
Obsługa języków w ElasticSearch

Tworząc wyszukiwarkę o sensownym poziomie trafności, musimy wziąć pod uwagę obsługę języka. A jak wiemy nasz język do najłatwiejszych nie należy. Sam ElasticSearch także nie wspiera naszego języka, ale pokażę Ci jak pomimo tych przeszkód poradzić sobie z obsługą języka polskiego.
Obsługa języka polskiego w ElasticSearch
Niestety pomimo tego, że ElasticSearch wspiera wiele języków: arabic, armenian, basque, bengali, brazilian, bulgarian, catalan, cjk, czech, danish, dutch, english, finnish, french, galician, german, greek, hindi, hungarian, indonesian, irish, italian, latvian, lithuanian, norwegian, persian, portuguese, romanian, russian, sorani, spanish, swedish, turkish, thai. To na tej liście nie znajdziemy wsparcia dla języka polskiego. Jednak na stronie znajdziemy informację o pluginie, który doda nam obsługę naszego języka.
Plugin analysis-stempel
Plugin ten jest polecanym przez zespół Elastica i znajdziemy o tym informację w dokumentacji. Jednak pamiętajmy, że jest on tylko polecany, a sam zespół Elastic-a nie rozwija go i nie wspiera.
Instalacja pluginów w ElasticSearch jest banalnie łatwa. W tym celu przechodzimy do katalogu, gdzie znajduje się ElasticSearch np. w systemach linuks-owych może to być lokalizacja /usr/share/elasticsearch. Następnie wywołujemy poniższe polecenie:
sudo bin/elasticsearch-plugin install analysis-stempel
Po instalacji pozostaje jedynie zrestartować silnik i możemy się cieszyć wsparciem naszego języka. Plugin dostarcza nam analizer o nazwie polish oraz filtr tokenów polish_stem.
Analizer polish
Używanie analizera jest bardzo proste, i sprowadza się do jego ustawienia dla określonego pola w indeksie. Oczywiście należy o tym pamiętać przy tworzeniu indeksu, gdyż później taka zmiana będzie niemożliwa.
PUT my_index
{
"mappings": {
"_doc": {
"properties": {
"description": {
"type" : "text",
"analyzer": "polish"
}
}
}
}
}
Jeśli jednak chcemy tylko potestować działanie analizera to nie ma potrzeby tworzyć indeksu i zasilać go w dane. Wystarczy odwołanie do _analyze, gdzie podajemy z jakiego analizera chcemy skorzystać oraz tekst jaki ma zostać przeanalizowany za jego pomocą.
GET _analyze
{
"analyzer": "polish",
"text": ["Anna miała czerwoną sukienkę."]
}
W rezultacie otrzymamy tokeny: anna, mieć, czerwony, sukienka. Tokeny te odpowiadają poszczególnym wyrazom w naszym zdaniu, co widać poniżej.
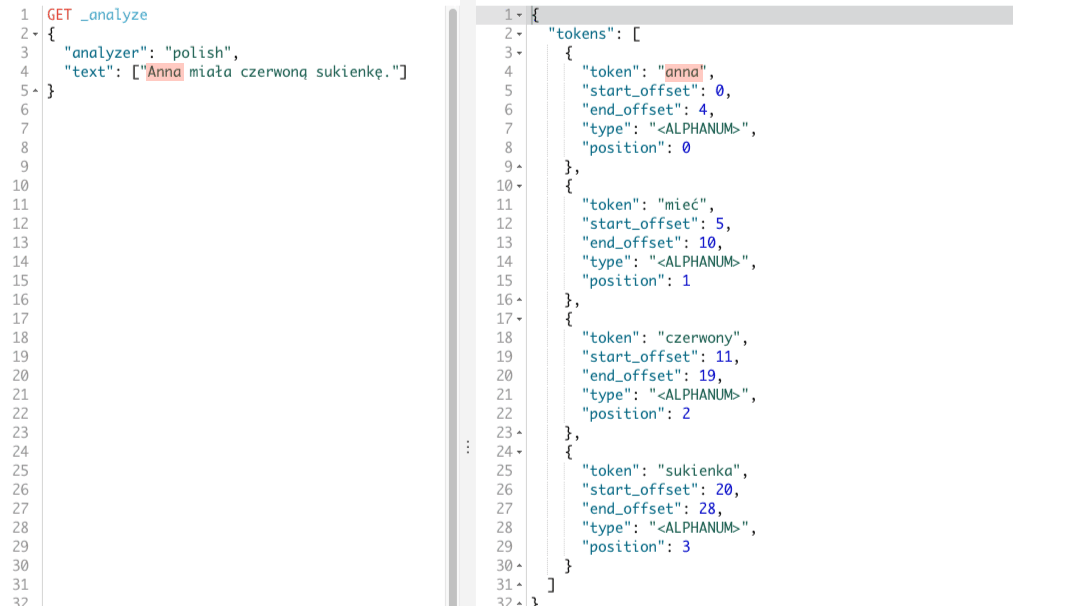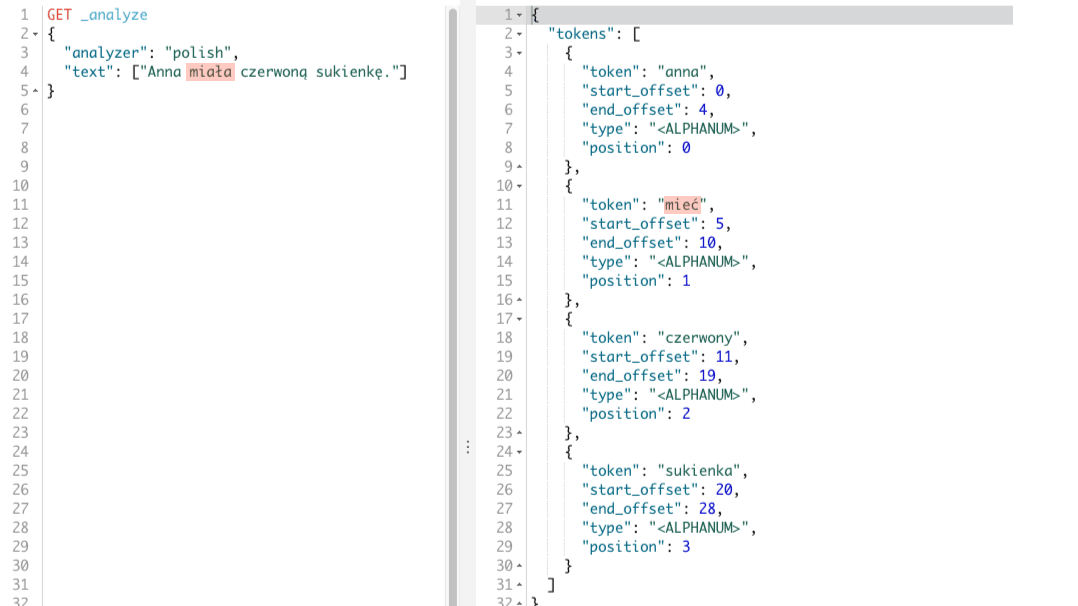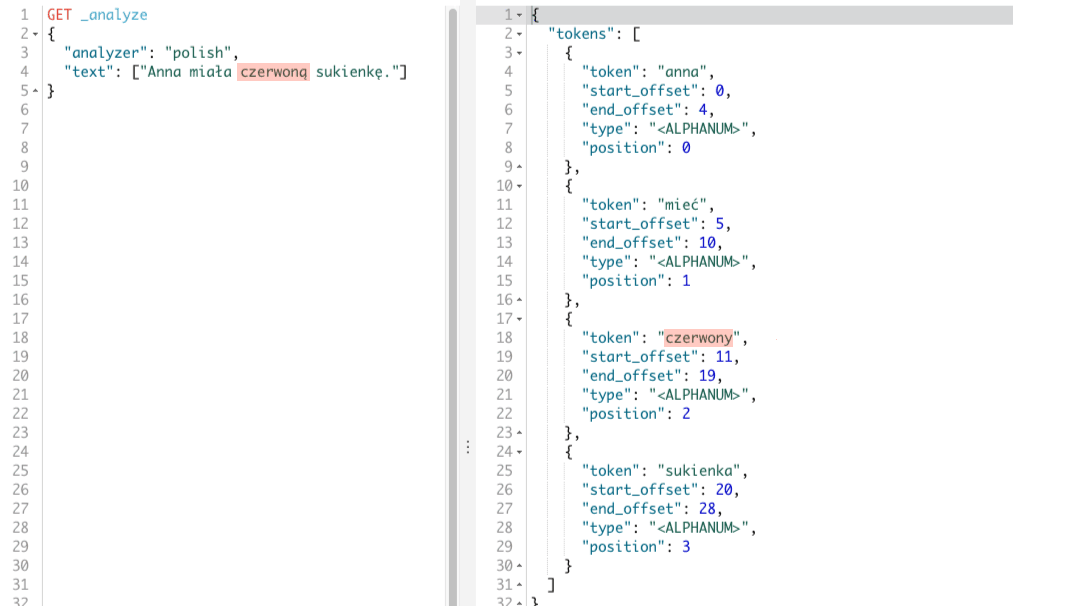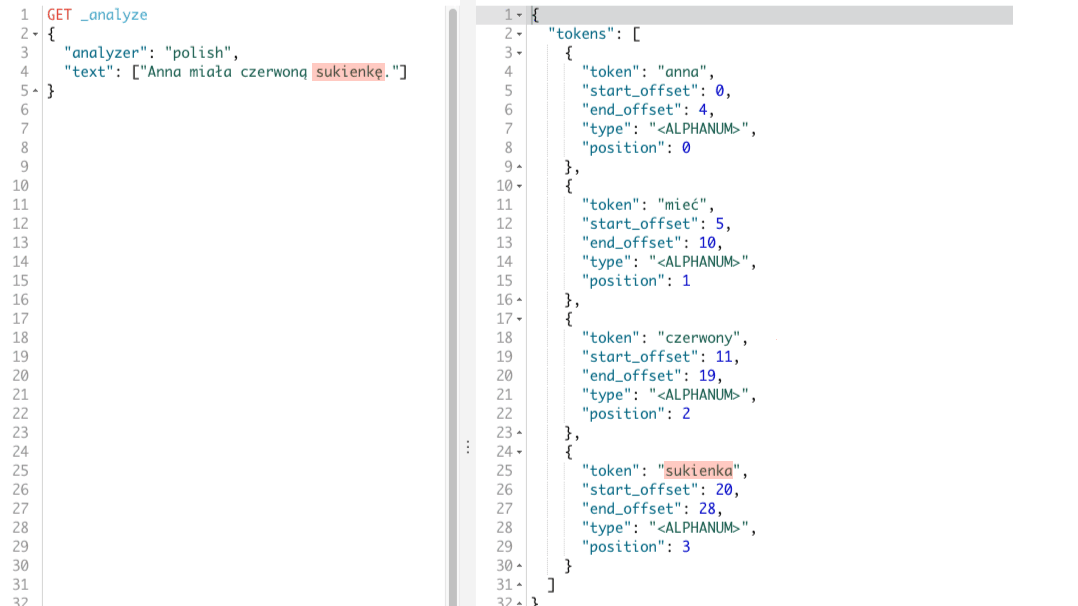
Dostarczenie analizera i łatwość z jaką możemy przeprowadzić na szybko testy jest super. Jednak żeby nie było tak różowo, nie mamy kontroli nad procesem tokenizacji oraz filtrowania co w niektórych przypadkach może się przydać. Dlatego warto zapoznać się z filtrem tokenów, który dokonuje jedynie przekształcenia tokenów na formy podstawowe.
Filtr tokenów - polish_stem
Chcąc skorzystać z filtra tokenów polish_stem konieczne będzie stworzenie własnego analizera. Wynika to z faktu, że filtrowanie tokenów to ostatni proces analizy
PUT my_index
{
"settings": {
"analysis": {
"analyzer": {
"lang_pl": {
"type": "custom",
"tokenizer": "standard",
"filter": [
"lowercase",
"polish_stem"
]
}
}
}
}
}
Teraz możemy przetestować działanie analizera, tak samo jak w przypadku dostarczonego przez plugin. Tym razem analizer nazywa się lang_pl i znajduje się w indeksie my_index
GET my_index/_analyze
{
"analyzer": "lang_pl",
"text": ["Anna miała czerwoną sukienkę."]
}
Wyniki dla tak przygotowanego analizera, będą niemal identyczne jak dla tego dostarczonego wraz z pluginem. Więc możesz zastanawiać się po co używać filtra tokenów, a nie analizera? Otóż chodzi o większy poziom kontroli filtracji i procesu tokenizacji.
Najlepiej zobrazuje to prosty przykład, zmienimy frazę na Wysłałem e-mail do Anny na adres: anna@gmail.com i użyjemy polskiego analizera.
GET _analyze
{
"analyzer": "polish",
"text": ["Wysłałem e-mail do Anny na adres: anna@gmail.com"]
}
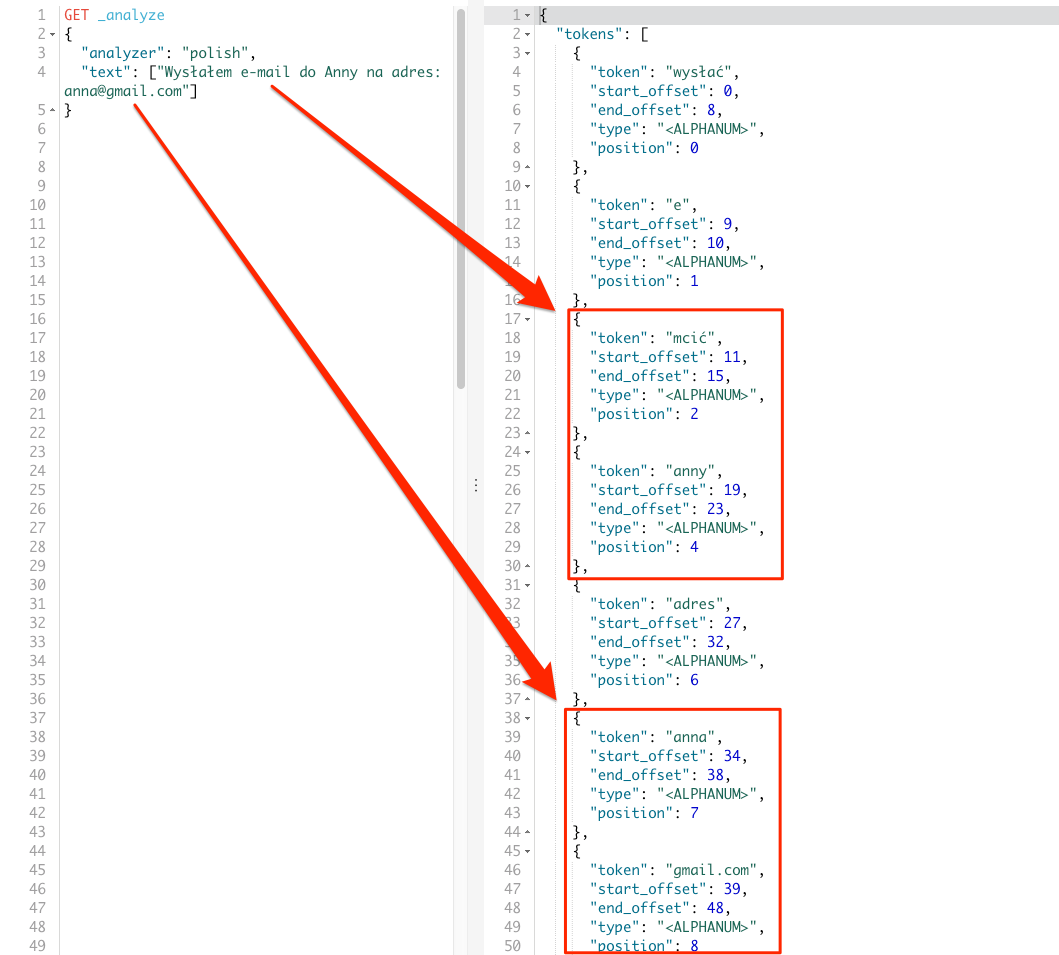
Mam nadzieję, że problem widać od razu. Niepotrzebne robicie słowa e-mail oraz samego adresu anna@gmail.com. Jedyny plus to fakt, że wyraz do został usunięty, ale o tym dlaczego to wyjaśnię przy stopwords-ach.
Rozwiązaniem powyższej sytuacji będzie użycie filtra tokenów oraz zmiana domyślnego tokenizera. W tym celu tworzymy nowy analizer, który nazwiemy lang_pl_whitespace.
Jako że chcemy dodać nowy analizer do istniejącego indeksu musimy najpierw go na chwilę zamknąć. Można to traktować jak zatrzymanie bazy danych, ale tylko dla tego indeksu.
POST my_index/_close
Kiedy indeks jest zamknięty to dodajemy nowy analizer.
PUT my_index/_settings
{
"settings": {
"analysis": {
"analyzer": {
"lang_pl_whitespace": {
"type": "custom",
"tokenizer": "whitespace",
"filter": [
"lowercase",
"polish_stem"
]
}
}
}
}
}
I teraz możemy z powrotem otworzyć indeks.
POST my_index/_open
Skoro nowy analizer jest gotowy to zobaczmy jak zmiana tokenizera wpłynie na wyniki analizy.
GET my_index/_analyze
{
"analyzer": "lang_pl_whitespace",
"text": ["Wysłałem e-mail do Anny na adres: anna@gmail.com"]
}
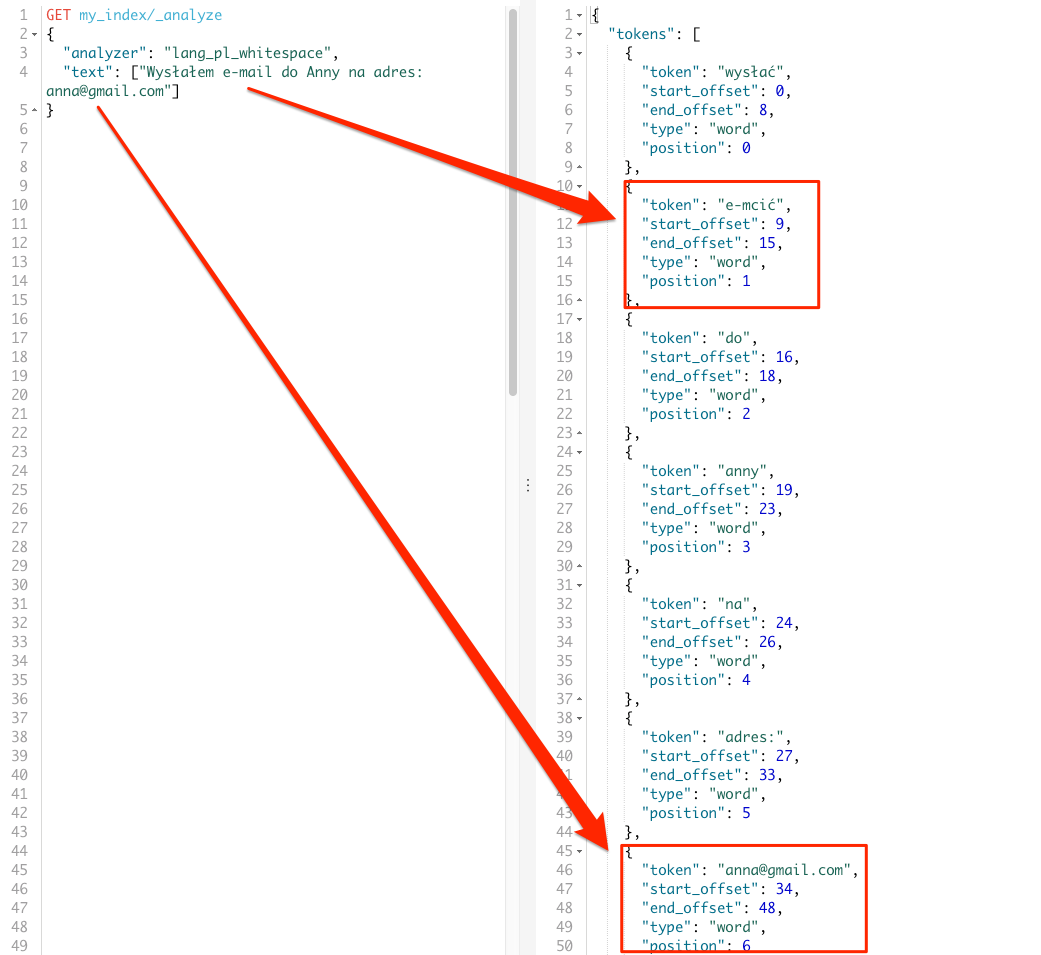
Jest dużo lepiej, wyraz e-mail nie został rozbity choć uległ transformacji, co nie jest sytuacją idealną. Podobnie adres e-mail anna@gmail.com nie został rozbity oraz nie uległ transformacji. Efektem ubocznym zastosowania filtra tokenów jest dodatkowy token do, który jest zbędny i możemy go usunąć poprzez stoprowds-y.
Plugin allegro/elasticsearch-analysis-morfologik
Alternatywnym pluginem dla Analizer polish jest plugin dostarczany przez Allegro allegro/elasticsearch-analysis-morfologik i w niektórych przypadkach działa on zdecydowanie lepiej. Plugin ten bazuje na monterail/elasticsearch-analysis-morfologik, który nie jest już rozwijany.
Instalacja jest tak samo prosta jak w przypadku polecanego plugina. Wystarczy uruchomić polecenie w katalogu ElasticSearch:
sudo bin/elasticsearch-plugin install pl.allegro.tech.elasticsearch.plugin:elasticsearch-analysis-morfologik
Możemy także podać wersję ES dla której ma zostać zainstalowany plugin. W tym celu na końcu polecenia dodajemy dwukropek : i numer wersji np. :6.2.4
bin/elasticsearch-plugin install pl.allegro.tech.elasticsearch.plugin:elasticsearch-analysis-morfologik:6.2.4
Po instalacji wymagany jest restart ElasticSearch-a. Po którym do dyspozycji otrzymujemy analizer morfologik oraz filtr tokenów morfologik_stem.
Skoro już mamy nowy plugin to zobaczmy czy wyniki zmienią się w jakikolwiek sposób dla frazy testowej ?
GET _analyze
{
"analyzer": "morfologik",
"text": ["Anna miała czerwoną sukienkę."]
}
W rezultacie otrzymamy tokeny: Anna, mieć, czerwona, czerwony, sukienka. Tokeny te odpowiadają poszczególnym wyrazom w naszym zdaniu, co widać poniżej.
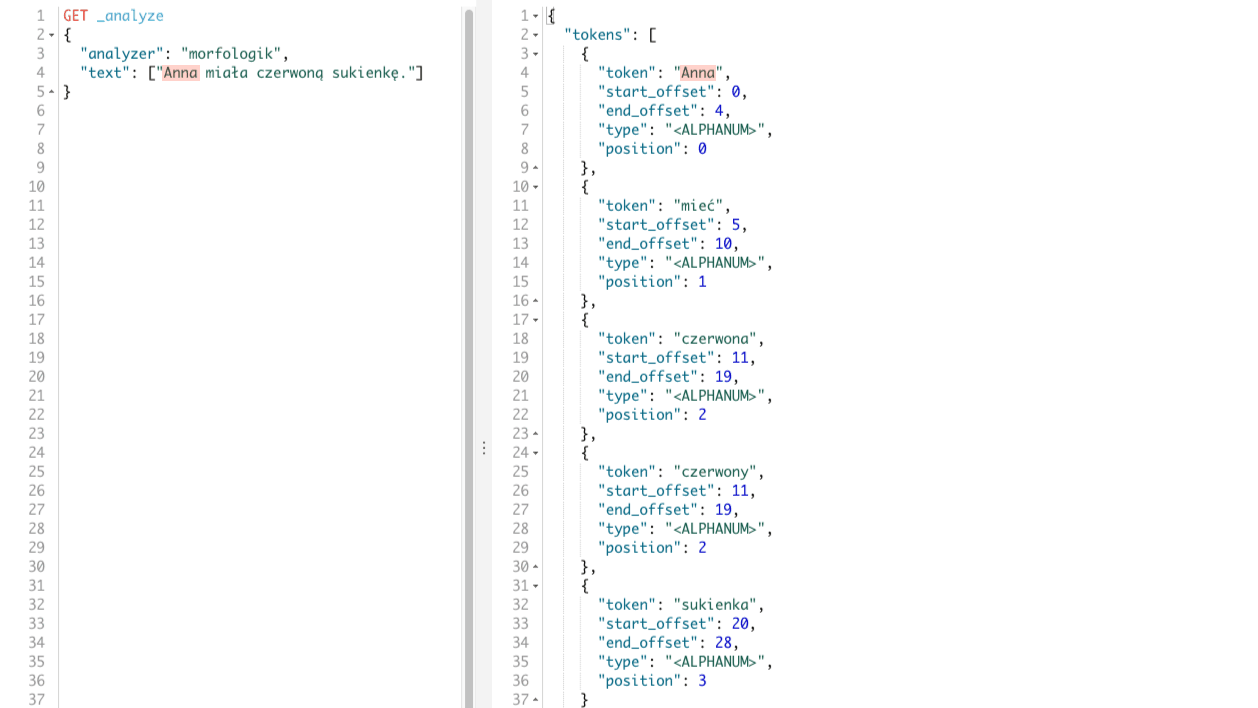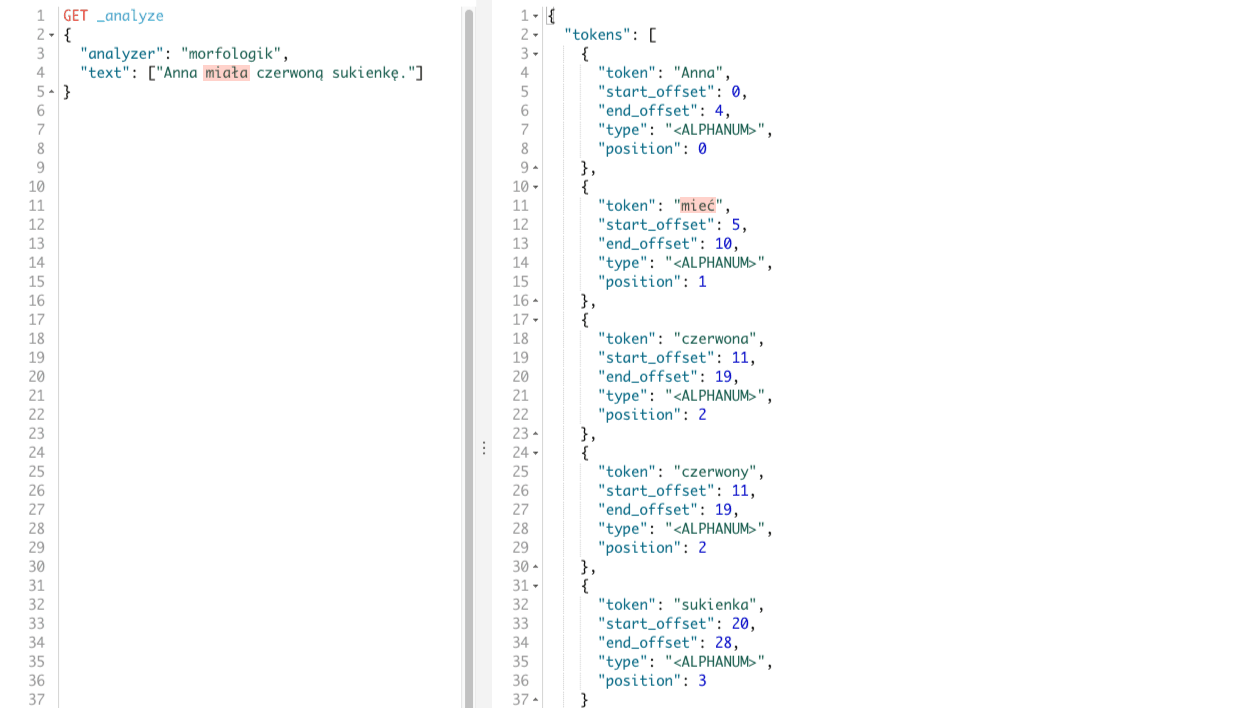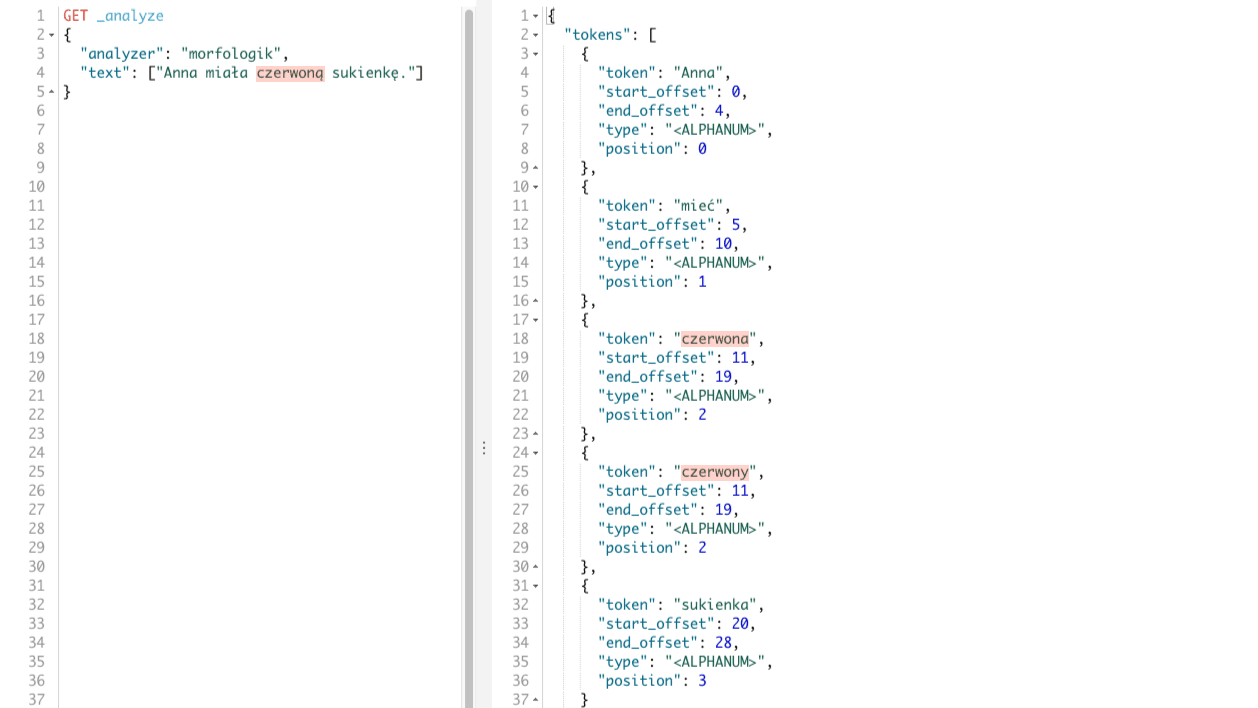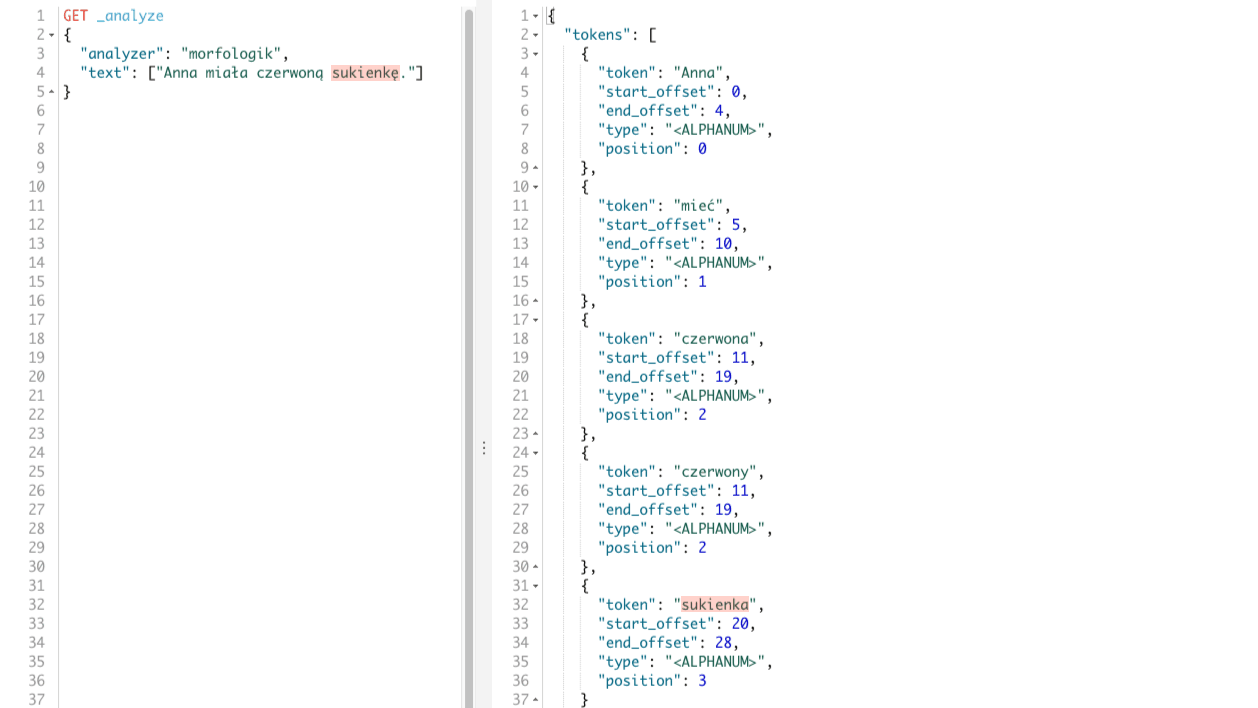
Widzimy, że w stosunku do pluginu analysis-stempel jest drobna różnica. Mianowicie dla wyrazu czerwoną otrzymaliśmy dwa tokeny: czerwona, czerwony co ma uzasadnienie w języku polskim. I według mnie jest lepszym wynikiem. Zobaczmy teraz frazę, która jest nieco bardziej skomplikowana Wysłałem e-mail do Anny na adres: anna@gmail.com. To dla niej zaczęliśmy używać filtra tokenów w poprzednim przypadku.
GET _analyze
{
"analyzer": "morfologik",
"text": ["Wysłałem e-mail do Anny na adres: anna@gmail.com"]
}
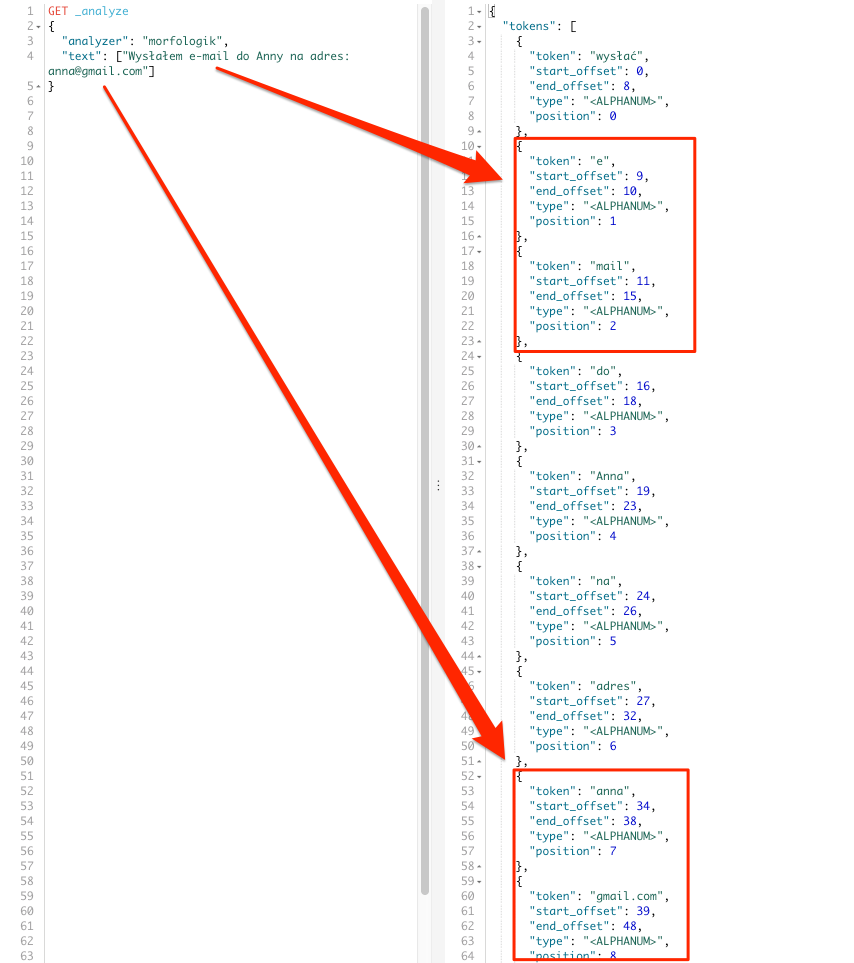
Zmiana pluginu w tym przypadku nie wpłynęła znacząco na poprawę wyników. Choć plusem jest brak transformacji wyrazu mail oraz zmiana imienia na podstawową formę. Znów konieczne jest użycie filtra tokenów.
Filtr tokenów - morfologik_stem
W przypadku tego plugina filtr tokenów nazywa się morfologik_stem. I teraz także zaczynamy od zamknięcia indeksu.
POST my_index/_close
Kiedy indeks jest zamknięty to dodajemy nowy analizer.
PUT my_index/_settings
{
"settings": {
"analysis": {
"analyzer": {
"lang_pl_morfologik": {
"type": "custom",
"tokenizer": "whitespace",
"filter": [
"lowercase",
"morfologik_stem"
]
}
}
}
}
}
I teraz możemy z powrotem otworzyć indeks.
POST my_index/_open
Czas na testy nowego analizera.
GET my_index/_analyze
{
"analyzer": "lang_pl_morfologik",
"text": ["Wysłałem e-mail do Anny na adres: anna@gmail.com"]
}
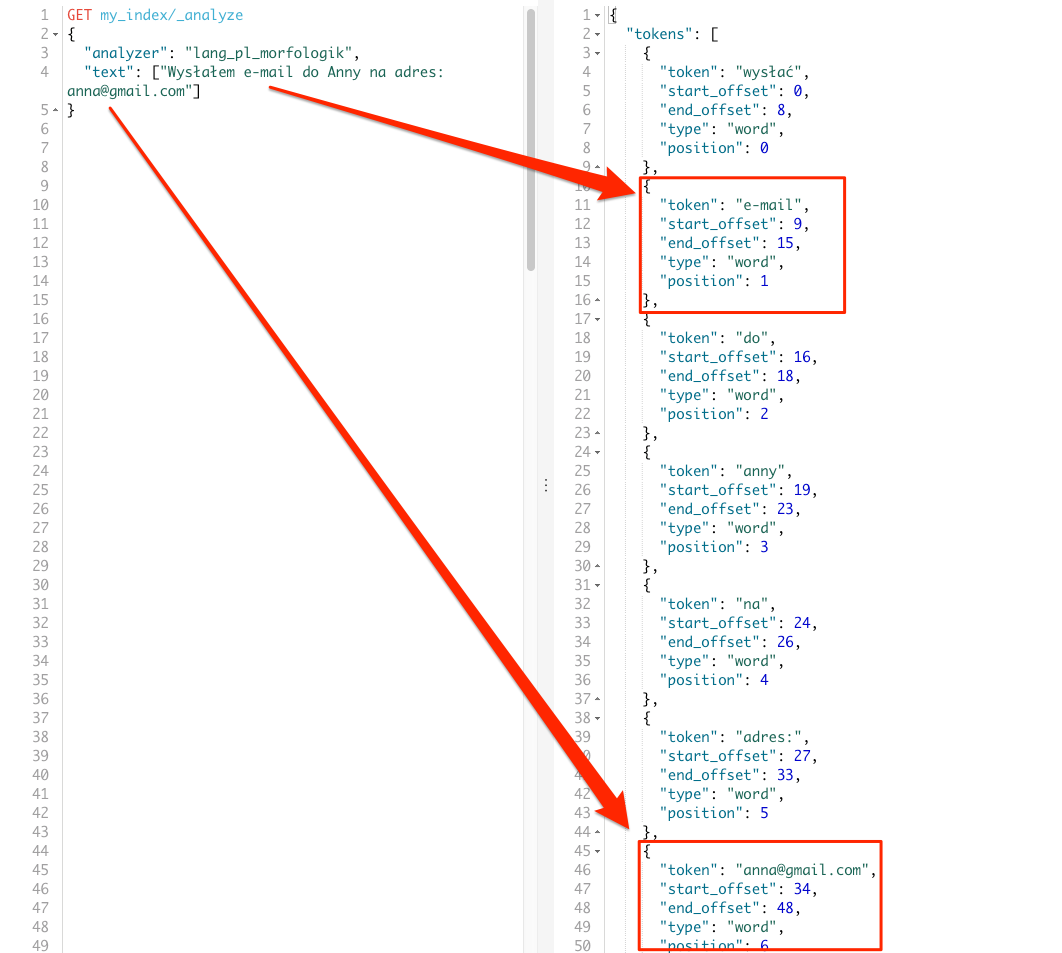
Teraz wygląda to już bardzo fajnie, nie mamy dziwnych transformacji w wyrazie e-mail, oraz sam adres e-mail anna@gmail.com jest pojedynczym tokenem.
Stopwords czyli eliminacja “a”, “i”, “z”…
Podczas indeksowania tekstu spotykamy się ze spójnikami, które niewiele wnoszą do indeksu. W związku z czym dobrze by było, nie indeksować takich tokenów. I właśnie do tego celu został stworzony mechanizm stopwords. Przy językach wspieranych przez ElasticSearch nie ma potrzeby ręcznego definiowania listy słów, które mają być wykluczone. Jednak nasz język nie jest wspierany, w związku z czym musimy sobie taką listę stworzyć sami.
Skorzystanie z tego mechanizmu wiąże się ze zdefiniowaniem własnego analizera oraz filtra. Jako, że będziemy pracowali cały czas na tym samym indeksie to konieczne jest jego zamknięcie.
POST my_index/_close
Teraz możemy dodać nowy analizer zawierający nasz filtr z tokenami do wykluczenia.
PUT my_index/_settings
{
"settings": {
"analysis": {
"filter": {
"pl_stop": {
"type": "stop",
"stopwords": [ "na", "do" ]
}
},
"analyzer": {
"lang_pl_stopwords": {
"type": "custom",
"tokenizer": "whitespace",
"filter": [
"lowercase",
"morfologik_stem",
"pl_stop"
]
}
}
}
}
}
I otwieramy indeks ponownie.
POST my_index/_open
Teraz możemy zweryfikować czy wszystko działa według naszych oczekiwań. Za frazę testową posłuży nam Wysłałem e-mail do Anny na adres: anna@gmail.com, gdzie tokenami do wykluczenia będzie token do oraz na.
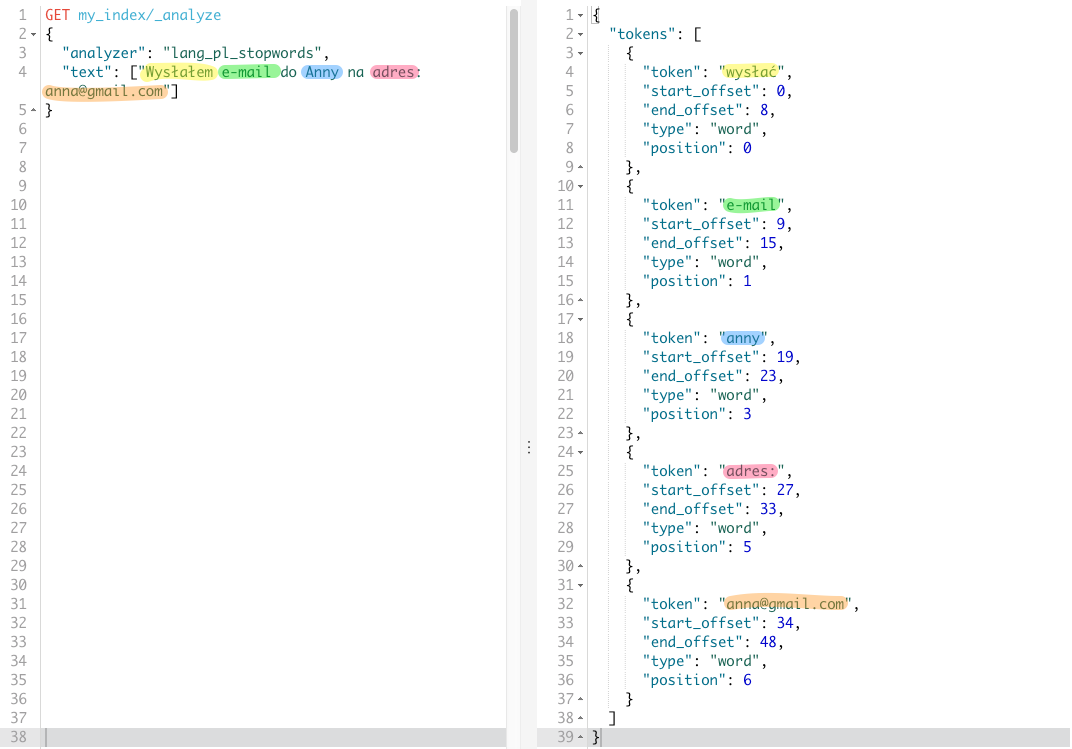
Nowy analizer zwrócił wszystkie tokeny poza tymi wykluczonymi zdefiniowanymi w filtrze pl_stop. Oczywiście tutaj zdefiniowałem tylko dwa przykładowe tokeny, a pełna lista jest dużo dłuższa. Wersję bardziej rozbudowaną znajdziecie tutaj
Synonimy
Ostatnim elementem dotyczącym języka o jakim chciałbym Ci opowiedzieć są synonimy. Dla osób nie kojarzących czym są synonimy krótka definicja z Wikipedii.
Synonim – wyraz lub dłuższe określenie równoważne znaczeniowo innemu, lub na tyle zbliżone, że można nim zastąpić to drugie w odpowiednim kontekście (auto – samochód).
Synonimy w ElasticSearch obsługujemy poprzez definiowanie filtrów z synonimami. Jest to proces bardzo podobny do obsługi stopwords-ów. Zacznijmy od zdefiniowania prostego filtra z synonimami.
"pl_synonym" : {
"type" : "synonym",
"synonyms" : [
"różny, inny",
"istotny, ważny",
"zadanie, cel"
]
}
Zaczynamy od podania nazwy filtra, w tym przypadku wybrałem nazwę pl_synonym. W obiekcie pod kluczem type podajemy typ filtra, tym razem będzie to filtr typu synonym. Na samym końcu podajemy tablicę z synonimami, każdy synonim znajduje się w osobnym elemencie tablicy. Tak przygotowany filtr możemy dodać do ustawień indeksu, a następnie do analizera. W tym celu zamykamy indeks.
POST my_index/_close
Wprowadzamy zmiany w ustawieniach indeksu dodając nowy filtr i analizer.
PUT my_index/_settings
{
"settings": {
"analysis": {
"filter": {
"pl_synonym" : {
"type" : "synonym",
"synonyms" : [
"różny, inny",
"istotny, ważny",
"zadanie, cel"
]
}
},
"analyzer": {
"lang_pl_synonym": {
"type": "custom",
"tokenizer": "whitespace",
"filter": [
"lowercase",
"pl_synonym"
]
}
}
}
}
}
Teraz możemy otworzyć ponownie indeks.
POST my_index/_open
Jak widzicie napisany analizer jest bardzo prosty i korzysta tylko z utworzonego filtra. Jednak na ten moment jest to wystarczające do zobrazowania zasad działania filtra synonimów. Przeprowadźmy zatem jakiś test na nowym analizerze.
GET my_index/_analyze
{
"analyzer": "lang_pl_synonym",
"text": ["zadanie na dziś"]
}
W rezultacie dostaniemy tokeny: zadanie, cel, na, dziś. I takich tokenów oczekiwaliśmy, jednak istnieje możliwość zmiany zachowania filtra. Zmiana ta polega na zastępowaniu danych wyrazów synonimami, nie zaś dodawaniu synonimów do listy tokenów. Aby zmienić zachowanie filtra należy ustawić parametr expand na wartość false.
"pl_synonym_no_exp" : {
"type" : "synonym",
"expand" : false,
"synonyms" : [
"różny => inny",
"istotny => ważny",
"zadanie => cel"
]
}
Dodatkowo należy także zmienić zapis z przecinków na strzałki wskazujące jak ma następować zamiana. Pozostawienie bowiem poprzedniej konstrukcji nie przyniesie pożądanych rezultatów.
Ostatnią rzeczą o jakiej chciałbym wspomnieć to możliwość pobierania listy synonimów z pliku. Zapis powyższy jest fajny jednak przy dużych zbiorach może być nieefektywny. Dlatego w parametrze synonyms_path filtra, możemy wskazać ścieżkę do pliku tekstowego z synonimami.
Podsumowanie
Brak wbudowanej obsługi języka polskiego w ElasticSearch nie jest jakąś dużą przeszkodą, wystarczy nieco chęci ;) Pluginy pozwalają na dość dobrą obsługę transformacji wyrazów, a zbędne spójniki możemy wyeliminować własną listą stopwords-ów. Dodatkowo mamy filtr do synonimów, który pozwala nam na rozszerzenie możliwości językowych pluginów. Na początek jest to dużo więcej niż pozwoli przeciętna wyszukiwarka w bazie danych ;)
Pamiętajcie jadnak że tematy tu poruszone to dopiero podstawy, które wprowadzają w temat obsługi języków. Przykłady tu przedstawione są dalekie od ideału i zaledwie pokazują proces transformacji wyrazów, zasady działania filtrów. Więc jeśli byście chcieli je rozszerzyć, a mieli byście z tym problemy to chętnie pomogę w komentarzach.