
Jak ElasticSearch analizuje dane przed dodaniem ich do indeksu

W poprzednim wpisie pokazywałem jak wykonać podstawowe operacje w Elasticsearch. Tym razem skupię się na pokazaniu w jaki sposób są analizowane dane przed dodaniem do indeksu oraz wyszukiwaniem.
Wprowadzanie danych
Podczas operacji wprowadzania danych czyli indeksacji, dane są analizowane przez mechanizm, który nazywa się analizerem. Elasticsearch ma własny domyślny analizer o nazwie standard, możemy zobaczyć jak będą wyglądały dane po analizie wywołując requesta:
curl -XGET '127.0.0.1:9200/_analyze?text=Republika+Południowej+Afryki&analyzer=standard&pretty'
W odpowiedzi powinniśmy otrzymać JSON-a podobnego do tego poniżej:
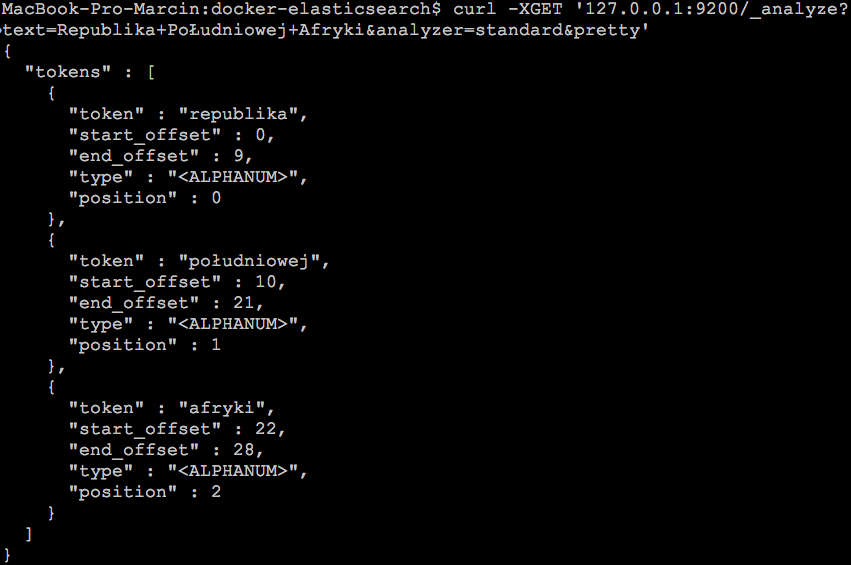
To co widzimy jako wynik działania analizera to rezultat działania dwóch mechanizmów. Pierwszy to tokenizer, który jest odpowiedzialny za rozbicie danych na tokeny. W tym przypadku tokenizer rozbił tekst na trzy tokeny:
- Republika
- Południowej
- Afryki
Po przygotowaniu danych przez tokenizer do głosu dochodzi drugi mechanizm, jakim są filtry. Standardowy analizer zawiera filtr lowercase, zmieniający tekst na małe litery. Po przejściu przez filtry otrzymujemy tokeny:
- republika
- południowej
- afryki
I w ten sposób dane trafiają do indeksu, co ma wpływ na rezultat wyszukiwania. Jest to związane z faktem, że tam także zachodzi operacja analizy choć są pewne odstępstwa od tej regóły.
Wyszukiwanie danych
Analiza danych następuje także na etapie wyszukiwania, w innym przypadku mielibyśmy problem chociażby z wielkością liter przy wyszukiwaniu. Zobaczmy przykład wyszukiwania z poprzedniego wpisu, gdzie było zapytanie wyszukujące:
curl -XGET '127.0.0.1:9200/countries/country/_search?q=name:Polska&pretty'
oraz drugie zapytanie
curl -XGET '127.0.0.1:9200/countries/country/_search?q=name:polska&pretty'
Oba zapytania wyświetliły poprawny wynik, a to dzięki analizie danych podczas przetwarzania zapytania. W obu przypadkach został zastosowany filtr lowercase dzięki któremu udało się znaleźć odpowiedni dokument. Jednak nie zawsze taka analiza zachodzi np. podczas wyszukiwania typu Wildcard.
Wyszukiwanie typu Wildcard
Przy budowaniu wyszukiwarek już chyba standardem stało się pokazywanie wyników na podstawie wpisanego fragmentu frazy przez użytkownika. W przypadku baz danych np. MySQL, mamy do dyspozycji strukturę LIKE, która może wyglądać następująco:
SELECT * FROM country WHERE name LIKE 'P%'
Zapytanie to wyszuka wszystkie kraje zaczynające się na literę “P”. Zapytania takie są bardzo obciążające dla bazy danych jednak przy niewielkich zbiorach akceptowalne. W Elasticsearch mamy także konstrukcję, która pozwala na tego typu wyszukiwania i nazywa się wildcard. Analogiczne zapytanie do tego z bazy SQL-owej może wyglądać następująco:
curl -XPOST '127.0.0.1:9200/countries/country/_search?pretty' -d '{
"query": {
"wildcard": {
"name": "P*"
}
}
}'
Niestety rezultat działania powyższego zapytania nie zwraca żadnego wyniku, a przecież kraj na literę “P” na pewno znajduje się w indeksie.
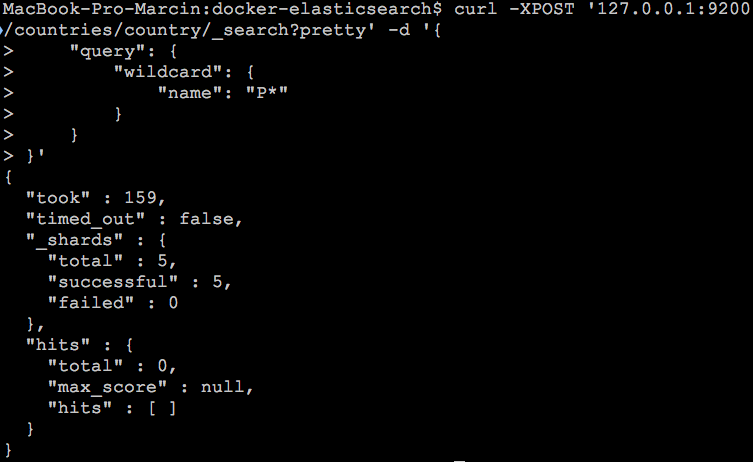
Otóż okazuje się że wyszukiwanie typu wildcard nie analizuje danych, przez co wielkość liter zaczyna mieć znaczenie. Zobaczmy więc jak zmieniając w zapytaniu wielkość litery na małe “p” zmieni się rezultat działania zapytania:
curl -XPOST '127.0.0.1:9200/countries/country/_search?pretty' -d '{
"query": {
"wildcard": {
"name": "p*"
}
}
}'
I teraz w rezultacie otrzymujemy kilka dokumentów:
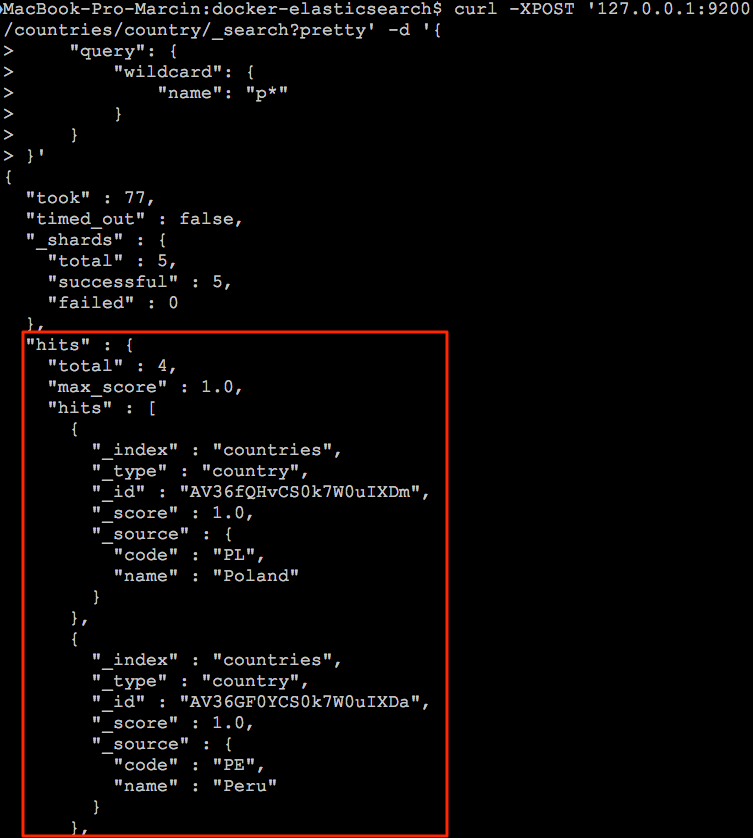
Oczywiście możemy na poziomie naszej aplikacji dokonywać konwersji wprowadzonego tekstu na małe litery, jednak to wyszukiwarka powinna poradzić sobie z wprowadzoną frazą nie zaś nasza aplikacja. Dodatkowo tego typu wyszukiwania są dość wolne wraz z zwiększającą się liczbą warunków. Dlatego powinniśmy rozważyć alternatywne rozwiązanie jakim jest stworzenie własnego analizera. Jednak zanim do tego dojdziemy powinniśmy zapoznać się z dostępnymi analizerami w Elasticsearch.
Przegląd dostępnych analizerów
Elasticsearch ma domyślny analizer, który jest wykorzystywany przy dodawaniu danych do indeksu. Jednak nie jest to jedyny dostępny analizer, mamy do dyspozycji kilka innych z którymi warto się zapoznać.
W celu lepszego unaocznienia różnic pomiędzy analizerami posłużymy się frazą testową.
Microsoft - firma założona w 1975 roku przez Billa Gatesa i Paula Allena.
Przy wypisywaniu tokenów dla powyższej frazy będę stosował zapis tablicowy, aby lepiej unaocznić jakie zmiany zachodzą przy zastosowaniu poszczególnych analizerów.
Standard Analyzer
Standardowy analizer jak już widzieliśmy wcześniej właściwie nie wykonuje żadnych operacji na frazie.
Request:
curl -XGET '127.0.0.1:9200/_analyze?text=Microsoft+-+firma+założona+w+1975+roku+przez+Billa+Gatesa+i+Paula+Allena.&analyzer=standard&pretty'
Tokeny:
[ microsoft, firma, założona, w, 1975, roku, przez, billa, gatesa, i, paula, allena ]
Sama zamiana na małe litery nie ma tutaj większego znaczenia. Istotne jest, że analizer usunął myślnik oraz kropkę na końcu zdania.
Simple Analyzer
Analizer ten w odróżnieniu od standardowego pomija dodatkowo cyfry.
Request:
curl -XGET '127.0.0.1:9200/_analyze?text=Microsoft+-+firma+założona+w+1975+roku+przez+Billa+Gatesa+i+Paula+Allena.&analyzer=simple&pretty'
Tokeny:
[ microsoft, firma, założona, w, roku, przez, billa, gatesa, i, paula, allena ]
W tym przypadku oprócz myślnika i kropki brakuje także roku.
Whitespace Analyzer
Jak nazwa wskazuje analizer ten działa na poziomie “białych znaków”, które w większości wypadków sprowadzają się do spacji w tekście.
Request:
curl -XGET '127.0.0.1:9200/_analyze?text=Microsoft+-+firma+założona+w+1975+roku+przez+Billa+Gatesa+i+Paula+Allena.&analyzer=whitespace&pretty'
Tokeny:
[ Microsoft, -, firma, założona, w, 1975, roku, przez, Billa, Gatesa, i, Paula, Allena. ]
Analizer ten nie zmienił wielkości liter oraz nie pominął znaków typu myślnik czy kropka. Jedynie dokonał prostego podziału na poziomie spacji.
Stop Analyzer
Analizer ten działa tak samo jak Simple Analyzer wzbogacając go o usuwanie słów przystankowych. Już tłumaczę o co chodzi ;)
Otóż w każdym języku w zdaniach mamy elementy, które w przypadku wyszukiwania są zbędne np. w naszej testowej frazie nie ma większego sensu tokenizować “i” oraz “w”. Analizer ten pozwala na pominięcie zbędnych elementów jednak na nasze nieszczęście język polski nie jest obsługiwany, a domyślnie jest ustawiony język angielski. Więc posłużę się frazą z dokumentacji:
The 2 QUICK Brown-Foxes jumped over the lazy dog’s bone.
Request:
curl -XGET "127.0.0.1:9200/_analyze?text=The+2+QUICK+Brown-Foxes+jumped+over+the+lazy+dog's+bone.&analyzer=stop&pretty"
Tokeny:
[ quick, brown, foxes, jumped, over, lazy, dog, s, bone ]
Oprócz standardowego wyeliminowania myślnika, kropki i cyfry zostały usunięte także dwa wystąpienia słowa the.
Keyword Analyzer
Ten analizer jest dość interesujący, gdyż nie analizuje przesyłanej frazy. Jedyne co robi to zwraca całą przesłaną frazę jako token.
Request:
curl -XGET '127.0.0.1:9200/_analyze?text=Microsoft+-+firma+założona+w+1975+roku+przez+Billa+Gatesa+i+Paula+Allena.&analyzer=keyword&pretty'
Tokeny:
[ Microsoft - firma założona w 1975 roku przez Billa Gatesa i Paula Allena. ]
W niektórych przypadkach takie zachowanie może być przydatne. Zwłaszcza, gdy będziemy tworzyli własne analizery.
Pattern Analyzer
Oparcie analizera o wyrażenia regularne wydaje się dobrym pomysłem, gdyż rozwiązanie takie daje nam ogromną swobodę. Jednak cena jest dość wysoka, bowiem pisanie wyrażeń regularnych nie należy do najłatwiejszych zadań.
Request:
curl -XGET '127.0.0.1:9200/_analyze?text=Microsoft+-+firma+założona+w+1975+roku+przez+Billa+Gatesa+i+Paula+Allena.&analyzer=pattern&pretty'
Tokeny:
[ microsoft, firma, za, o, ona, w, 1975, roku, przez, billa, gatesa, i, paula, allena ]
Czyżby lista tokenów was zaskoczyła ;) Jeśli przyj życie się dokładniej zauważycie gdzie leży problem. Otóż nie jest on dostosowany do języka polskiego przez co znaki specjalne powodują problemy.
Domyślnie do wyrażenia regularnego przekazywany jest wzorzec \W+, który powinien rozbić nam zdanie na pojedyncze słowa.
Language Analyzers
Analizer językowy daje możliwość analizy dla konkretnego języka jednak naszego na tej liście nie uświadczycie :(
Dostępne języki: arabic, armenian, basque, bulgarian, catalan, czech, dutch, english, finnish, french, galician, german, hindi, hungarian, indonesian, irish, italian, latvian, lithuanian, norwegian, portuguese, romanian, russian, sorani, spanish, swedish, turkish
Jeśli chcecie zobaczyć jak użyć analizera dla konkretnego języka to proponuję zgłębić tajniki dokumentacji
https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-lang-analyzer.html
Fingerprint Analyzer
Ostatni analizer implementuje algorytm fingerprint, który przeprowadza kilka operacji na frazie którą otrzymuje.
Request:
curl -XGET '127.0.0.1:9200/_analyze?text=Microsoft+-+firma+założona+w+1975+roku+przez+Billa+Gatesa+i+Paula+Allena.&analyzer=fingerprint&pretty'
Tokeny:
[ 1975 allena billa firma gatesa i microsoft paula przez roku w zalozona ]
Pierwsze co rzuca się w oczy to podobnie jak analizer keyword został nam zwrócony tylko jeden token. Przyj żyjmy się zatem jak on wygląda i jakie operacje zostały wykonane na naszej frazie:
- zamiana na małe litery,
- normalizacja, czyli znaki specjalne zamienione na odpowiedniki ASCII,
- posortowanie
- usunięcie duplikatów (której tutaj nie zobaczymy ze względu na ich brak)
Własne analizery
Elasticsearch pozwala na pisanie własnych analizerów, które później używamy czy to do przeszukiwania czy też indeksacji danych. Jednaj jest to temat dość rozbudowany w związku z czym zajmiemy się nim w kolejnym wpisie :)
Dla niecierpliwych odsyłam do dokumentacji, gdzie temat został dokładnie opisany:
https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-custom-analyzer.html
Podsumowanie
Analiza danych jest kluczowym elementem w systemach służących do wyszukiwania. Dzięki analizerom Elasticseach jest w stanie budować indeks, który później jest przeszukiwany i zwracane są nam odpowiednie wpisy. Dlatego zachęcam do zapoznania się z dostępnymi analizerami może spełnią one wasze wymagania zwłaszcza, że większość z nich można dodatkowo skonfigurować. Miłej zabawy :)