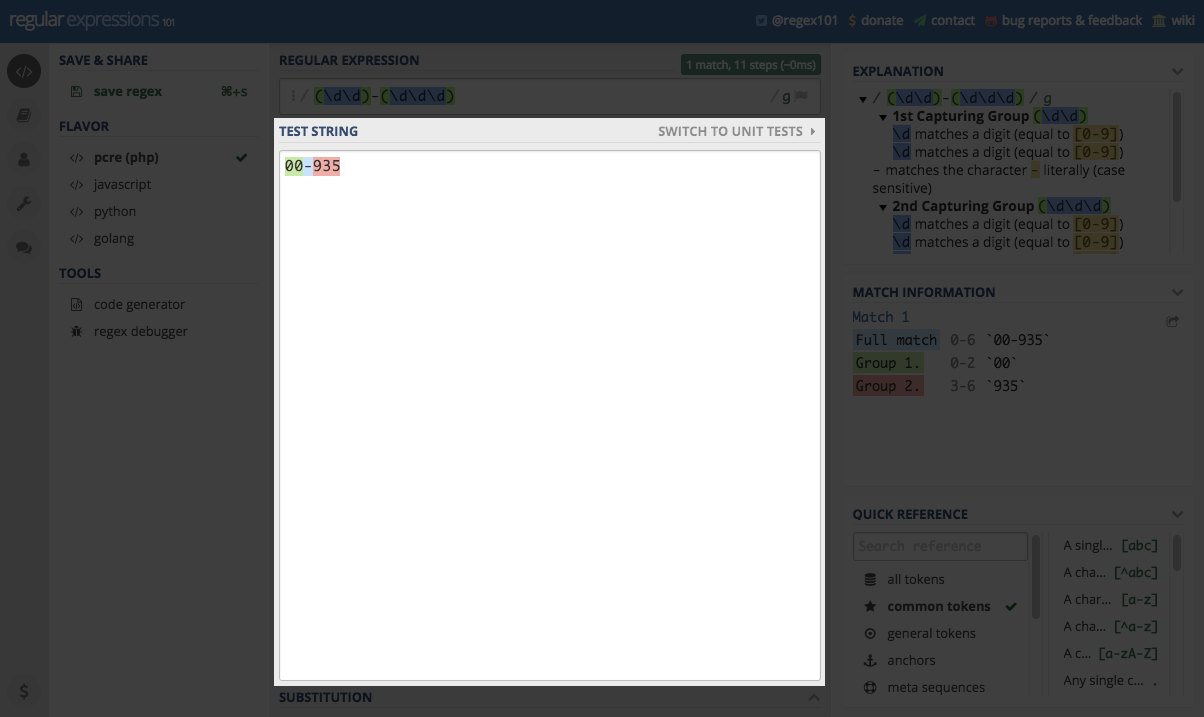
Co ważne oba pola mają kolorowanie składni. Dzięki czemu na pierwszy rzut oka widać, które grupy odpowiadają grupom z wyrażenia.
Jeśli jednak chcemy bardziej kompleksowej informacji to mamy dodatkowe okienko z informacjami o dopasowaniach do wzorca i szczegółach tego dopasowania. Sekcja nazywa się Match Information
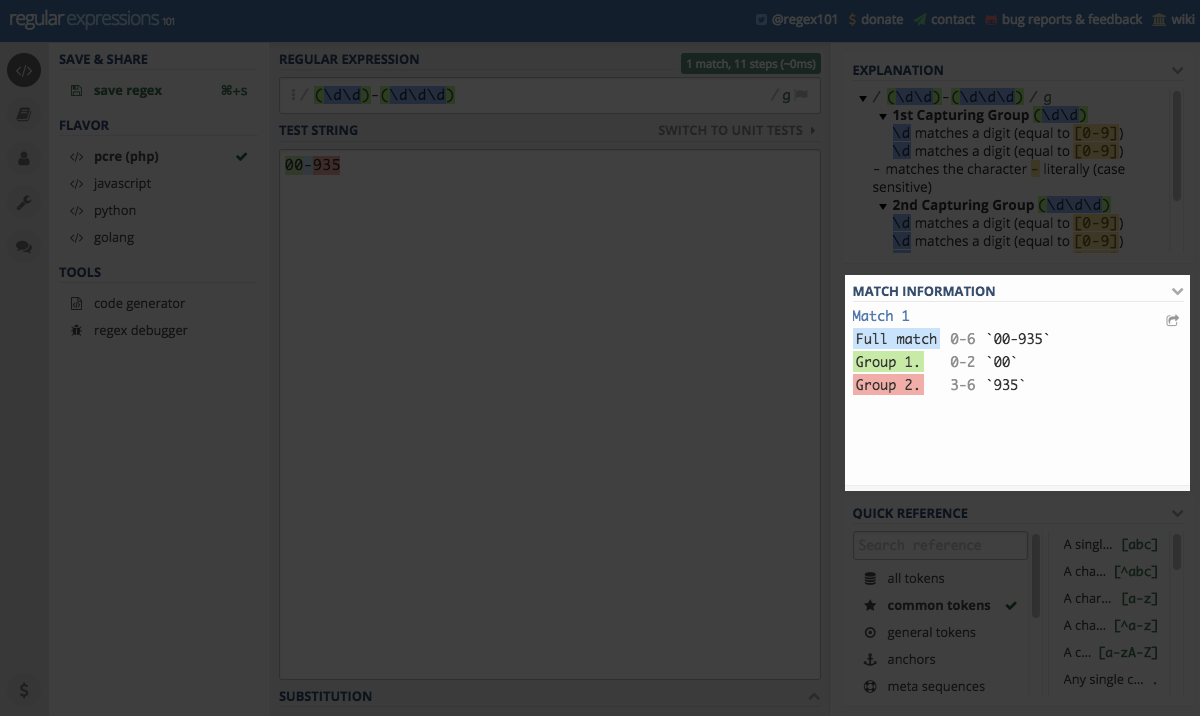
Zaś powyżej tej sekcji znajdziemy dodatkową sekcję Explanation z wyjaśnieniami dotyczącymi dopasowań do wyrażenia.
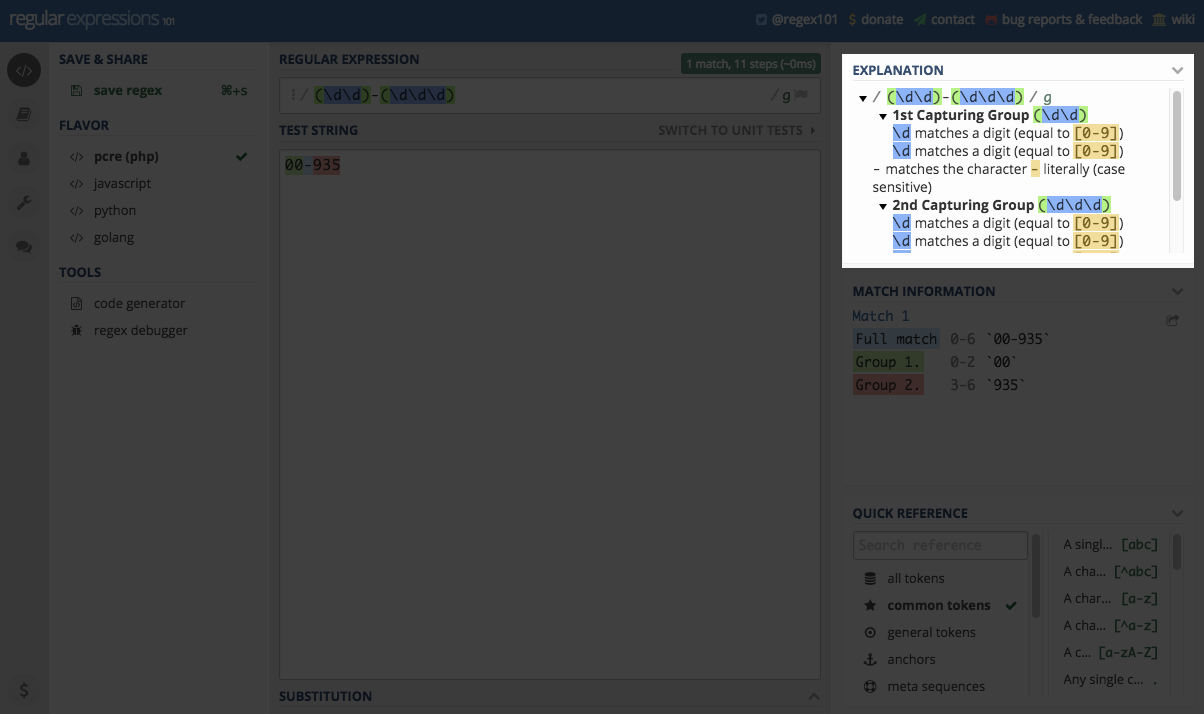
Z powyższych sekcji korzysta się najczęściej. Do dyspozycji mamy jeszcze dwie sekcje. Pierwsza to zbiór podpowiedzi, przydatne gdy ktoś zaczyna przygodę i nie chce ciągle zaglądać do wpisu lub książki.
Ostatni element to menu po lewej stronie umożliwiające zapisanie wyrażenia czy też zmianę silnika co czasem się przydaje.
Wyszukiwanie ciągów znaków
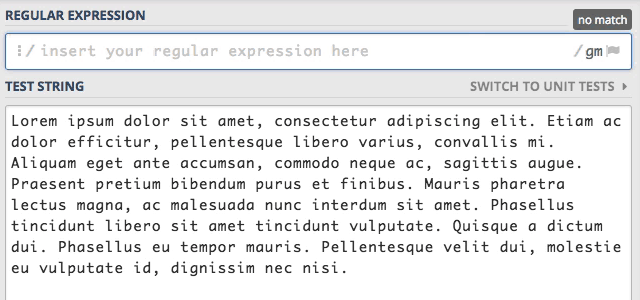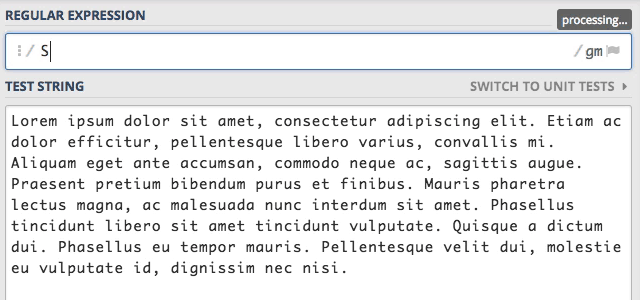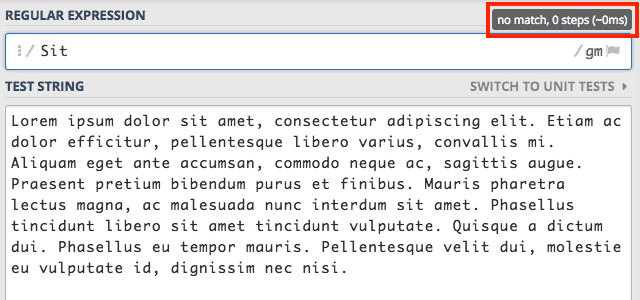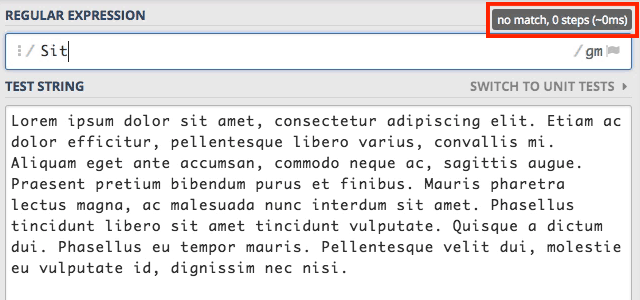
Zacznijmy naszą przygodę od podstaw, czyli jak znaleźć określony ciąg znaków w tekście. Mam standardowy tekst “Lorem ipsum” i chcę w nim znaleźć wszystkie wystąpienia słowa sit. W tym celu wpisuję po prostu szukane słowo.
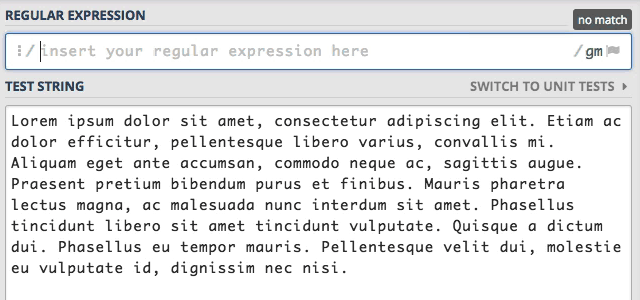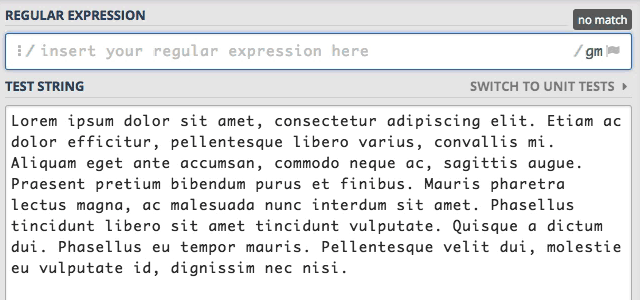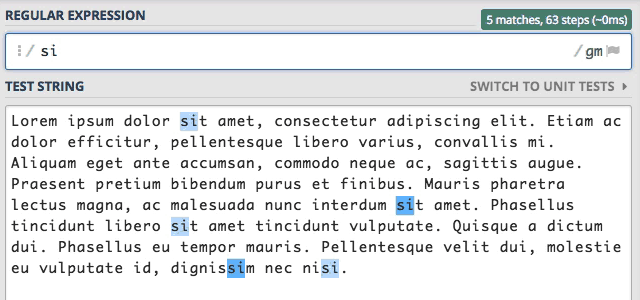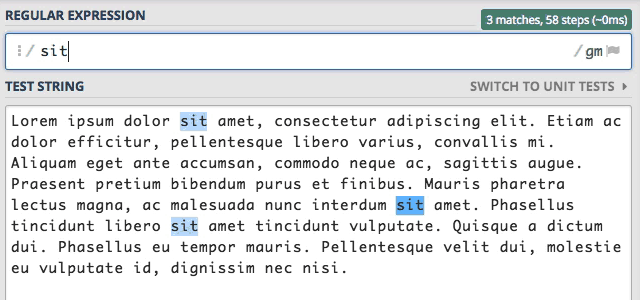
Kiedy przypatrzycie się powyższej animacji zobaczycie jaki proces zachodzi podczas wyszukiwania. Wpisanie pierwszej
litery s znalazło ją 29 razy. Dodanie kolejnej i kolejnej litery pięknie zawęża wyszukiwanie. Jednak musimy mieć świadomość,
że wpisanie tego samego słowa z dużej litery czyli Sit zwróci zero wyników.
Jak już pewnie się domyślacie RegEx jest wrażliwy na wielkość liter. Możemy jednak to zmienić poprzez zastosowanie
odpowiedniej flagi, a w tym konkretnym przypadku chodzi o flagę i (ang. insensitive). O flagach zaraz sobie jeszcze
porozmawiamy, na razie zobaczmy jak ustawić interesującą nas flagę.
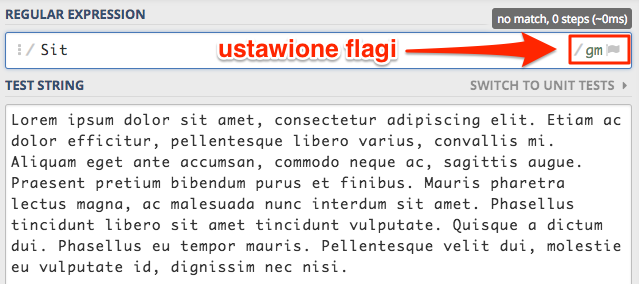
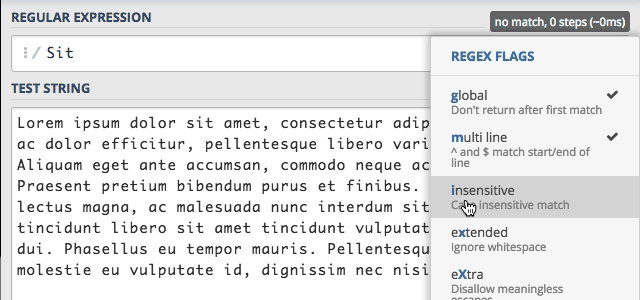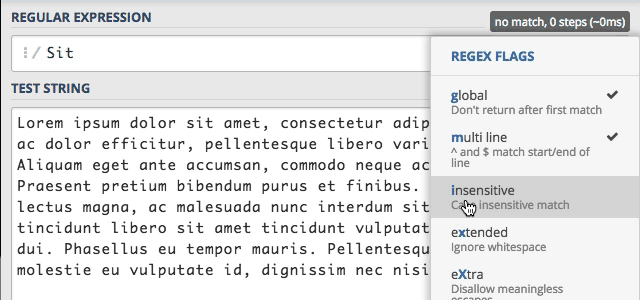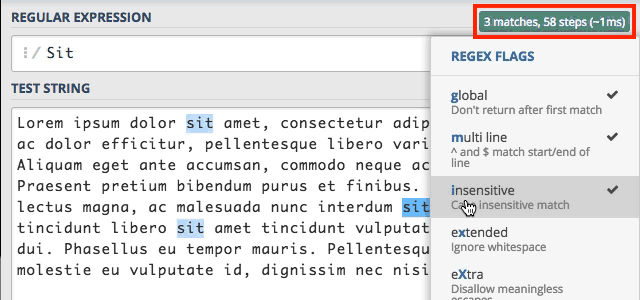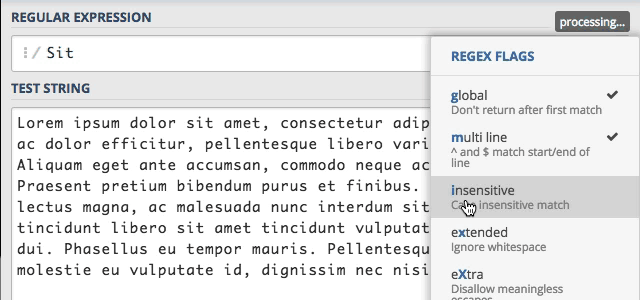
Po prawej stronie znajduje się lista flag jakie obecnie są ustawione. Klikając w tę listę otrzymamy możliwość włączania i wyłączania flag.
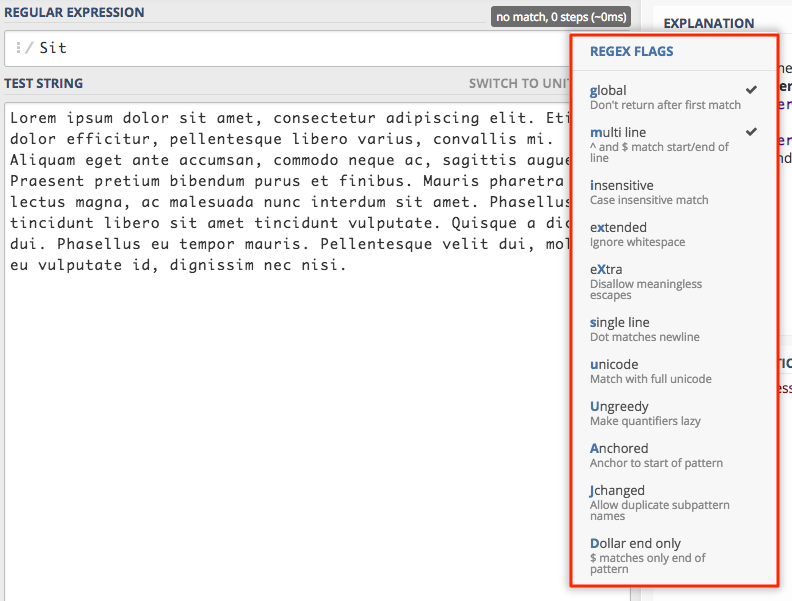
Na liście koło włączonych flag znajduje się stosowne oznaczenie. Domyślnie mamy włączone dwie flagi global i multi line.
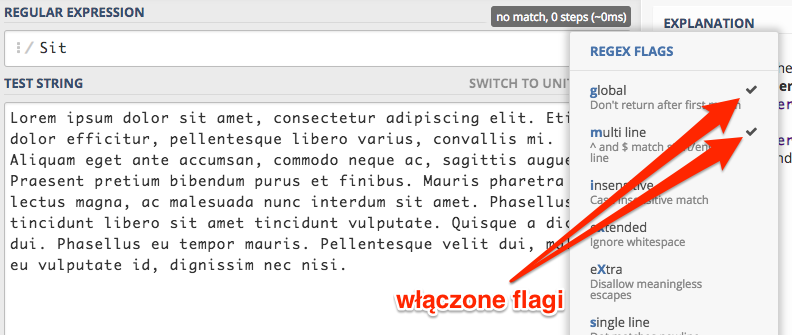
My klikamy w insensitive co spowoduje, że silnik RegEx stanie się niewrażliwy na wielkość znaków. Przez co rezultaty
wyszukiwania powinny być dokładnie takie same jak w przypadku słowa sit.
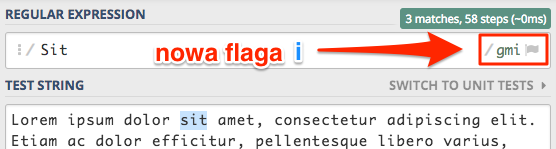
Dodatkowo nowo włączona flaga i, pojawi się nam na liście flag po prawej stronie. Dzięki czemu mamy cały czas podgląd wykorzystywanych flag.
Flagi
Flagi są to dodatkowe opcje silnika RegEx, które pozwalają w pewien sposób zmieniać jego sposób działania. Ze względu na różne implementacje, nie wszystkie flagi mogą być u was dostępne. Jednak w większości przypadków powinny działać bez problemów ;)
Flaga g – global
Domyślnie wyszukiwanie przez silnik wyrażeń regularnych jest kończone w momencie, gdy zostanie znaleziony pierwszy ciąg
znaków spełniający warunki zdefiniowane we wzorcu. Aby lepiej to zrozumieć wyłączymy wszystkie flagi i wyszukamy słowo sit.
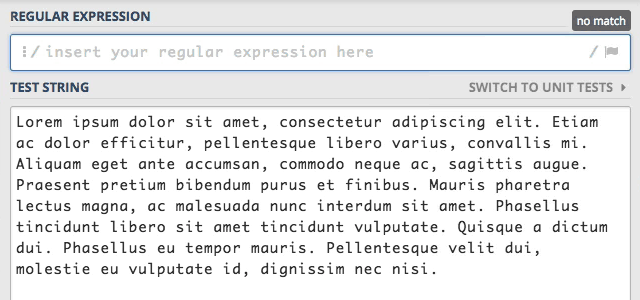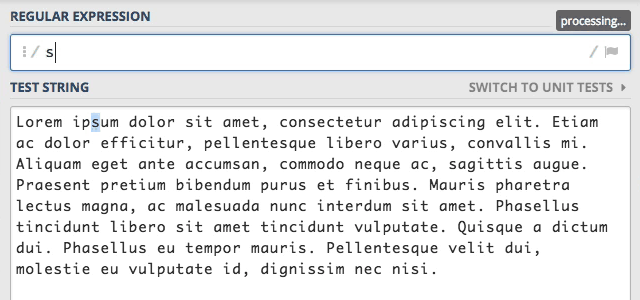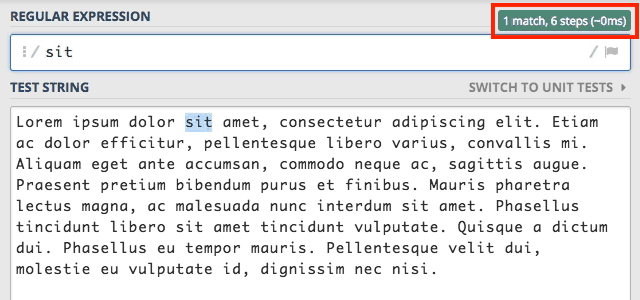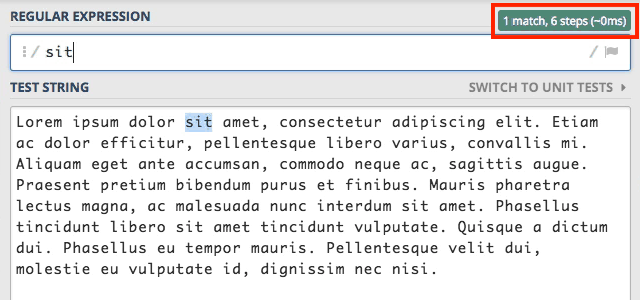
Przy wyłączonych wszystkich flagach zostało znalezione tylko pierwsze wystąpienie tego słowa. Kiedy dodamy flagę g (global)
to silnik zmieni swoje działanie i wyszuka wszystkie wystąpienia słowa sit.
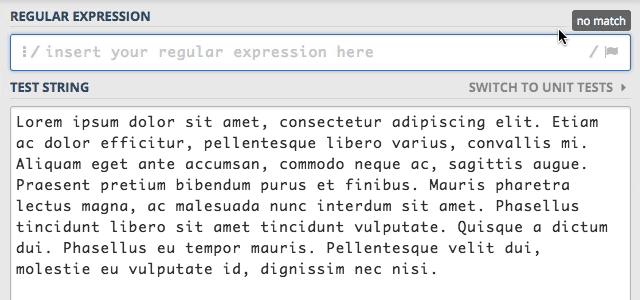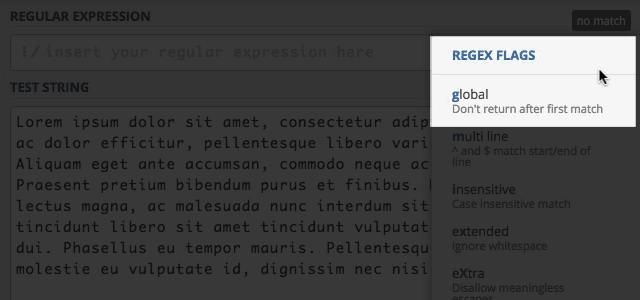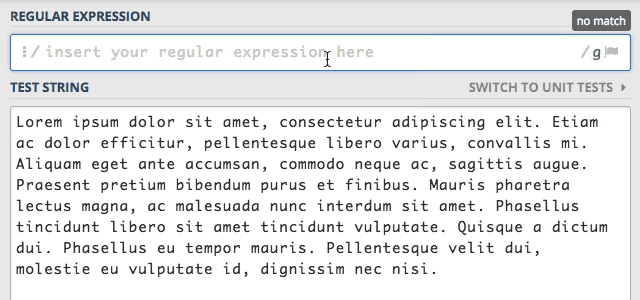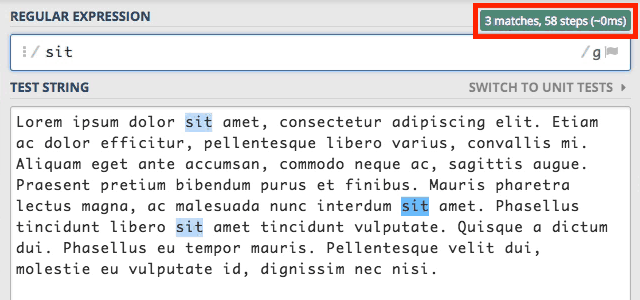
Oczywiście takie działanie jest okupione dużo większą liczbą operacji do wykonania, co widać w ilości kroków pokazywanych obok ilości znalezionych siągów znaków.
Flaga m – multi line
W wyrażeniach regularnych mamy wiele znaków specjalnych spełniających określone funkcje. Jednym z nich jest znak ^,
który mówi, że początek ciągu znaków musi spełnić zdefiniowane przez nas warunki. Spokojnie już śpieszę z wyjaśnieniem,
zacznijmy od przykładu na którym pokażę o co chodzi.
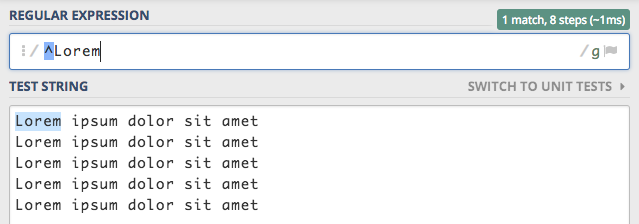
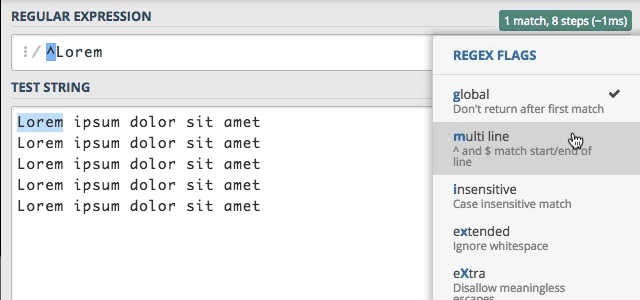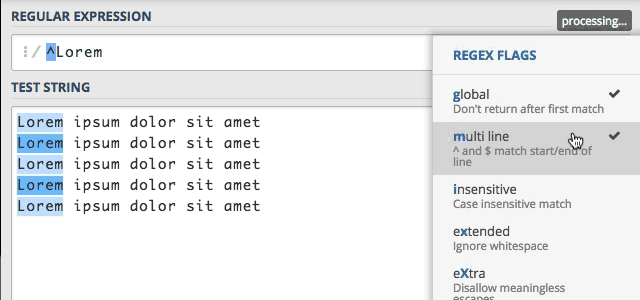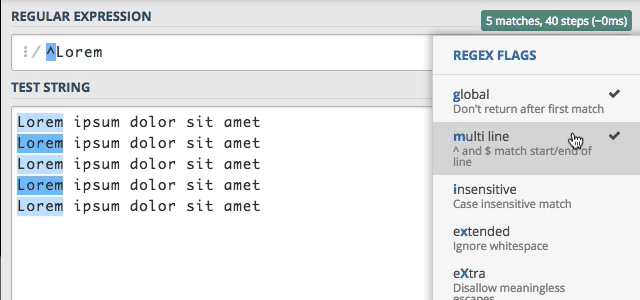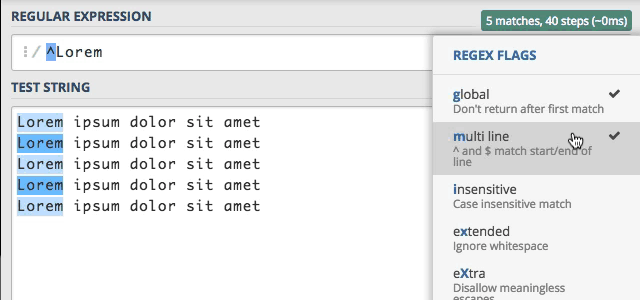
Mamy tutaj tekst składający się z wielu linii, i chcemy napisać wyrażenie, które będzie sprawdzało czy nasz tekst
zaczyna się od słowa Lorem. Do tego celu posłużymy się znakiem ^, który sprawdza początek tekstu, a następnie dodamy
wyszukiwane słowo. W rezultacie otrzymamy wyrażenie ^Lorem i jak widać działa ono według oczekiwań.
Gdybym jednak chcieli, sprawdzić początek każdej linii, a nie początek całego teksu ? Tu z pomocą przychodzi nam flaga
Multi line, modyfikuje ona domyślne zachowanie znaku ^ oraz $. Zobaczmy jak to będzie działało w rzeczywistości.
Wszystko działa zgodnie z naszymi oczekiwaniami, super :) Wcześniej wspomniałem o tym, że flaga ta modyfikuje działanie
także znaku $. Znak ten działa w ten sam sposób jak ^, z tą różnicą że dotyczy końca tekstu. Czyli możemy sprawdzić czy
nasz ciąg kończy się w określony sposób np. słowem amet.
I teraz dodanie flagi m spowoduje, że będziemy sprawdzać czy każda linia kończy się na słowo amet.
Ostatnia sprawa to związek tej flagi z flagą o podobnej nazwie Single line. Otóż nie mają one ze sobą żadnego związku, po prostu ktoś wyjątkowo źle dobrał nazwy tych flag.
Flaga i – insensitive
Tę flagę już znacie z początku wpisu, ale dla przypomnienia. Powoduje ona, że silnik wyrażeń regularnych staje się niewrażliwy na wielkość znaków.
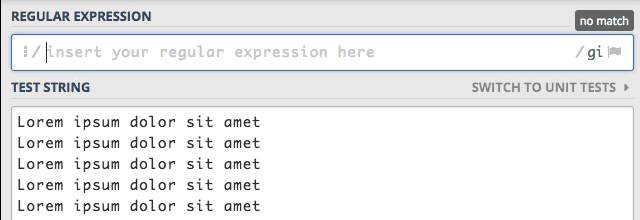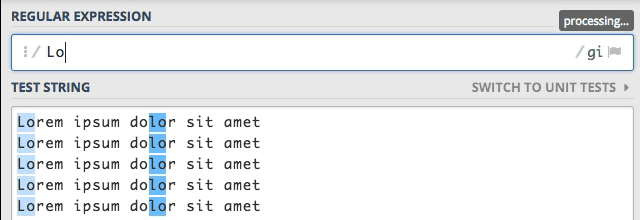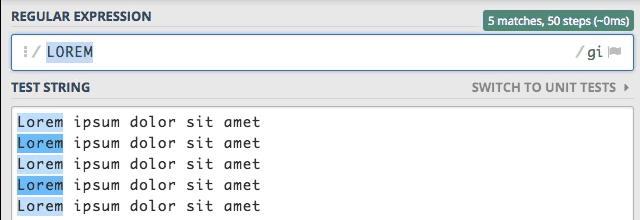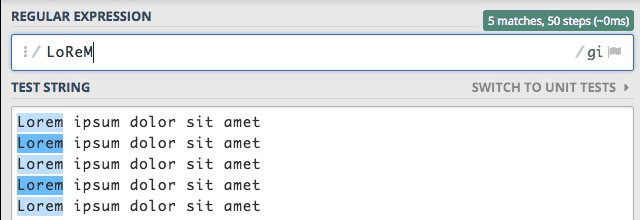
Widzimy, że dzięki włączonej fladze i wpisywanie słowa Lorem w dowolnej konfiguracji powoduje zawsze jego znalezienie.
Flaga x – extended
Ignorowanie białych znaków jest przydatne, gdy piszemy nasze wyrażenia w wielu linijkach. Zapewne zastanawiasz się, po co pisać wyrażenia w wielu liniach ? Odpowiedź jest dość prosta, czytelność. Wyrażenia regularne nie należą do czegoś bardzo czytelnego i wszystko co może poprawić ich czytelność jest mile widziane.
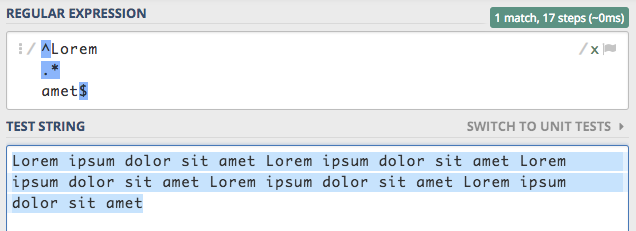
Gdyby nie flaga x taki zapis byłby niemożliwy do zastosowani. Teraz możemy w prosty sposób napisać, że pierwsza linia
sprawdza czy ciąg znaków rozpoczyna się od Lorem. Druga linia zachłannie wyszykuje czegokolwiek, a ostatnia sprawdza
czy ciąg kończy się na amet.
Flaga ta ma jednak jedną wadę, wymusza na nas jawne definiowanie np. spacji. Gdyż każdy biały znak (ang. whitespace) będzie ignorowany. Więc jak zawsze, coś za coś.
Flaga s – single line
Flaga ta rozszerza to co może być dopasowane do znaku kropki. Kropka jest znakiem specjalnym i zastępuje praktycznie
każdy znak, jednak nie zastępuje znaku nowej linii. W związku z czym wyrażenie <.> spowoduje dopasowanie wszystkich
znaczników html które rozpoczynają się od znaku <, kończą na znak >, a pomiędzy tymi znakami znajduje się jeden dowolny znak.
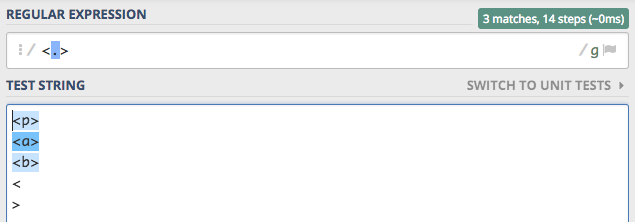
Wszystkie elementy na tej liście spełniają postawione założenia, ale jeden element nie został dopasowany. Spowodowane
jest to faktem, że znak . nie zastępuje nowej linii. Dodajmy flagę s, która rozszerzy ten zakres o nową linię
i zobaczmy czy zmieni się wynik.
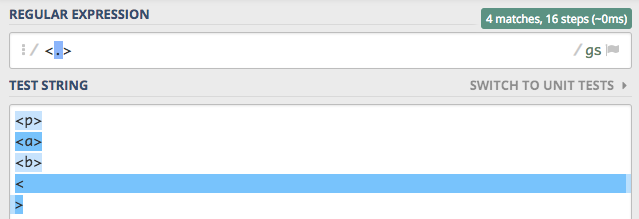
Rzeczywiście wynik się zmienił, teraz ostatni element także został dopasowany. Jeśli zastanawiasz się nad praktycznym
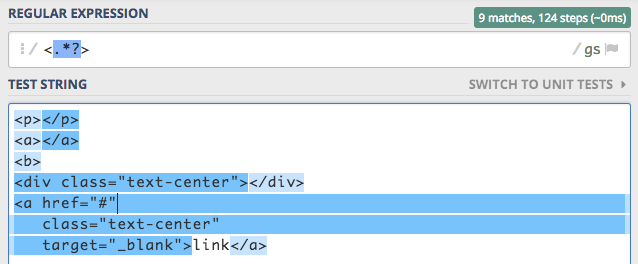
aspektem tej flagi to pozwól, że podam nieco bardziej zaawansowany przykład. W skrócie, wyrażenie <.*?> powinno
dopasowywać wszystkie znaczniki html.
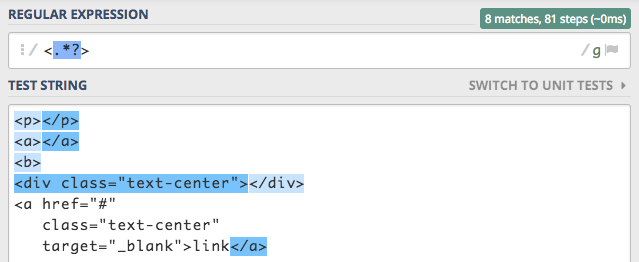
I jesteśmy bardzo blisko, ale niektóre znaczniki html-a mają znaki nowej linii, przez co nie są znajdowane.
Tu przychodzi z pomocą flaga s, po jej włączeniu problem znika.
Flaga u – unicode
Pewnie niewielu z was pamięta czasy, gdy Unicode nie był standardem tak bardzo rozpowszechnionym jak teraz. Silniki wyrażeń regularnych pamiętają te czasy i się do nich przygotowały. A dokładniej chodzi o obsługę znaków narodowych.
Mamy taką klasę znaków dostępną pod tokenem \w, która określa zakres znaków od litery A do litery Z (małe i duże litery) oraz cyfry.
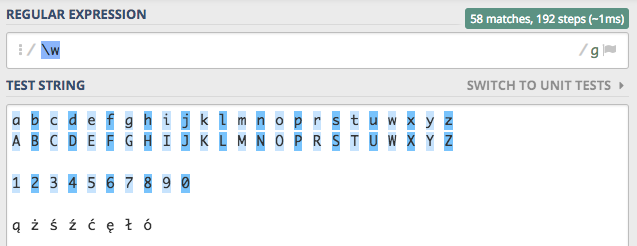
Pominięte zostały znaki narodowe, po włączeniu flagi Unicode nasze polskie ogonki zostaną poprawnie znalezione.
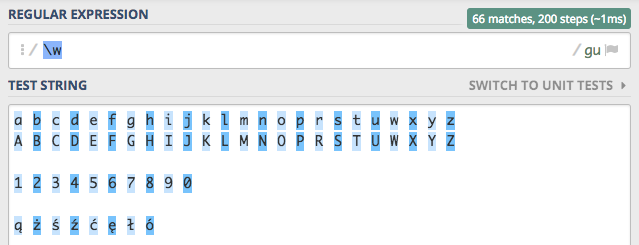
Oczywiście rozwiązanie to działa także dla innych języków i możemy spokojnie stosować je przy pracy z niemieckim, francuskim itd.
Wyjątki
Jest to jedna z flag, która albo nie występuje w implementacji silnika dla danego języka. Albo zachowanie jest nieco inne niż to omówione powyżej.
.Net – brak flagi, wszystkie znaki są traktowane jako znaki Unicode więc klasa \w będzie uwzględniała znaki narodowe.
Ma to swoje plusy w postaci braku konieczności ustawiania czegokolwiek. Oraz minus, że w przypadku chęci wykluczenia
znaków narodowych musimy sobie napisać odpowiedni wzorzec sami.
JavaScript – jest flaga Unicode, ale nie wpływa ona na zachowanie klasy znaków \w.
C – w tym przypadku mamy wszystko dostępne, jedynie należy pamiętać, aby przy kompilacji biblioteki PCRE włączyć Unicode.
Flaga U – ungreedy
O zachłanności będziemy jeszcze sobie mówili więcej w dalszej części, tutaj powinna wystarczyć nam wiedza, że domyślnie
silniki wyrażeń regularnych działają w trybie zachłannym. A flaga U zmienia to zachowanie na tryb niezachłanny.
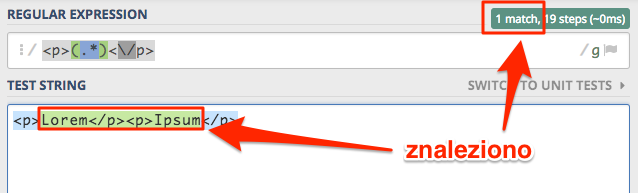
Zacznijmy od prostego wyrażenia <p>(.*)<\/p>, jego treść teraz nie ma większego znaczenia. Jedynie powinniśmy wiedzieć,
że ma za zadanie dopasować wszystko pomiędzy znacznikiem <p> i zamknięciem znacznika </p>.
Tryb zachłanny spowodował, że rzeczywiście zostało znalezione wszystko pomiędzy znacznikami. Jednak znalazły się tam
też inne znaczniki <p> i zamykające </p>, a nie do końca o to nam chodziło. Dodajemy flagę U i zobaczmy jak zmieni
się wynik działania wyrażenia.
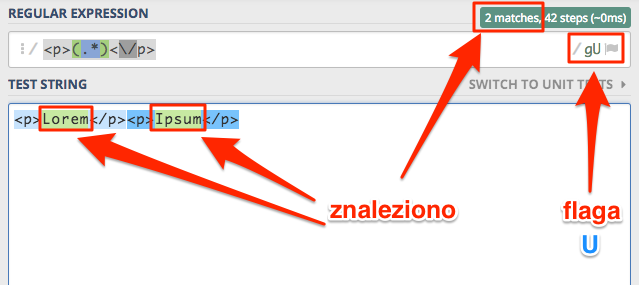
Znaleziono zawartość obu paragrafów, i o to nam chodziło na początku. Oczywiście możemy dojść to tego zmieniając zapis wyrażenia bez posiłkowania się flagami, ale o tym porozmawiamy przy omawianiu zachłanności.
Rozwiązanie oparte o flagi ma jedną wadę, nie da się mieszać zachłanności kwantyfikatorów w jednym wyrażeniu. Czyli nie powiesz, że ten fragment ma być zachłanny, a inny już nie. W związku z czym lepiej pominąć tę flagę i skupić się na jawnym definiowaniu zachłanności w pisanych wzorcach.
Klasy znaków
Zbiory
Do tej pory nasze wyrażenia to były proste ciągi tekstowe, teraz nieco rozszerzymy ich możliwości poprzez wprowadzenie zbiorów.
Zbiór definiujemy w nawiasach kwadratowych, taki najprostszy zbiór może wyglądać następująco [abc]. I dla silnika oznacza
to, że każdy przetwarzany znak musi zawszeć się w tym zbiorze. Tym samym przetwarzany znak musi być literą a, b lub c aby został dopasowany.
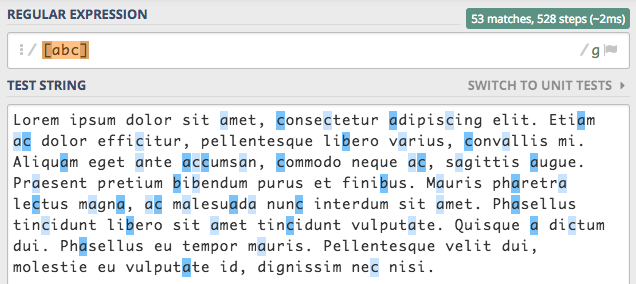
W powyższym przykładzie znaleziono 53 dopasowania do wzorca. Dopasowanie do zbioru nie jest jedyną możliwością jaką
mamy do dyspozycji. Oprócz dopasowywania do zbioru możemy chcieć dany zbiór wykluczyć. Robimy to dodając na początku
zbioru znak ^ i nasze wyrażenie będzie wyglądało następująco [^abc]. Spowoduje to wykluczenie liter a, b, c
z dopasowań.
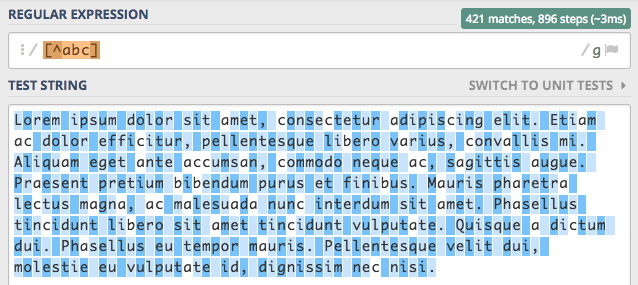
Ostatnia rzecz jaką powinniśmy wiedzieć to jak w zbiorze umieścić znaki [ oraz ] przecież to one definiują zbiór.
Jest na to bardzo proste rozwiązanie, dodajemy znak \, który eliminuje specjalne znaczenie znaków w pisanych wzorcach.
Więc jeśli chcemy zdefiniować zbiór, w którym mają się znaleźć nawiasy kwadratowe to taki zapis może wyglądać następująco [\[\]]
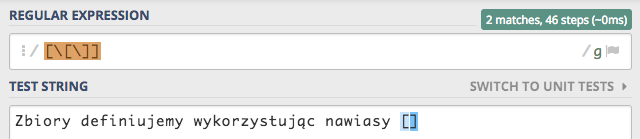
Przejdźmy do bardziej praktycznego zastosowania zbiorów. Powiedzmy, że chcielibyśmy wzbogacić nasze przeszukiwanie
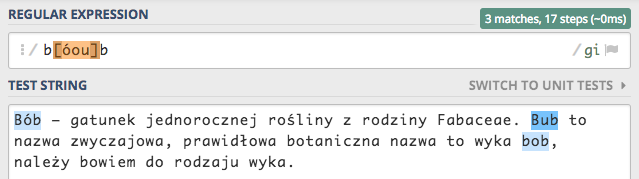
o eliminację błędów ortograficznych. Do tego celu posłużymy się zbiorami, szukane słowo to bób. Zdajemy sobie sprawę,
że ktoś mógł wpisać bub lub bob i takie słowa też mają zostać znalezione. W związku z tak określonymi wymaganiami nasze
wyrażenie powinno wyglądać następująco b[óou]b
Zakresy
Pisanie w wyrażeniach regularnych pełnej listy znaków byłoby nieco irytujące. Za każdym razem wpisywanie do zbioru listy cyfr z przedziału od 0 do 9, czy liter od A do Z mogło by spowodować załamanie u wielu programistów ;)
Problem ten został rozwiązany w bardzo elegancki sposób. Do naszej dyspozycji zostały oddane zakresy, które są dla nas bardzo naturalne i nikt nie powinien mieć problemów z ich zrozumieniem.
Cyfry
Definiując wyrażenie regularne, które ma mieć w zbiorze wszystkie cyfry mogli byśmy je zapisać następująco [0123456789].
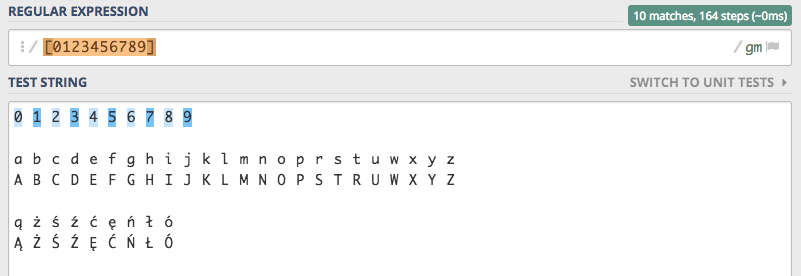
Widać, że zbiór spełnił swoją rolę i zostały znalezione wszystkie cyfry. Jednak zapis ten jest dość rozwlekły i mało elastyczny.
Prościej moglibyśmy zapisać ten zbiór stosując zakresy, odpowiednikiem zbioru [0123456789] będzie zbiór z zakresem [0-9].
Prawda, że zapis wydaje się bardzo naturalny :)
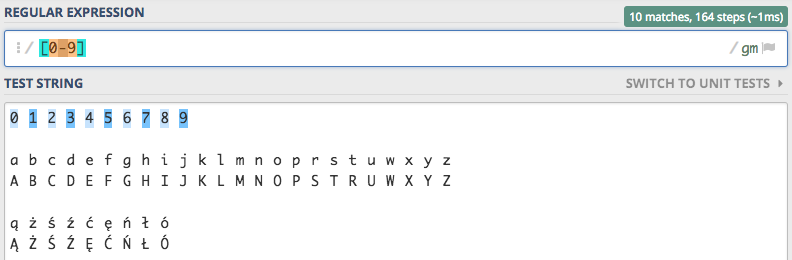
Wynik działanie jest dokładnie taki sam, a prostota w definiowaniu zakresu cyfr ogromna. Możemy zdefiniować dowolny zakres np. 1-6
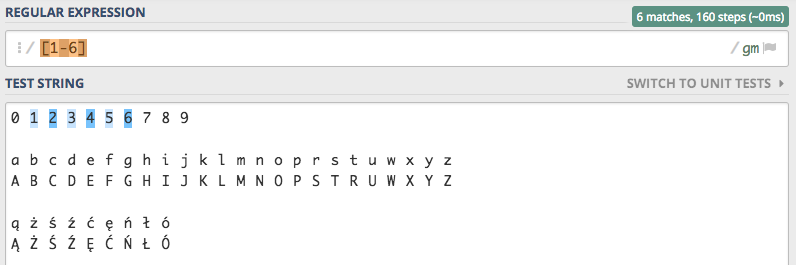
Jest tylko jeden warunek, zakres musi być prawidłowy. W przypadku gdybym podali nieprawidłowy zakres zostanie zwrócony błąd.
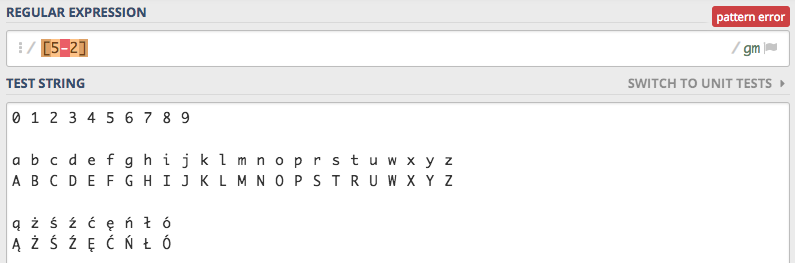
Litery
Definiowanie zakresów liter działa dokładnie na tej samej zasadzie co cyfr. Czyli przykładowy zbiór liter [abcdefghijklmnoprstuwxyz]
będzie można zapisać w postaci [a-z].
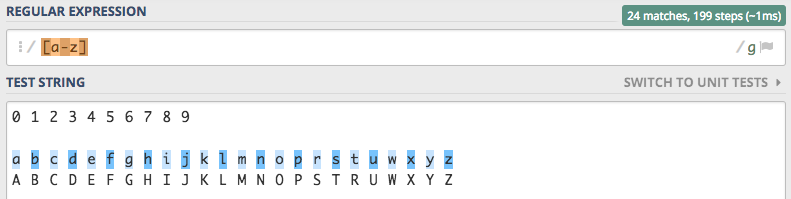
Jedyne co rzuca się w oczy to fakt niezaznaczenia liter pisanych z dużej litery. Możemy to rozwiązań na dwa sposoby,
pierwszy który już znamy to użycie flagi i.
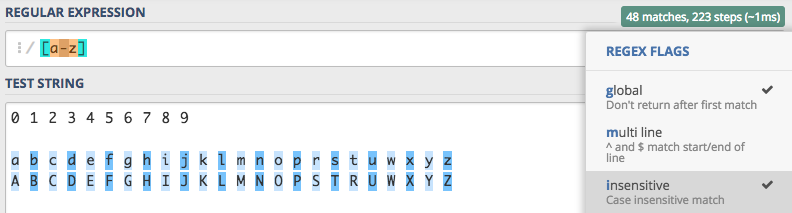
Drugi sposób to dodanie kolejnego zakresu, tym razem dla liter pisanych dużymi literami A-Z. Całe wyrażenie w typ
przypadku wyglądało by następująco [a-zA-Z].
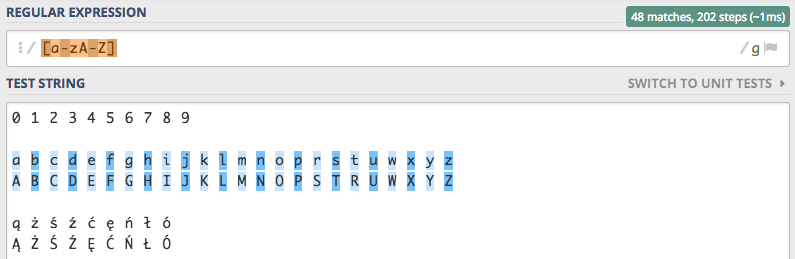
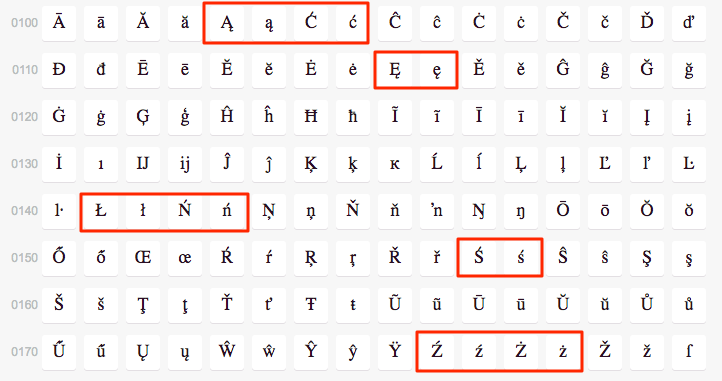
Tak zdefiniowane zakresy jednak nie biorą pod uwagę znaków narodowych. Wynika to z faktu, że silniki wyrażeń regularnych nie znają kolejności liter. Posługują się one numerami indeksów liter z tabeli Unicode, i na podstawie tych numerów weryfikują czy dana litera należy do zakresu czy nie.

Jak widać na powyższej tablicy znaków, teoretycznie możemy zdefiniować zakres, który obejmował by od razu małe i duże litery [A-z]
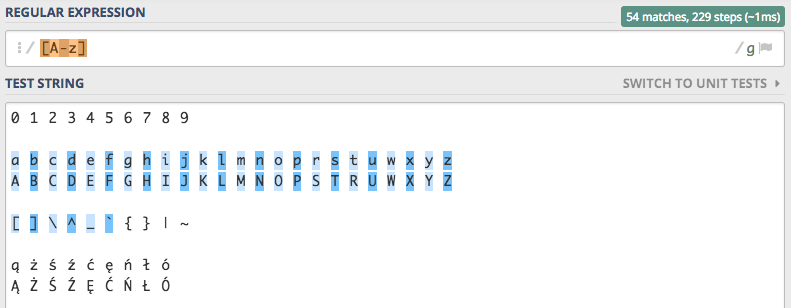
Tak zdefiniowany zakres ma jedną zasadniczą wadę. Włącza także znaki znajdujące się pomiędzy małymi i dużymi literami.
Więc używanie go jest bardzo nierozważne. Podobnie będzie w przypadku naszych rodzimych ogonków, które zostaną
zakwalifikowane do zakresu Ą-ż.
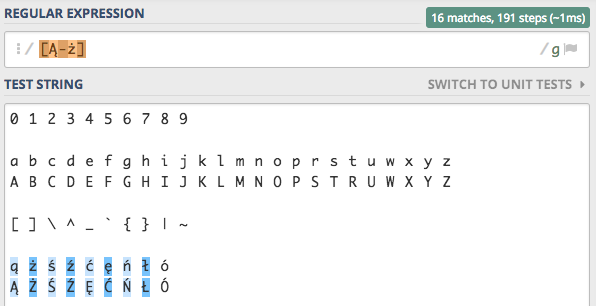
Niestety w zakres nie wpadnie mała i duża litera ó, ale za to wpadnie dużo innych znaków, co może rodzić spore konsekwencje. Dlatego dla znaków narodowych nie definiujemy zakresów.
Białe znaki
Białe znaki czyli spacje, tabulatory i znaki nowej linii są zapisywane w określony sposób w pisanych wyrażeniach regularnych. Wyjątkiem może być spacja, którą możemy zapisać po prostu jako spację, pod warunkiem że flaga extended jest wyłączona.
I tak poszczególne znaki odpowiadają określonym białym znakom:
\ – spacja
\t – tabulacja
\n – nowa linia (ang. line feed – LF)
\r – powrót karetki (ang. carriage return – CR). Jeśli nie spotkaliście się nigdy z tym określeniem to może zainteresuje
was mała ciekawostka. Określenie to, jest zaszłością z maszyn do pisania. Tam zanim została zaczęta nowa linia,
najpierw była przesuwana kartka (CR), a dopiero po jej przesunięciu następowało przejście do nowej linii (LF).
I tu moglibyśmy zakończyć rozmowę o białych znakach, gdyby nie jeden mały szczegół. Mianowicie różne systemy operacyjne zapisują znak nowej linii w nieco inny sposób :(
Unix / Linux / Mac OS X (LF) – \n
Mac OS (CR) – \r
Windows (CR LF) – \r\n
Rozwiązaniem tego problemu może być użycie klasy znaków \R, jednak nie wszystkie implementacje silnika RegEx posiadają
to rozwiązanie (PCRE ma je zaimplementowane). Problem ten dotyczy nas tylko w przypadku, gdy musimy zaimplementować
przetwarzanie plików z różnych systemów operacyjnych.
Skrótowe klasy znaków
W związku z bardzo częstym wykorzystywaniem pewnych zakresów i grup znaków, zostały opracowane skrótowe zapisy tych najczęściej wykorzystywanych zbiorów.
I tak do naszej dyspozycji zostały oddane skróty:
\d – cyfry,
\D – wszystko poza cyframi,
\w – cyfry i litery (jeśli jest włączona flaga Unicode to także znaki narodowe),
\W – wszystko poza cyframi i literami (jeśli jest włączona flaga Unicode to także znaki narodowe),
\s – białe znaki,
\S – wszystko poza białymi znakami
Kropka
Specjalny znak, który jest w stanie zastąpić każdy inny, poza jednym drobnym wyjątkiem. Tym wyjątkiem jest znak nowej
linii. Jeśli nasze wyrażenie będzie składało się tylko i wyłącznie z kropki . to otrzymamy taki efekt.
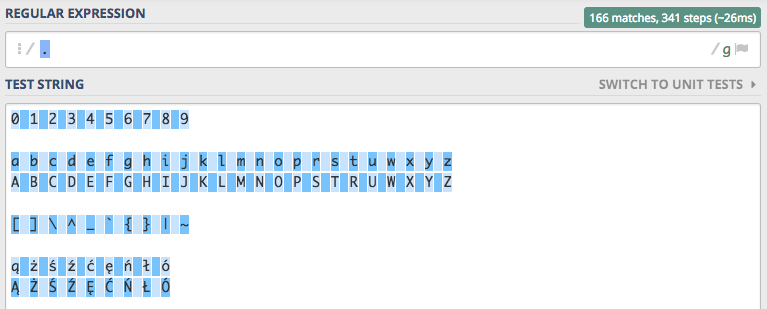
W wyniku działania otrzymaliśmy 166 dopasowań, czyli wszystkie znaki jakie znajdują się w treści. Dopasowane zostały
małe i duże litery, cyfry, znaki specjalne nawet znaki narodowe, jednak w tych dopasowaniach nie znajdziemy znaku nowej
linii. Aby kropka dopasowywała znak nowej linii konieczne jest włączenie flagi Single line s.
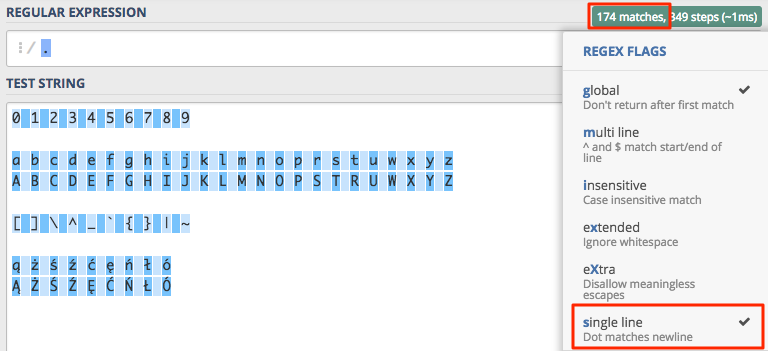
Po włączeniu flagi s liczba dopasowań wzrosła do 174, czyli w tekście znajduje się 8 znaków nowej linii.
Alternatywy
Mechanizm alternatyw pozwala nam w bardzo prosty sposób wprowadzić sprawdzanie kilku warunków. Alternatywy mają swój
znak specjalny |, którym rozdzielamy kolejne warunki.
Prosty przykład, chcemy wyszukać słowo Lorem lub Sed. Do tej pory konieczne było by napisanie dwóch wyrażeń, pierwsze
Lorem i drugie Sed. Wykorzystując alternatywy, możemy rozwiązać ten problem za pomocą jednego wyrażenia regularnego Lorem|Sed.
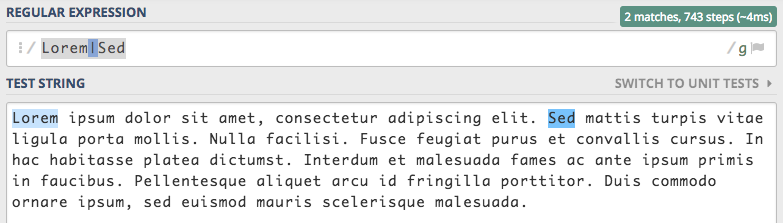
Żeby jednak nie było tak kolorowo to należy zwrócić szczególną uwagę na kolejność deklarowania warunków. Zdefiniowanie
zbyt ogólnego warunku może spowodować, że ten warunek zagarnie pozostałe przypadki. Zobaczmy o co chodzi w praktyce,
szukamy w tekście imienia Piotr oraz jego zdrobnień. Czyli nasze wyrażenie mogło by wyglądać następująco Piotruś|Piotrek|Piotr
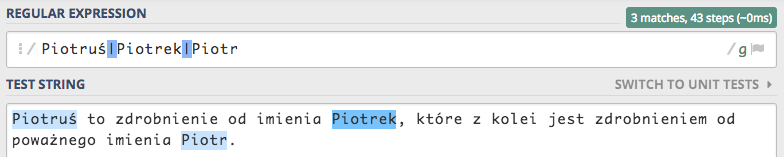
Wynik w pełni zadowalający, znaleziono imię i jego zdrobnienia. Jednak jeśli imię Piotr umieścimy na samym początku to wynik może nieco się różnić od naszych oczekiwań.
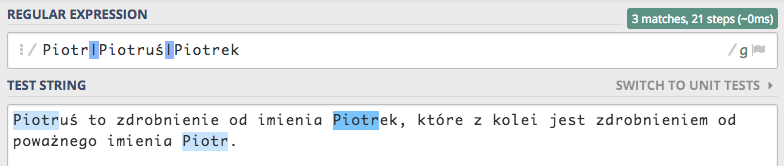
Wynika to z faktu, że w imieniu i zdrobnieniach znajdziemy pierwszą frazę testową Piotr tym samym nie ma potrzeby użycia alternatyw.
Powtórzenia
Powtórzenia to kolejny zapis, który ma na celu ułatwienie nam pracy z wyrażeniami regularnymi. Polega on na określeniu ile razy ma zostać powróżony znak, klasa znaków, grupa czy też inny element wyrażenia znajdująca się przed nim.
Z wiedzą jaką do tej pory zdobyliśmy, zapisanie wyrażenia sprawdzającego np. kod pocztowy mogło by wyglądać następująco \d\d-\d\d\d
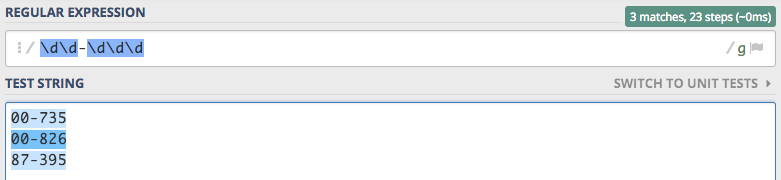
Wyrażenie nie jest idealne, ale spełnia minimalne wymagania i jak widać działa poprawnie. Dzięki powtórzeniom można
je uprościć do zapisu \d{2}-\d{3}
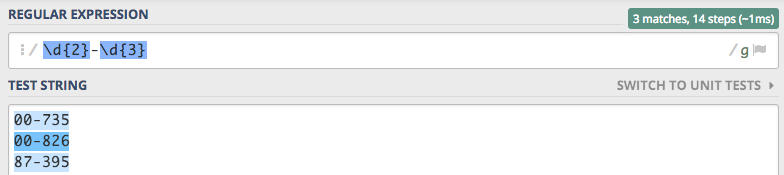
W tym przypadku mówimy silnikowi RegEx, że klasę znaków \d (cyfry) ma powtórzyć 2 razy {2}. Kolejna część zapisu to -,
który występuje w kodzie pocztowym. I ostatnia część to także powtórzenie tylko tym razem klasa znaków \d ma zostać
powtórzona 3 razy {3}. Różnica w szybkości zapisu pomiędzy tymi wyrażeniami jest żadna, ale w czytelności ogromna.
Zobaczmy przykład nieco bardziej skomplikowany, napiszmy wyrażenie radzące sobie z adresami IP. Niech naszym wzorcowym przykładem będzie adres lokalny 127.0.0.1, prościzna prawda ;)
Wyrażenie: \d{3}\.\d{1}\.\d{1}\.\d{1}

Szybkie wyjaśnienie, bo już doskonale wiesz o co chodzi w tym wyrażeniu. Zaczynamy od powtórzenia 3 razy klasy znaków
\d (cyfry). Następnie maskujemy kropkę \., która gdyby nie była zamaskowana pozwoliła by na zapis 127x0x0x1.
I dalej akceptujemy jedną cyfrę, kropkę, cyfrę, kropkę i na końcu cyfrę. Tylko że adresy IP nie wyglądają tylko w ten sposób,
może być jedna cyfra, a mogą być 3. Co w takich przypadkach ? Otóż możemy określać dokładną ilość powtórzeń, ale także
zakresy powtórzeń. Czyli możemy powiedzieć, że może tu być jedna cyfra albo 3.
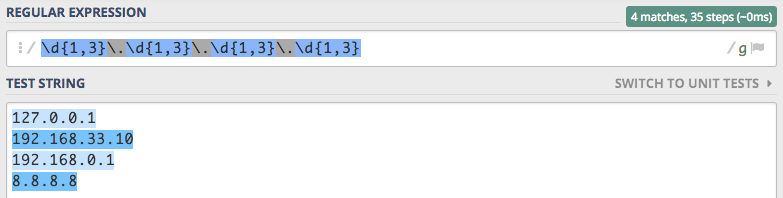
Widzimy jak nasze wyrażenie stało się powtarzalne, a to za sprawą dozwolonej ilości powtórzeń. W naszym przypadku ilość cyfr jaka może zostać powtórzona to minimalnie 1 maksymalnie 3. Jednak to nie jest koniec możliwości jakie dają dozwolone zakresy powtórzeń, poniżej mamy pełną rozpiskę możliwości:
\d{2}– dozwolone 2 powtórzenie cyfr np. 12\d{2,3}– 2 lub 3 powtórzenia cyfry np. 12 i 123\d{2,}– 2 lub więcej powtórzeń cyfr (brak górnej granicy) np. 12, 123, 1234, 12345…\d{0,}– 0 lub więcej powtórzeń cyfr (brak górnej granicy) np. 1, 23, 342, 9873…
I na koniec do rozgryzienia ciut bardziej skomplikowane wyrażenie regularne dopasowujące adresy IP wykorzystujące powtórzenia i alternatywy.
Wyrażenie: \d{1,3}\.|\d{1,3}
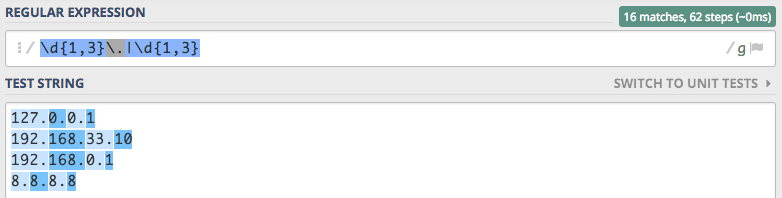
Działa, ale ma błąd ;) Jestem ciekaw czy szybko je wyłapiecie i napiszecie dlaczego jest błąd oraz jak go naprawić.
Skrócona notacja powtórzeń
Powtórzenia są na tyle popularnym rozwiązaniem, że doczekały się skróconej notacji. I to zapewne z nią spotkacie się częściej niż z samymi powtórzeniami.
{0,1} możemy zapisać za pomocą ? (wystąpienie opcjonalne)
{1,} możemy zapisać za pomocą + (przynajmniej jedno wystąpienie)
{0,} możemy zapisać za pomocą * (zero lub więcej wystąpień)
Zachłanność
Zachłanność jest pewną cechą wyrażeń regularnych, która pozwala na dopasowanie największej możliwej części tekstu do wzorca. Tak zdefiniowany warunek określamy jako zachłanny, mamy także przeciwieństwo takiego zachowania i są to warunki leniwe.
Napiszmy proste wyrażenie, które ma dopasowywać dowolny tekst pomiędzy znacznikami html-a <p></p>. Powiedzmy,
że znaczniki wyglądają jak poniżej, i chcemy wyciągnąć z pomiędzy nich wszystko co może się między nimi znaleźć.
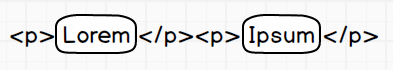
Jako że chcemy pobrać wszystko co zostanie wpisane pomiędzy znaczniki <p> to użyjemy kropki ., gdyż ona jest
dopasowywana do wszystkiego. Po kropce postawimy skróconą notację powtórzeń *, co w praktyce oznacza że pomiędzy
paragrafami może nie być niczego lub dowolna ilośc znaków. Całe wyrażenie będzie wyglądało następująco: <p>.*<\/p>
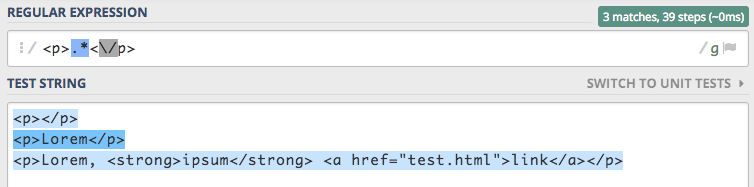
Widzimy tutaj pełen przekrój znaczników <p>, nie zawierające żadnej treści. Mamy znacznik zawierający jedynie prosty
tekst oraz bardzo złożony paragraf zawierający w sobie inne znaczniki. Łącznie mamy 3 paragrafy i wyrażenie znalazło
3 dopasowania. Wydawało by się że wszystko jest zgodnie z naszymi oczekiwaniami, ale czy na pewno ?
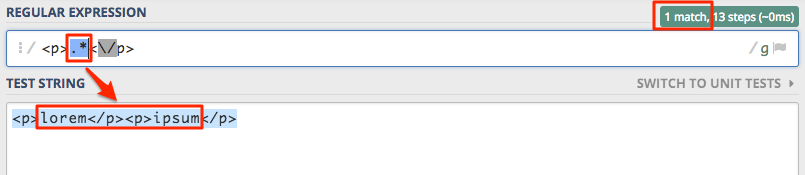
I co my tu widzimy, nasze wyrażenie znalazło tylko jedno dopasowanie, a to już nie jest zgodne z naszymi oczekiwaniami.
Jest to właśnie spowodowane przez zachłanność, brak określenia zachłanności powoduje, że warunek jest zachłanny.
Jest to domyślne zachowanie silnika. Możemy je zmienić poprzez ustawienie flagi U, jednak bardzo często będziemy
chcieli mieszać warunki zachłanne z leniwymi, a tego już nie załatwimy flagą.
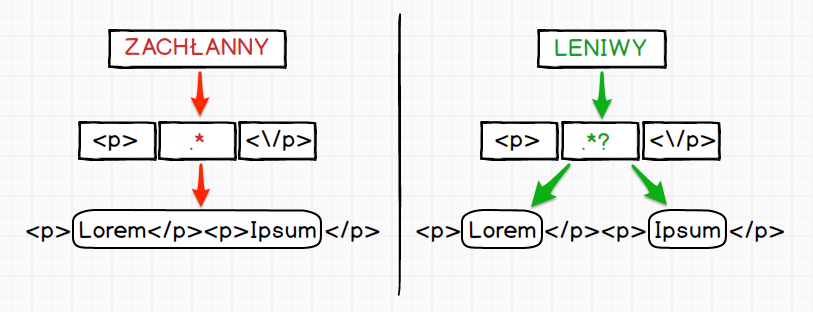
Przekształcenie warunku zachłannego na leniwy jest trywialnie proste, wystarczy dodać na końcu znak zapytania.
Czyli w przypadku naszego wyrażenia drobna modyfikacja zapisu .* na .*? spowoduje, że znajdziemy to o co nam
chodziło na samym początku.

Aby lepiej zobrazować różnicę poniżej przygotowałem porównanie, które powinno pomóc wzrokowcom takim jak ja ;)
Grupy
Grupy są najpotężniejszym mechanizmem w silnikach RegEx i jeśli chcesz używać wyrażeń regularnych, to musisz bardzo dobrze zrozumieć ich działanie. Ale nie martw się, przejdziemy krok po kroku przez wszystkie rodzaje grup i wyjaśnię Ci jak i kiedy używać poszczególnych grup.
Zanim przejdziemy do poszczególnych rodzajów grup to zobaczmy czym są grupy, jak je definiować i co nam dają. Załóżmy, że mamy zadanie napisania wyrażenia regularnego, które sprawdza nam datę.
Najprostsze wyrażenie będzie miało postać \d{4}-\d{2}-\d{2} i jako takie spełnia swoje zadanie weryfikując czy zapis
daty jest poprawny. Jednak nie będzie w stanie nam powiedzieć czy sama data będzie poprawna. Wpisując niepoprawną
datę 2018-14-99 mamy problem, gdyż spełnia ona warunki postawione w wyrażeniu regularnym.
Co w takich przypadkach i czemu mówię o tym w kontekście grup ? Otóż wyrażenia regularne nie będą w stanie przeprowadzić bardzo złożonych walidacji i musimy się z tym pogodzić. Dzięki grupą możemy rozbić datę na małe grupy i się do nich odwoływać, co pozwoli nam przeprowadzić walidację po stronie języka programowania.
Grupy definiujemy poprzez zastosowanie nawiasów półokrągłych, gdzie nawias ( rozpoczyna grupę, zaś nawias ) zamyka daną grupę.
Czyli wyrażenie sprawdzające datę moglibyśmy zapisać z wykorzystaniem grup w następujący sposób (\d{4})-(\d{2})-(\d{2}).
W ten oto sposób jeszcze nic nie wiedząc wykorzystaliśmy grupy przechwytujące, szczegóły w dalszej części ;)
Przechwytujące
Grupy przechwytujące to najczęściej stosowany rodzaj grup. Są conajmniej dwa powody tego stanu rzeczy. Pierwszy to fakt, że pozwalają nam w bardzo prosty sposób odwoływać się do danej grupy. Drugi, większość osób nie wie, że można wyłączyć przechwytywanie ;)
Mamy już wzorzec odpowiedzialny za sprawdzanie kodu pocztowego \d{4}-\d{2}-\d{2}, a po dodaniu grup wygląda ono
następująco: (\d{4})-(\d{2})-(\d{2}). Zobaczmy teraz jak takie wyrażenie zostanie interpretowane przez silnik.

Jest pięknie i kolorowo, tylko co te kolorki oznaczają. Otóż każdy kolor to osobna grupa przechwytująca, a strzałkami zaznaczyłem jak nasze wyrażenie przekłada się zna poszczególne grupy. Jednak żeby było jeszcze lepiej to zaczynamy wykorzystywać sekcję Match information znajdującą się z prawej strony.
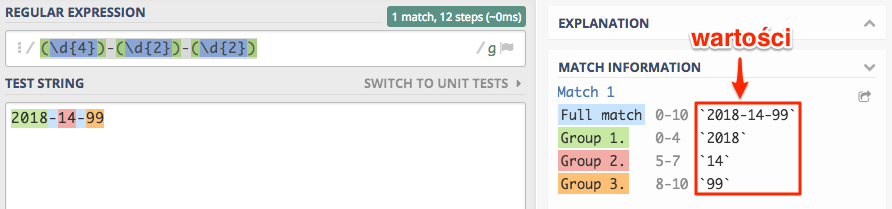
W tym przypadku nie ma już chyba wątpliwości ile grup mamy, która grupa ma jaki kolor. I co nas interesuje najbardziej,
to jakie wartości zostały znalezione w poszczególnych grupach. Tylko pytanie, jak do takich grup się odwołać ? Bardzo prosto,
podajemy numer danej grupy i tyle. Nawet w wyrażeniach regularnych możemy stosować takie odwołania, tylko poprzedzamy
je slashem np. odwołanie do pierwszej grupy wyglądało by tak \1.
Po co nam odwołania do grup w wyrażeniach, mamy nasze wyrażenie rozbijające na grupy datę. Zapis dat w różnych krajach
jest inny czasem różni się tylko separatorem, a czasem kolejnością. Na nasze potrzeby załóżmy, że mamy obsłużyć datę
z kropką. Mała modyfikacja i mamy takie wyrażenie: (\d{4})\.(\d{2})\.(\d{2}), tylko czy nie prościej było by zmieniać
separator w jednym miejscu ?? W tym celu separator opakowujemy w grupę przechwytującą i efekt będzie jak poniżej.
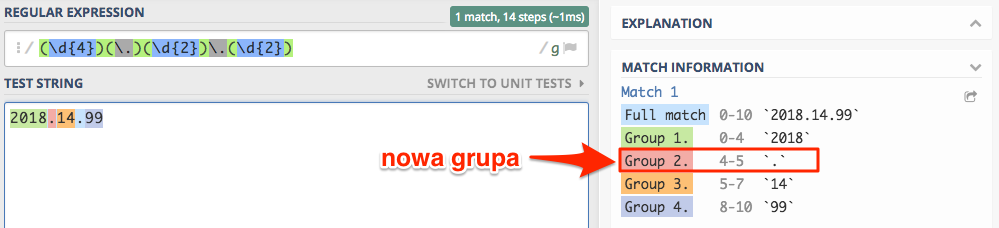
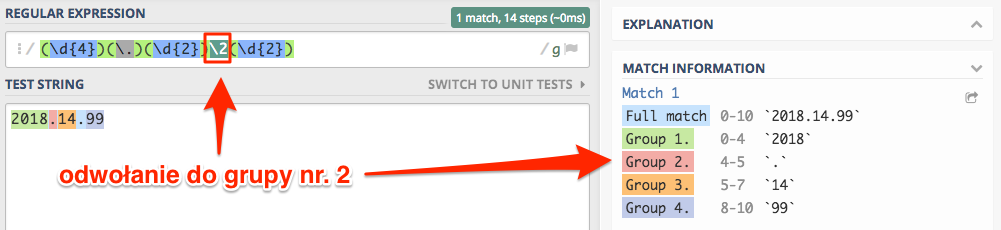
Teraz zamiast drugiej kropki odwołujemy się do drugiej grupy \2 od tego momentu zmiany separatora będziemy wprowadzali
tylko w jednym miejscu.
Nie przechwytujące
Skoro już znamy grupy przechwytujące, to czas poznać grupy nie przechwytujące. Różnica pomiędzy tymi dwoma rodzajami grup jest taka, że jedna zabiera numerek zaś druga już tego nie robi.
Grupę nie przechwytującą zapisujemy w następujący sposób, nawias otwierający grupę ( następnie zapis oznaczający, że
jest ona nie przechwytująca ?:. Dalej mamy nasze wyrażenie i zamykamy grupę nawiasem półokrągłym ).
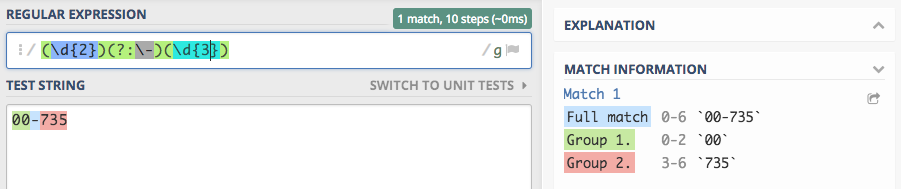
Powyżej widzimy proste wyrażenie regularne (\d{2})(?:\-)(\d{3}) charakterystyczne dla kodów pocztowych. W wyrażeniu
możemy zauważyć, że druga grupa jest nieprzechwytującą co także potwierdza sekcja Match information.
Grupy te stosujemy, aby opakować jakiś fragment wyrażenia nie zabierając jednocześnie numerka. Może to być bardzo istotne, gdy nasze wyrażenia są już wykorzystywane i zmiana numeru referencyjnego może spowodować błędy w aplikacji.
Nazwane
Ostatnim rodzajem grup są grupy nazwane. Grupy te rozwiązują problem z numerami referencyjnymi grup przechwytujących. Każda grupa może dostać swoją nazwę przez którą możemy się do niej odwołać.
Zapis grupy nazwanej jest bardzo zbliżony do poprzednich przypadków, zaczynamy od nawiasu otwierającego (. Następnie
znak zapytania ? i pomiędzy znakiem większości i mniejszości podajemy nazwę np. <YEAR>. Cały zapis może wyglądać
następująco: (?<YEAR>\d{4}) i powinien on przypisać do tej grupy rok z daty.

Jak widać wszystko się zgadza, w Match information mamy nazwę grupy i wartość jaka jest przypisana. Zobaczmy jak wyglądał by zapis całej daty.
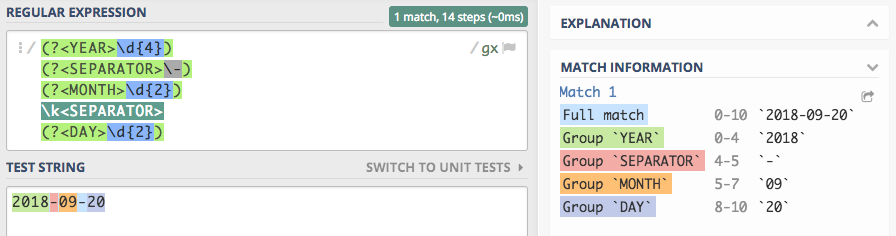
Zapis wyrażenia początkowo może wydawać się nieczytelny, ale musimy się przyzwyczaić do takiego zapisywania wyrażeń.
Na dłuższą metę, są one bardziej czytelne i zrozumiałe dla osoby która kiedyś będzie czytała takie wyrażenie. W tym
przypadku dodatkowo użyłem flagi x, która pozwoliła mi zapisać wyrażenie w wielu linijkach. Każda linijka to osobna
grupa i informacja dla nas na przyszłość. Zobaczmy jak się da taką informację odczytać.
(?<YEAR>\d{4})– grupa przechwytująca rok,(?<SEPARATOR>\-)– grupa przechwytująca separator,(?<MONTH>\d{2})– grupa przechwytująca miesiąc,\k<SEPARATOR>– odwołanie do grupy o nazwie SEPARATOR,(?<DAY>\d{2})– grupa przechwytująca dzień,
Skonfrontujmy to z zapisem bez grup nazwanych:
(\d{4})– grupa przechwytuje 4 cyfry,(\-)– grupa przechwytuje znak -,(\d{2})– grupa przechwytuje 2 cyfry,\2– odwołanie do grupy przechwytującej znak -,(\d{2})– grupa przechwytuje 2 cyfry,
Czy w przypadku drugiej jesteś w stanie powiedzieć co tak na prawdę twórca chciał przechwytywać i do czego może służyć to wyrażenie ??
Inne notacje grup nazwanych
Możecie spotkać się z innymi notacjami grup nazwanych np. w Pythonie grupy te zapisuje się (?P<nazwa_grupy>), a odwołuje
poprzez zapis (?P=nazwa_grupy).
Inna notacja z którą możecie się zetknąć to ?’nazwa_grupy’, a odwołanie do takiej grupy wygląda niemal identycznie jak
to które już widzieliśmy \k'nazwa_grupy'.
Kotwice
Z kotwicami zetkniecie się za każdym razem, gdy będziecie mieli potrzebę walidacji danych prowadzanych przez użytkowników.
Wynika to z faktu konieczności określenia początku i końca tekstu, który chcecie dopasowywać. Przecież nie chodzi nam
o to żeby użytkownik wpisał mój kod pocztowy to 00-736 Warszawa, a nasze wyrażenie regularne go przepuściło. A tak może
się stać, gdybym nie użyli kotwic ewentualnie ich odpowiedników.
Dopasowanie początku tekstu
Znak specjalny ^ już mieliśmy okazję poznać przy okazji omawiania zbiorów. Ma on jeszcze jedno zastosowanie kiedy
znajduje się poza zbiorem, wtedy określa początek ciągu znaków. Tym samy mówiąc silnikowi wyrażeń regularnych,
że ma rozpocząć dopasowywanie na samym początku ciągu znaków.
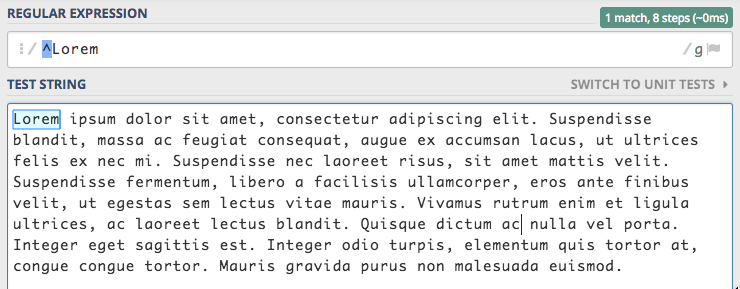
Powyżej mamy wyrażenie regularne, w którym występuje kotwica ^ oraz słowo Lorem. Dla silnika oznacza to, że słowo to
powinno wystąpić na samym początku tekstu. Rzeczywiście takie słowo się tam znajduje i mamy dopasowanie. Możemy jednak
zmienić zachowanie tej kotwicy poprzez włączenie flagi Multi line m. Gdy flaga jest włączona to kotwica szuka wystąpienia
naszego słowa na początku każdej linii.
Widzimy że przy włączonej fladze m zostały zaznaczone słowa Lorem, które rozpoczynają nową linię. Gdybyśmy mieli potrzebę
mieszania obu tych podejść to możemy posłużyć się zapisem \A. Zapis ten zawsze dopasowuje początek tekstu niezależnie
czy flaga m jest włączona czy nie.
Dopasowanie końca tekstu
Skoro mamy kotwicę dopasowującą początek tekstu to musi być kotwica, która dopasuje koniec tekstu. Rzeczywiście taka
kotwica istnieje i została oznaczona symbolem dolara $.
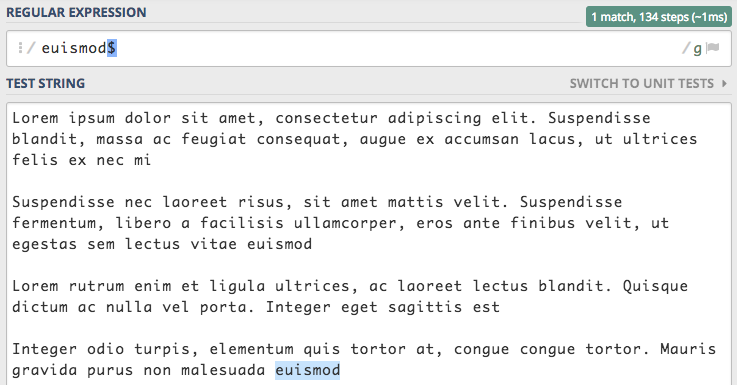
Co ciekawe to dopasowanie akceptuje, aby na końcu tekstu znajdował się jeden znak nowej linii. Gdybyśmy zrobili dwa entery to skończyło to by się brakiem dopasowania.
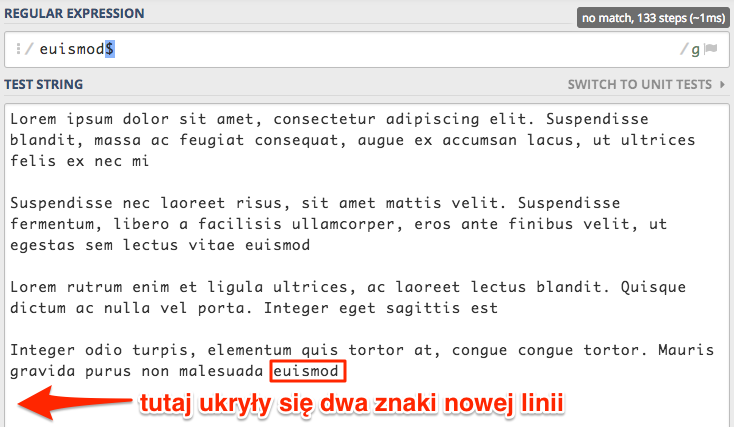
Na tę kotwicę także ma wpływ flaga Multi line m, która powoduje dopasowanie na końcu tekstu znajdującego się w nowej linii.
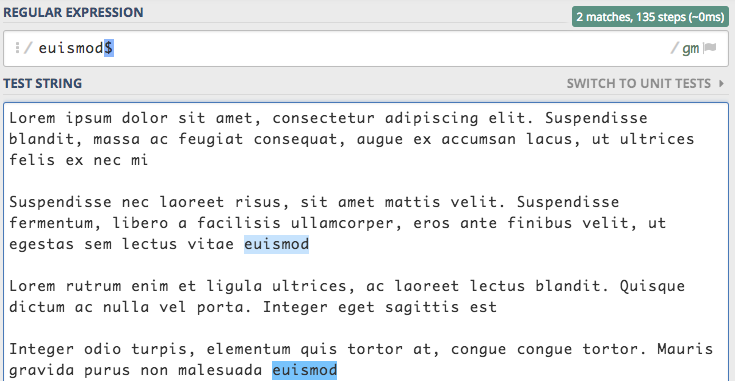
Więc jeśli chcemy mieć 100% pewność, że dopasowanie będzie dotyczyło końca tekstu to musimy użyć zapisu \Z.
Zapis ten także akceptuje znak nowej linii, ale gdybyśmy sobie tego nie życzyli to możemy użyć \z, który już nie akceptuje nowej linii.
Granice
Cześć osób może mylić granice z kotwicami, gdyż są one do siebie bardzo podobne. Granice w odróżnieniu od kotwic nie dopasowują początku tekstu, a wyznaczają granice słowa dzięki czemu jesteśmy w stanie wyeliminować dopasowania części słów.
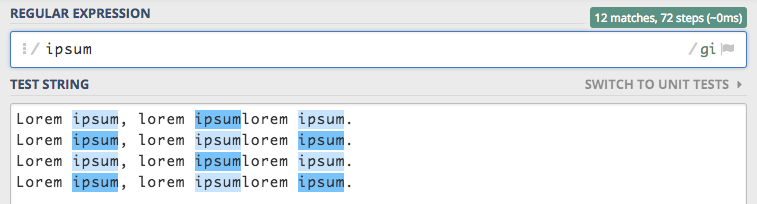
W tekście znaleziono 12 dopasowań z czego 4 są dopasowaniami części innego wyrazu. Możemy się tego pozbyć dodając
po słowie ipsum znak granicy \b.
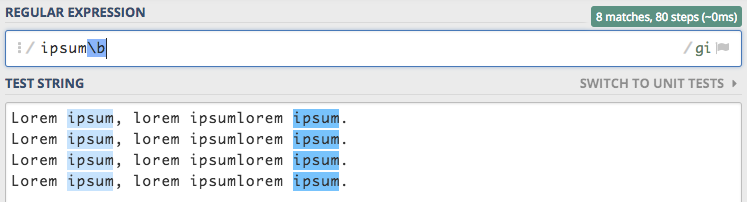
Ta drobna zmiana, a jak potrafi ułatwić życie :) Musimy jednak uważać na znaki narodowe, które mogą sprawić nam małego psikusa.
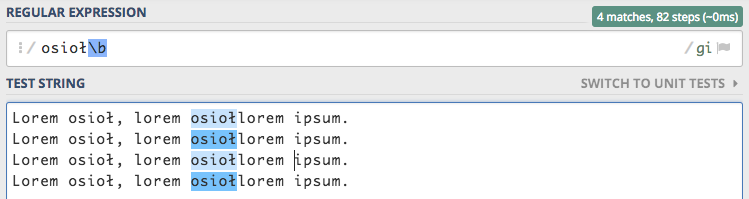
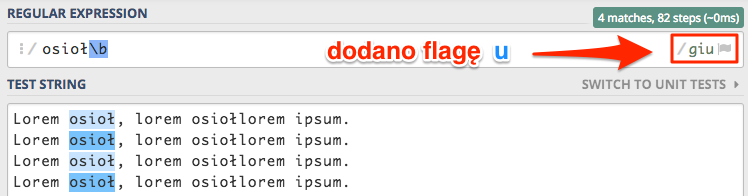
Rozwiązaniem tego problemu jest włączenie flagi Unicode u, która daje nam wsparcie znaków narodowych.
Chcąc mieć pewność w dopasowaniu należy użyć granicy z obu stron wyrażenia. Załóżmy, że chcemy z tekstu wyciągnąć
wszystkie wystąpienia godzin z minutami np. 6:45. Do tego celu możemy posłużyć się wyrażeniem \b\d{1,2}:\d{2}\b,
granice dają nam pewność, że nie weźmiemy pod uwagę części innych wyrazów.
Podsumowanie
Wpis ten wprowadził nas w świat wyrażeń regularnych, które mogły wydawać się czarną magią. Jednak teraz już wiemy jak definiować własne zbiory znaków, czym są klasy znaków, jak tworzyć grupy przechwytujące i wyłączać przechwytywanie oraz wiele więcej.
Pomimo że poznaliśmy tu dość dużo pojęć i mechanik działania, to do pełnego opanowania wyrażeń regularnych konieczna jest praktyka. Jak w każdym nowo poznawanym zagadnieniu, to praktyka czyni mistrzem. Ćwiczcie i nie bójcie się pytać, a kolejnym razem będziemy zgłębiać bardziej zaawansowane aspekty wyrażeń regularnych, na dużo bardziej złożonych przykładach więc uczcie się pilnie ;)