
Sposoby wyszukiwania w ElasticSearch

W pierwszym wpisie tej serii opisałem jak konstruować proste zapytania wyszukujące. Był to zaledwie przedsmak tego co można zrobić w ElasticSearch.
Trochę teorii…
Zanim zajmiemy się samym wyszukiwaniem i możliwościami jakie daje ElasticSearch, warto liznąć co nieco teorii. Jednak, jeśli chcesz przejść od razu do mięsa, to się nie obrażę ;)
Indeks odwrócony (ang. inverted index)
Bardzo prosta koncepcja na której bazuje Apache Lucene, a tym samym ElasticSearch. Wyobraźmy sobie, że mamy zbudować indeks ze wskazanego pola w bazie danych. Niech będzie to nazwa produktu np. Samsung Galaxy S9
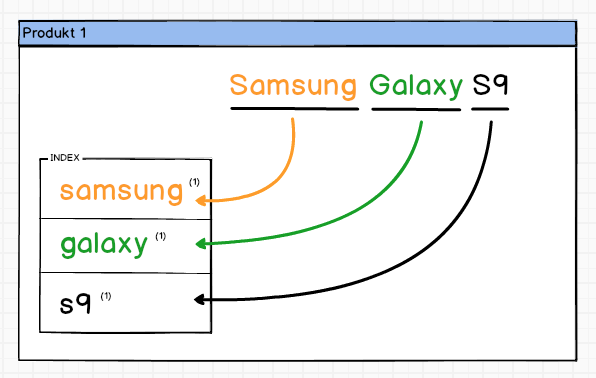
Od razu widać koncepcję, każde słowo to osobny wpis w indeksie. Jeśli słowo się powtórzy to zwiększymy licznik słowa tym samym jego “wartość” rośnie ze względu na ilość wystąpień.
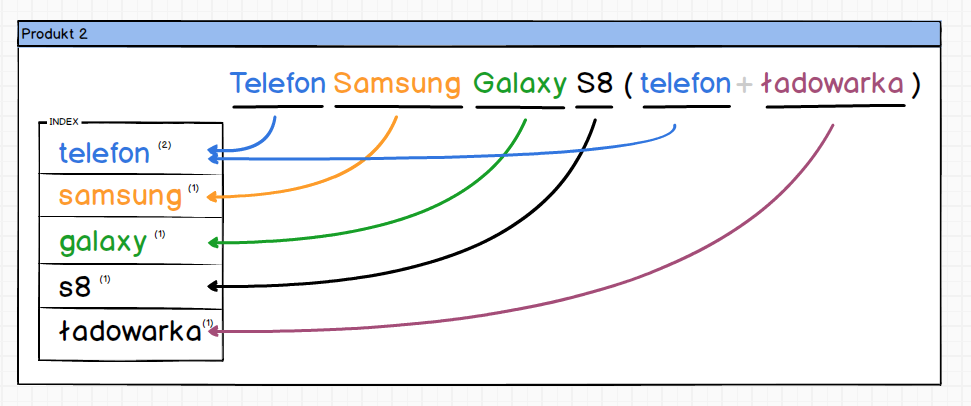
Niestety to podejście ma jedną wadę, aby wyszukać produkty zawierające określone słowo, konieczne jest przejście po wszystkich produktach i sprawdzenie indeksu. A co gdyby tak odwrócić indeks i zapisywać w którym produkcie wystąpiło dane słowo oraz jak często ??
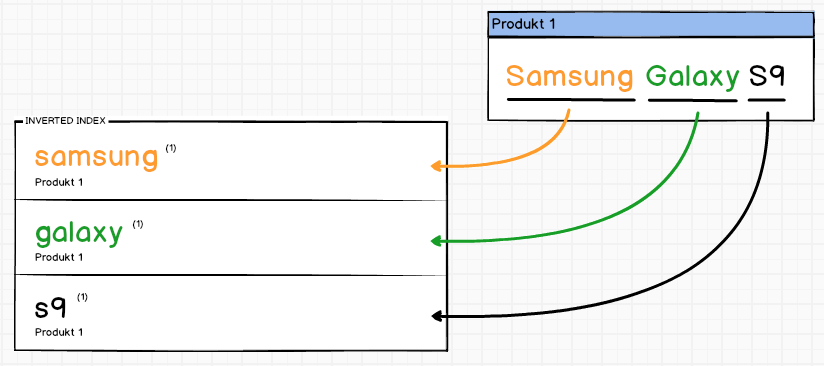
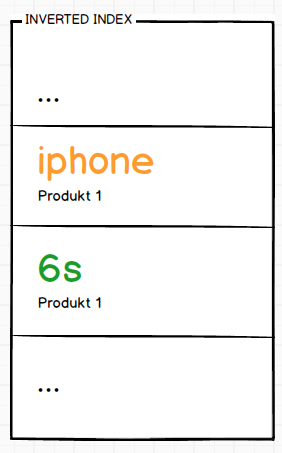
Pierwszy produkt zasilił by nasz odwrócony indeks w następujący sposób:
Zaindeksowanie kolejnego produktu spowodowało by następującą zmianę w indeksie.
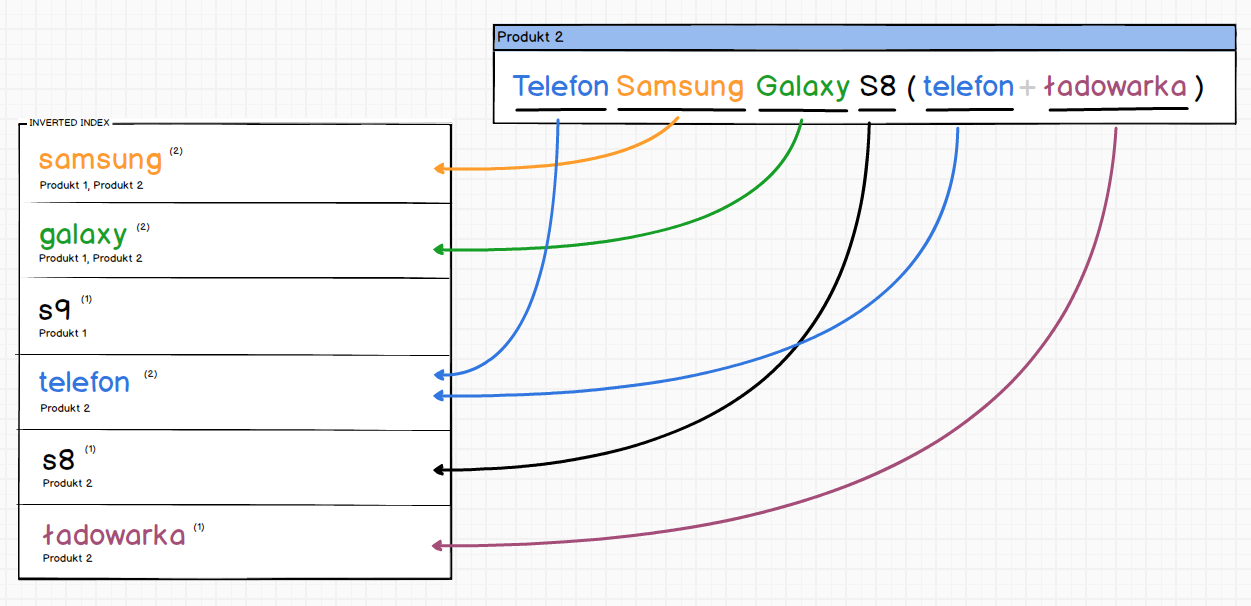
Prawda że proste ;) Każde słowo znajdujące się w odwróconym indeksie posiada informację o produktach w których się znajduje. W związku z czym wystarczy odpytać indeks o słowo, które nas interesuje, a od razu mamy listę produktów.
Oczywiście przedstawione schematy nie odzwierciedlają w 100% mechaniki Apache Lucene jednak oddają jak działa indeks odwrócony.
Odległość Levenshteina czyli Fuzzing
W silnikach wyszukiwania znajdziemy wiele algorytmów, część z nich jest odpowiedzialna za optymalizację przeszukiwania dużych zbiorów danych. Inne są odpowiedzialne za określenie poziomu trafności wyszukanych dokumentów, zaś jeszcze inne za analizę tekstu. W śród nich znajduje się algorytm Levenshteina, który pomaga rozwiązać problem literówek jakie robimy wpisując frazy do wyszukiwarki.
Odległość Levenshteina (edycyjna) – miara odmienności napisów (skończonych ciągów znaków), zaproponowana w 1965 roku przez Władimira Lewensztejna.
– Wikipedia
Kocham takie definicje, nic nie mówią osobie, która nigdy o tym nie słyszała. Spróbujmy nieco to wyjaśnić.
Zacznijmy od tego, czym jest odległość edycyjna ? Bowiem algorytm służy do jej liczenia. Otóż jest to najmniejsza liczba działań prostych, jaką należy wykonać by przekształcić jeden napis na drugi.
Działania proste to:
- wstawienie nowego znaku,
- usunięcie znaku,
- zamiana znaku na inny znak
Skoro znamy podstawy zobaczmy jak wygląda to w praktyce.

Do porównania użyłem wyrazu KOT oraz KOTY, gdyż każdy z nas jest w stanie od razu powiedzieć ile działań należy wykonać, aby przekształcić jeden wyraz na drugi. Odpowiedź to: 1, wystarczy dodać do wyrazu KOT literę Y.
Gdybyśmy odwrócili sytuację i sprawdzali jaka jest odległość Levenshteina między wyrazem KOTY, a KOT ??

Także jedna, tylko w tym przypadku usuwamy literę Y zamiast ją dodawać. Zobaczmy teraz nieco bardziej skomplikowany przykład, gdzie operacji jest nieco więcej.
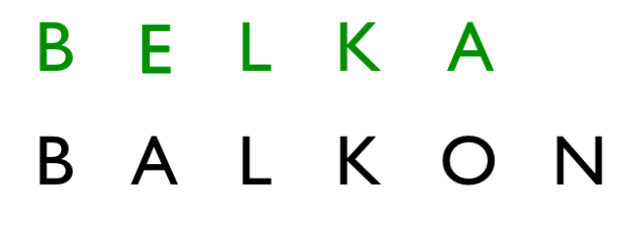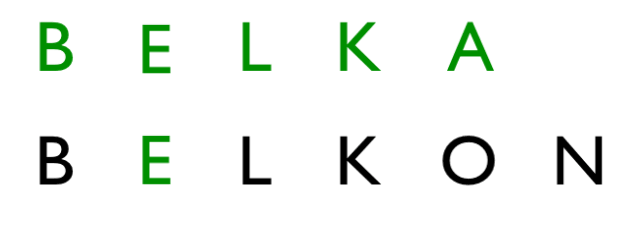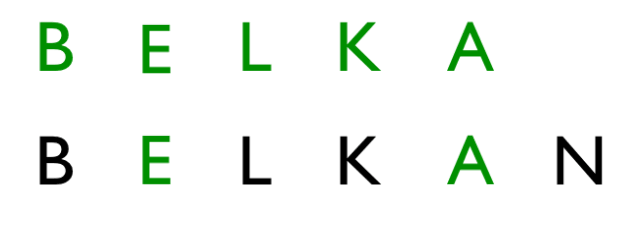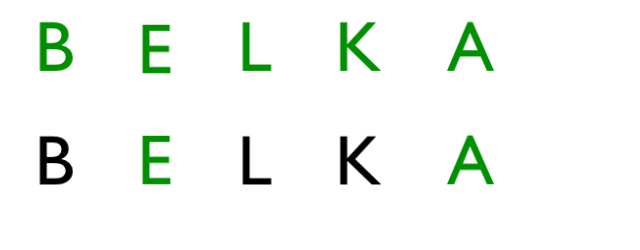
Od razu widać większą liczbę operacji. Prześledźmy to sobie na spokojnie:
Operacja 1: zamiana litery A -> E
Operacja 2: zamiana litery O -> A
Operacja 3: usunięcie litery N
Odległość Levenshteina dla tego przypadku wynosi 3, czy to dużo ?? Na to pytanie ciężko odpowiedzieć, jednak zwróćcie uwagę na inny fakt. Relatywnie tak nieduża wartość wystarczyła, aby zmienić całkowicie słowo. Co niesie bardzo duże zagrożenia przy dopuszczaniu do tak dużych transformacji. Osobiście uważam, że jeśli chcemy dopuszczać tego typu transformacje to wartość na poziomie jednej operacji powinna być wystarczająca.
Dlaczego wspominam o tym algorytmie w kontekście ElasticSearch-a. Otóż możliwe jest wykorzystanie tego algorytmu podczas wyszukiwania dokumentów w indeksie. W większości zapytań mamy możliwość ustawienia parametru fuzziness, który właśnie włącza algorytm z określonymi parametrami. Więcej o samym parametrze i jego ustawieniach można poczytać w dokumentacji.
Co się dzieje z wyszukiwaną frazą
Wpisując frazę w wyszukiwarce jako zwykli użytkownicy nie zastanawiamy się jakie operacje zachodzą po kliknięciu przycisku szukaj. I jest to w pełni naturalne, jednak my jako twórcy takiej wyszukiwarki musimy mieć całkowicie inne spojrzenie. O ile w przypadku tworzenia wyszukiwarki opartej o bazę danych, mamy bardzo małe możliwości. O tyle stosując silniki wyszukiwania pokroju ElasticSearch, możliwości stają się niemal nieograniczone. Żeby je wykorzystać, potrzebna jest wiedza jak wyszukiwarka indeksuje treści oraz co się dzieje z wpisywaną frazą do wyszukania. My zajmiemy się tutaj wyszukiwaną frazą, załóżmy że wygląda ona następująco:

Teraz w zależności od tego jakiego rodzaju wyszukiwania użyjemy, fraza może zostać podzielona lub nie. W przypadku wyszukiwań wprost sytuacja jest bardzo prosta, wpisana fraza będzie wyszukiwana tak jak wpisał ją użytkownik.

Pod spodem w wpisanej frazy ElasticSearch utworzy sobie token akumulator do samochodu toyota i takiego tokena będzie szukał w indeksie odwróconym. Co jak się domyślacie będzie raczej mało efektywne. Choć można znaleźć zastosowanie także dla takiego rodzaju wyszukiwań, chociażby podpowiadanie fraz wpisywanych przez użytkowników. W takim przypadku chcemy dostać całą frazę w postaci tokena, a następnie wyszukać token w indeksie odwróconym, który przechowuje listę wyszukiwanych fraz przez użytkowników.
Wyszukiwania wprost są bardzo przydatne i potrzebne, jednak prawdziwa siła silników wyszukiwania tkwi w wyszukiwaniach pełnotestowych. Wyszukiwania te całkowicie inaczej podchodzą do frazy wpisywanej przez użytkownika.

Tutaj widzimy, że wpisana fraza została rozbita na wiele tokenów i to właśnie każdy z tych tokenów będzie wyszukiwany w indeksie. Pokazany powyżej sposób tokenizacji wyszukiwanej frazy jest bardzo prosty, możemy go udoskonalić na wiele sposobów. Jednym z takich sposobów jest eliminacja słów przystankowych jak do, w, na itd. Słowa te same w sobie nic nie wnoszą do wyszukiwania, w związku z czym możemy je usunąć z procesu tokenizacji stosując filtr typu stop i określając listę słów. Wprowadzając tę zmianę zostaną utworzone następujące tokeny:

Idąc dalej w możliwościach analizy wyszukiwanej frazy i rozbijania jej na tokeny, dochodzimy do momentu w którym pojawiają się synonimy. Proces dodawania synonimów spowoduje, że otrzymamy tokeny z wpisanej frazy oraz dodatkowe będące synonimami znalezionych tokenów.
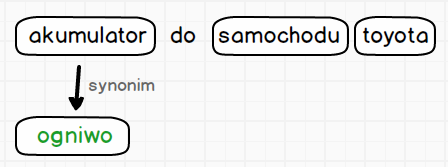
Ostatni mechanizm o jakim warto wspomnieć mówiąc o procesie analizy wyszukiwanej frazy, jest obsługa języków. Proces ten wyeliminuje problemy z wszelkimi odmianami słów. Możemy przecież bez problemu sobie wyobrazić sytuację, w której nazwa produktu to Akumulatory żelowe, czy też Akumulator do samodów marki Toyota. W takich sytuacjach oczywiście mogli byśmy ustawić odległości Levenshteina ustawioną na wartość 1. Niestety nie rozwiąże to problemy, gdy nazwa produktu będzie wyglądała 5 akumulatorów w cenie 4. Konieczne by było zwiększenie wartości odległości edycyjnej na 2 co może nieść nieoczekiwane rezultaty. Dlatego do analizy wyszukiwanej frazy dodaje się analizę językową, która wprowadza modyfikacje w tworzonych tokenach.
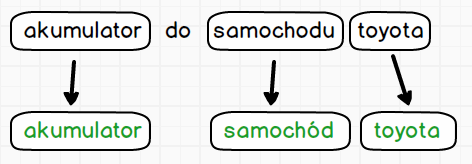
Na pierwszym etapie następuje rozbicie na tokeny, a dopiero na tokenach odbywa się proces sprowadzenia wyrazów do formy podstawowej danego języka. Niestety nasz język nie jest obsługiwany przez ElasticSearch, konieczna jest instalacja specjalnego pluginu. Więcej o tym procesie oraz pluginach opowiem w osobnym wpisie.
Środowisko testowe
Już za chwilę przechodzimy do wyszukiwania, obiecuję ;) Zanim zaczniemy, to chciałbym abyście przygotowali sobie bardzo proste środowisko testowe. Pozwoli wam to na bierząco sprawdzać, czy to co piszę działa, lub czy wasz pomysł na modyfikację przyniesie oczekiwane rezultaty.
Docker
Najprostsza metoda to instalacja Dockera, który jest dostępny na praktycznie każdą platformę. Po instalacji uruchamiacie terminal i wklejacie poniżesz polecenie:
docker run -d -p 9200:9200 -p 5601:5601 nshou/elasticsearch-kibana
Spowoduje ono uruchomienie kontenera z ElasticSearch-em oraz Kibaną. ElasticSearch będzie dostępny pod adresem http://localhost:9200/, a Kibana pod adresem: http://localhost:5601/.
Dane testowe
Czym by było samo środowisko bez danych testowych ? Dlatego przygotowałem dla was dane na których będę pokazywał wam działanie poszczególnych sposobów wyszukiwania.
Zaczynamy od pobrania dwóch plików z indeksem indeks_testowy_produkty.txt oraz indeks_testowy_produkty_producent.txt. Następnie musimy je zaimportować wydając polecenie w terminalu:
curl -XPUT 'http://127.0.0.1:9200/produkty' -H 'Content-Type: application/json' -d @indeks_testowy_produkty.txt
oraz
curl -XPUT 'http://127.0.0.1:9200/produkty_producenci' -H 'Content-Type: application/json' -d @indeks_testowy_produkty_producent.txt
Po imporcie indeksów pobieramy plik z danymi testowymi i wykonujemy analogiczną operację importu.
curl -XPOST 'http://127.0.0.1:9200/_bulk' -H 'Content-Type: application/json' --data-binary @dane_testowe.txt
Po imporcie sprawdzamy czy wszystko się powiodło wchodząc do Kibany znajdującej się pod adresem: http://localhost:5601, a następnie w DevTools wklejamy nasze pierwsze zapytanie do ElasticSearch.
POST /produkty/_search
{
"query": {
"match_all": {}
}
}
Wynik tego zapytania powinien być zbliżony do poniższego:
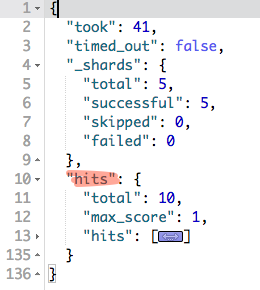
W zwróconym wyniku interesuje nas to co znajduje się pod kluczem hits. Jest to obiekt z trzema parametrami:
total - ilość znalezionych dokumentów,
max_score - maksymalna trafność dla tego wyszukiwania,
hits - lista dokumentów spełniająca warunki zawarte w zapytaniu. Lista jest ukryta, gdyż na ten moment dane z dokumentów są nam niepotrzebne.
Skoro mamy już na czym przeprowadzać testy, to czas na to co tygryski lubią najbardziej, czyli mięcho ;)
Wyszukiwanie wprost
Nazwa może nieco dziwna, jednak chyba oddaje ideę tego rodzaju wyszukiwania. Mianowicie zgrupowane tutaj sposoby przeszukiwania nie analizują wprowadzanych przez nas danych. To co wpiszemy będzie wyszukiwane w indeksie bez żadnych dodatkowych operacji.
Jednak żeby nie było tak łatwo, mamy wyjątek ;) Mianowicie w przypadku przeszukiwania pola typu keyword zawierającego zdefiniowany normalizer zostanie on uwzględniony. W tym momencie jednak nie musicie się tym przejmować.
Term
Zaczniemy od najprostszego sposobu wyszukiwania. Polega ono na przeszukiwaniu określonego pola pod kątem wprowadzonej frazy.
Załóżmy że szukamy iPhone 6S, taki telefon rzeczywiście znajduje się w indeksie. Zobaczmy czy uda nam się go znaleźć ?
GET produkty/_search
{
"query": {
"term": {
"nazwa": "iPhone 6S"
}
}
}
Rezultat może nas zaskoczyć, ElasticSearch nic nie znalazł. Tylko czemu ?? Może wielkość liter ??
GET produkty/_search
{
"query": {
"term": {
"nazwa": "iphone 6s"
}
}
}
Też nie ma :( Sprawdźmy więc czy zostanie znaleziona fraza iphone ??
GET produkty/_search
{
"query": {
"term": {
"nazwa": "iphone"
}
}
}
I w końcu zostało coś znalezione :) Przyjrzyjmy się temu co zostało zwrócone przez wyszukiwarkę:
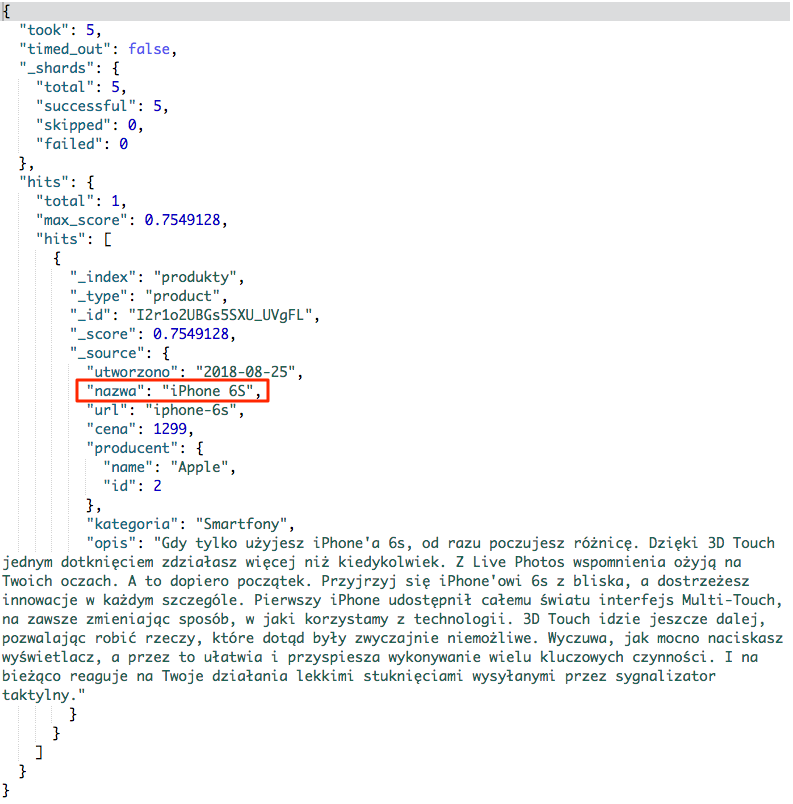
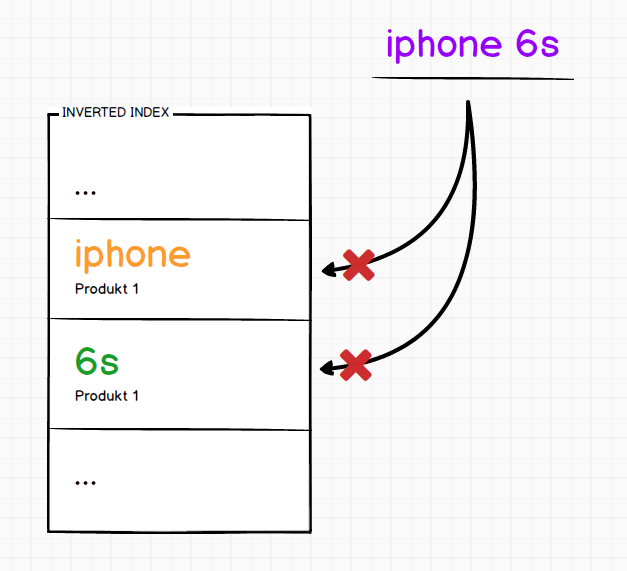
Znaleziono jeden produkt, który nazywa się iPhone 6S. Teraz zapewne zastanawiasz się, czemu produkt nie został znaleziony pomimo wpisania poprawnej frazy w pierwszej próbie. Powód jest prosty, nazwa produktu została podzielona na tokeny, gdyż pole nazwa jest polem typu text. W związku z czym powstały dwa tokeny iphone oraz 6s.
Wyszukiwanie wprost takie jak Term przekazuje do wyszukiwarki wpisywaną przez nas frazę jako jeden token. Tym samym w indeksie nie zostanie znaleziony taki token.
Sytuacja wyglądała by inaczej gdybyśmy przeszukiwali pole typu keyword np. pole url sytuacja wyglądała by inaczej. Bowiem pole typu keyword tworzy tylko jeden token w indeksie niezależnie od zawartości. Tym samym wyszukiwanie tego typu sprawdzi się idealnie dla pól typu keyword.
Ostatnia rzecz o jakiej chcę wspomnieć, to problem z wyszukiwaniem części tokena. Jeśli użytkownik wpisze iphon zamiast iphone, to niestety nic nie zostanie znalezione. Poniżej zapytanie testowe, które nie zwróci żadnego wyniku.
GET produkty/_search
{
"query": {
"term": {
"nazwa": "iphon"
}
}
}
Rozwiązań tego problemu jest wiele, ale najprostsze to zamiana zapytania na Prefix o czym przeczytasz dalej.
Terms
Wyszukiwanie to jest naturalnym rozwinięciem wyszukiwania term. Daje nam możliwość wpisania kilku fraz do wyszukiwania.
GET produkty/_search
{
"query": {
"terms": {
"nazwa": ["iphone", "samsung"]
}
}
}
Zapis nieco się zmienił, po nazwie pola przekazujemy tablicę fraz ["iphone", "samsung"], które chcemy wyszukać. W rezultacie powinniśmy otrzymać 3 produkty.

Range
Nazwa mówi wszystko, więc krótko ;) Przeszukiwanie zakresów to chyba niezbędny sposób w każdej wyszukiwarce. Standardowo mamy możliwość określania zakresów dla liczb oraz co ważniejsze także dla dat.
Zacznijmy od zakresów liczbowych. Mamy 4 parametry, które mówią o sposobie porównania.
gte >= (ang. Greater-than or equal to) gt > (ang. Greater-than) lte <= (ang. Less-than or equal to) lt < (ang. Less-than)
Ustawiając odpowiednio parametry mamy możliwość definiowania zakresów. Załóżmy na początek, że szukamy produktu do 1000 pln. Zapytanie mogło by wyglądać następująco:
GET produkty/_search
{
"query": {
"range" : {
"cena" : {
"lte" : 1000
}
}
}
}
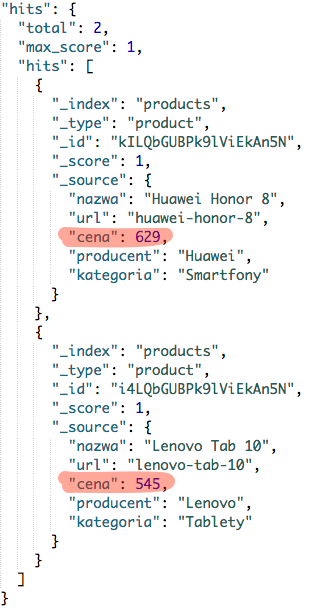
Zapytanie ma słowo kluczowe range mówiące o sposobie wyszukiwania. Następnie zostało określone pole cena, a w nim zdefiniowany zakres. W tym przypadku tylko jeden, cena mniejsza lub równa 1000 "lte" : 1000.
Wynik tego zapytania powinien zwrócić nam dwa produkty:
Teraz dołóżmy drugi parametr definiując jawnie cały zakres kwotowy.
GET produkty/_search
{
"query": {
"range" : {
"cena" : {
"gte" : 1000,
"lte" : 1500
}
}
}
}
W zapytaniu dodano dodatkowy zapis w cenie, mówiący: cena większa lub równa 100 czyli "gte" : 1000. Skoro już potrafimy zdefiniować zakresy i znamy strukturę, to nie będę was zanudzał takimi samymi przykładami z datami. Jeśli macie jakieś wątpliwości to w dokumentacji znajdziecie wszystkie szczegóły.
Prefix
Ten rodzaj wyszukiwania rozwiązuje problem z wyszukiwaniem tokenów, których początek zgadza się z wpisaną frazą. Daje nam to możliwość napisania w prosty sposób autocompletera, podpowiadającego nazwy naszych produktów w sklepie.
Przy opisywaniu wyszukiwania typu Term, podałem przykład wpisania frazy iphon, który nie zwracał nam żadnego produktu.
GET produkty/_search
{
"query": {
"term": {
"nazwa": "iphon"
}
}
}
Problemem jest fakt, że token iphon nie istnieje. Jednak w indeksie znajduje się token iphone, którego początek zgadza się z wpisanym tokenem.
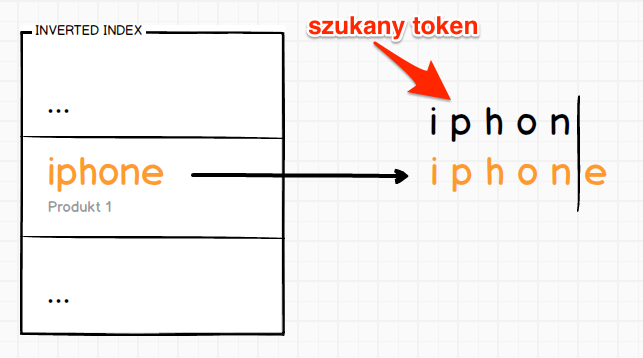
Właśnie w ten sposób działa wyszukiwanie typu Prefix, sprawdza czy początek któregoś tokenu w indeksie zgadza się z wyszukiwanym tokenem. Niestety nie rozwiąże ono problemu, wpisania tylko fragmentu znajdującego się w środku lub na końcu tokenu. Tego typu problemy, możemy rozwiązać wyszukiwaniem typu Wildcard lub Regexp.
Wildcard
Wildcard to bardzo prosty sposób wyszukiwania. Umożliwia zastąpienie pojedynczego znaku, znakiem zapytania ?. Co powoduje, że może tam wystąpić dowolny znak.
Załóżmy, że chcemy znaleźć wszystkie iPady oraz iPody w sklepie. W takim wypadku nasze zapytanie Wildcard powinno wyglądać następująco ip?d.
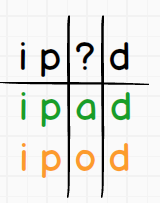
Jak widać powyżej znak ? zastępuje nam jeden znak, w związku z czym, do tak zdefiniowanego wzorca będzie pasował token ipad oraz ipod. A co jeśli chceli byśmy dopasować tokeny ipad, ipod oraz iphone ? Czy trzeba postawić kilka znaków zapytania ? Jak ma się do tego różna długość tokenów ? Otóż dla takich przypadków, został dodany znak specjalny *. Reprezentuje on dowolny znak występujący zero lub nieokreśloną ilość razy.
W związku z tym, że w wymienionych tokenach tylko pierwsze dwa znaki się zgadzają, to wzorzec będzie wyglądał następująco: ip*. Pozostałe znaki zostaną zastąpione przez *, spróbujmy to sobie zwizualizować.
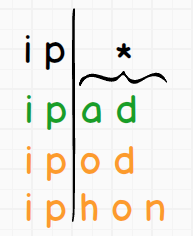
Taki zapis oznacza, że jeśli mielibyśmy w indeksie token ip to on także został by uwzględniony w wynikach. Ale koniec teoretyzowania, czas na działanie ;) Zacznijmy od znaku zapytania, ale żeby dostarczyć sobie odrobinę rozrywki to co zwróci zapis ?? przy zapytaniu typu Wildcard ?
GET produkty/_search
{
"query": {
"wildcard": {
"nazwa": "??"
}
}
}
Wieżę że odpowiedziałeś poprawnie, i widzisz właśnie wszystkie produkty, które mają tokeny składające się z dwóch dowolnych znaków. W przypadku danych testowych będzie ta lista wyglądała następująco.
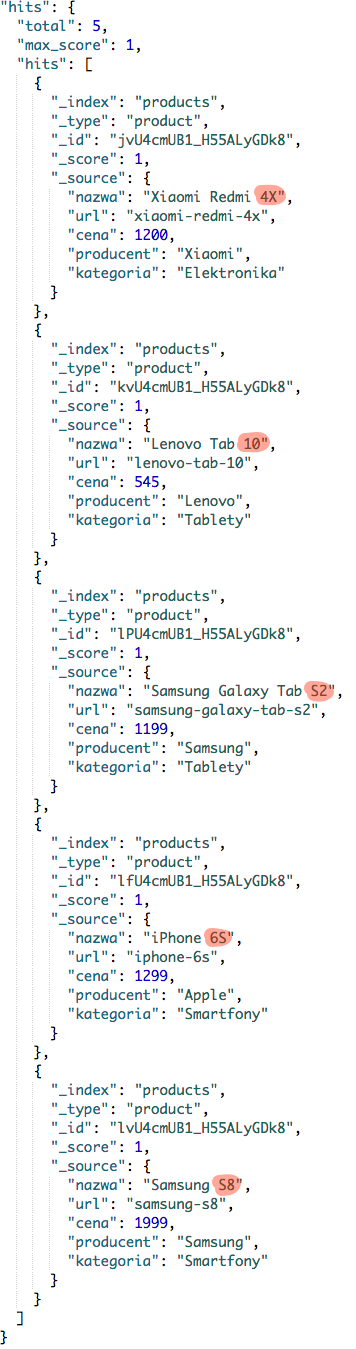
Jak widzisz pozwoliłem sobie zaznaczyć tokeny, które zostały wyszukane. Zobaczmy czy gwiazdka * zadziała zgodnie z wcześniejszym opisem, ale tu już nie będziemy kombinować i użyje wcześniejszego przykładu, czyli ip*.
GET produkty/_search
{
"query": {
"wildcard": {
"nazwa": "ip*"
}
}
}
I nie ma tutaj żadnego zaskoczenia, zwrócone produkty to dwa iPady oraz jeden iPhone 6S.
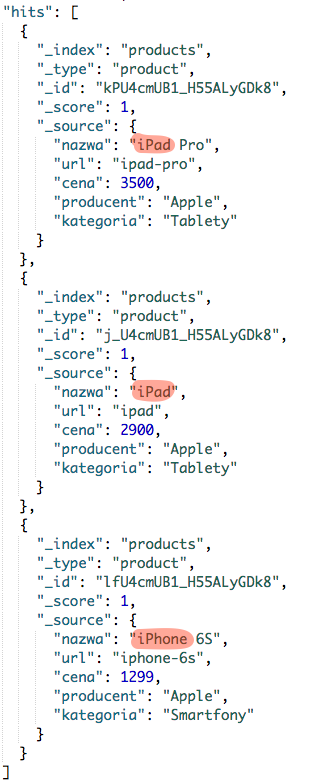
Oczywiście jest dopuszczalne dowolne mieszanie obu znaków specjalnych. Zachęcam do zabawy i eksperymentów, jednak musicie pamiętać o dość ważnej rzeczy. Mianowicie wydajność tego typu zapytań nie jest zbyt wysoka, a gdy umieścicie któryś ze znaków specjalnych na początku, to wydajność leży i kwiczy ;)
Regexp
Wyrażenia regularne przez wszystkich tak bardzo kochane, że aż strach je opisywać. Wpis ten nie ma na celu nauki wyrażeń regularnych, w związku z czym pozostaniemy przy jednym przykładzie mającym na celu pokazanie struktury zapytania.
Zapytanie jest odpowiednikiem zapytania Wildcard ip* i zapisane jako wyrażenie regularne, będzie wyglądało następująco: ip.*
GET produkty/_search
{
"query": {
"regexp": {
"nazwa": "ip.*"
}
}
}
Więcej o możliwościach tego typu zapytań możecie poczytać w dokumentacji.
Fuzzy
Mogę od razu Ci powiedzieć, że pokochasz ten sposób wyszukiwania. Rozwiązuje problem z literówkami, brakującymi literami na końcu oraz początku tokena. A później je znienawidzisz, żeby na samym końcu używać świadomie i z rozwagą.
Wyszukiwanie to bazuje na odległości Levenshteina, które opisałem w części teoretycznej tego wpisu. Jeśli jednak nie chcesz zagłębiać się w teorię, to niech na tę chwilę, wystarczy Ci wiedza, że pozwala na eliminowanie literówek. Ale jak tylko skończysz czytać tę część, to proszę przeczytaj część teoretyczną. Bez podstaw teoretycznych, możesz mieć więcej problemów niż pożytku z tego typu wyszukiwania.
Zacznijmy od prostego błędu token wpisany przez użytkownika to iphon. Już rozwiązywaliśmy ten problem stosując wyszukiwanie typu Prefix.
GET produkty/_search
{
"query": {
"fuzzy": {
"nazwa": "iphon"
}
}
}
Wygląda praktycznie identycznie, jednak żadne z wyszukiwań nie rozwiązuje problemu literówki. Na potrzeby testów załóżmy, że użytkownik wpisał iphne
GET produkty/_search
{
"query": {
"fuzzy": {
"nazwa": "iphne"
}
}
}
Pomimo błędu produkt został znaleziony, i takiego czegoś byśmy oczekiwali od dobrej wyszukiwarki w sklepie internetowym. Ile razy się zdarza, że pisząc szybko na klawiaturze zjemy jakąś literkę, albo zamienimy ją z inną. W takich przypadkach, albo wyszukiwarka nie zwraca nam żadnych wyników, albo ma zaimplementowane podpowiedzi jak np. Allegro.
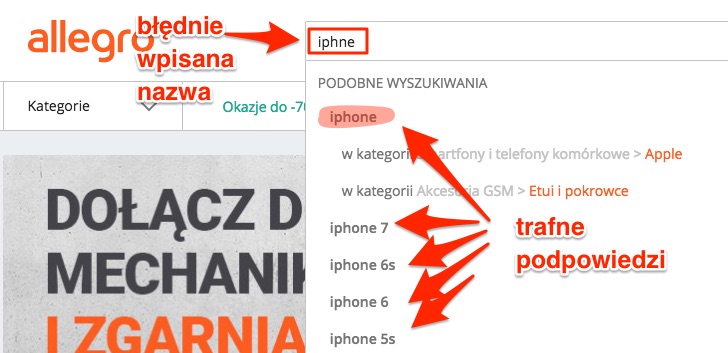
Oczywiście w przypadku wyszukiwania frazy z błędem, wyszukiwarka koryguje sobie ten błąd.
Wyszukiwanie tego typu dostarcza nam możliwość ustawienia kilku parametrów przekładających się na dopuszczalną ilość popełnianych błędów.
fuzziness - maksymalna dopuszczalna ilość operacji jakie mogą zostać wykonane, aby zamienić jeden ciąg znaków na drugi (domyślnie: AUTO)
prefix_length - ile początkowych znaków ma nie podlegać zmianie. Ustawienie to ogranicza ilość wykonywanych operacji na ciągu co pozytywnie wpływa na wydajność. (domyślnie 0)
max_expansions - opcja ta ustawia maksymalną liczę wariantów jakie może zostać wyprodukowana przez fuzziness. Ustawienie opcji fuzziness na wysoką wartość np. 3, 4, 5, 6 może spowodować wyprodukowanie setek lub tysięcy wariantów. Ta opcja ograniczy ich liczbę do określonej wartości. (domyślnie: 50)
transpositions - czy jest dopuszczalna zamiana znaków (ab -> ba) (domyślnie: false)
Wyszukiwanie pełnotekstowe
Wyszukiwanie pełnotekstowe od wyszukiwania prostego, różni się sposobem przetwarzania wyszukiwanej frazy. Poprzednio ElasticSearch nie przeprowadzał żadnych operacji na wyszukiwanej frazie co niosło pewne konsekwencje. W przypadku wyszukiwania pełnotekstowego wyszukiwana fraza, jest poddawana analizie. Analiza może być wykonana z wykorzystaniem analizatora pola, domyślnego analizatora wyszukiwania lub zdefiniowanego w zapytaniu.
Match
Najprostszy rodzaj wyszukiwania pełnotekstowego, jednak nie oznacza to że najgorszy. Zacznijmy od zapytania, które sprawiało tyle problemów przy wyszukiwaniu prostym iPhone 6S.
GET produkty/_search
{
"query": {
"match": {
"nazwa": "iPhone 6S"
}
}
}
Rezultat, produkt został od razu znaleziony.
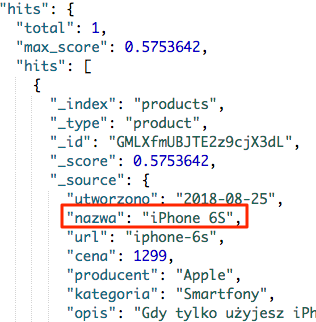
Tylko dlaczego tak się stało ? Wszytko wyjaśni analizer, którego działanie możemy przetestować poprzez odpowiednie zapytanie. My się posłużymy najprostszym, gdyż w tym momencie nie mamy ustawionego żadnego analizera.
GET produkty/_analyze
{
"text": ["iPhone 6S"]
}
W rezultacie otrzymamy rozbicie na dwa tokeny iphone i 6s. Dzięki temu zabiegowi bez problemu został znaleziony nasz produkt. Gdyż w indeksie znajduje się token iphone.

Skoro widzimy, że ten rodzaj wyszukiwania bardzo fajnie znajduje nam produkty poprzez rozbijanie wpisywanych fraz na tokeny i wyszukiwanie ich w indeksie. To jak zachowa się nasza wyszukiwarka przy frazie iPad Pro i czy wyniki będą zgodne z oczekiwaniami.
Zapytanie identyczne jak w poprzednim przypadku, zmieniliśmy tylko frazę.
GET produkty/_search
{
"query": {
"match": {
"nazwa": "iPad Pro"
}
}
}
Spójrzmy na wynik i zastanówmy się, czy jest dobrze :)
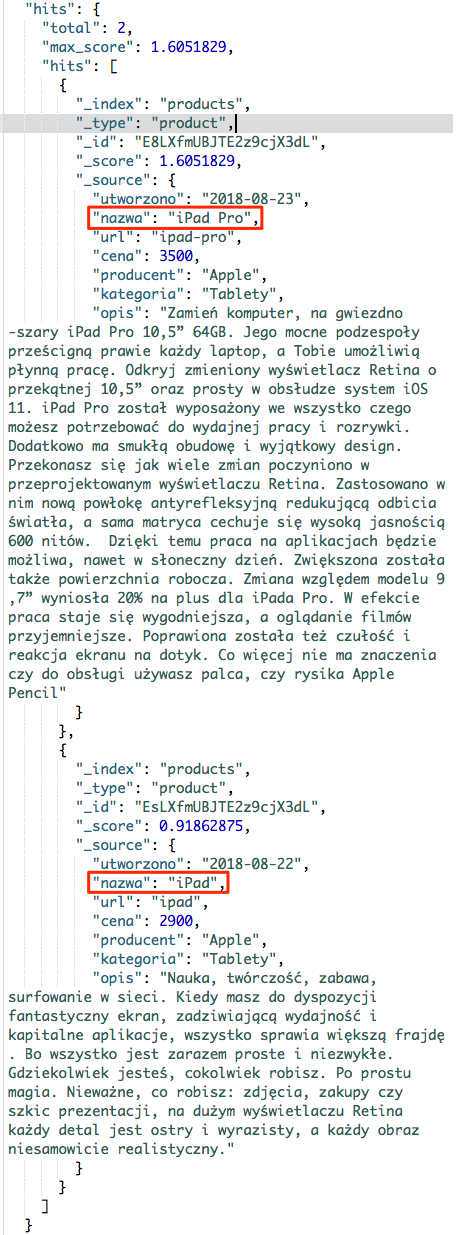
Mamy dwa produkty: iPad Pro oraz iPad, gdzie pierwszym jest ten którego szukamy. Tylko dlaczego został znaleziony iPad, przecież nie jest w wersji Pro, której szukaliśmy. Odpowiedź jest prosta i zapewne już znasz odpowiedź ;) Otóż po rozbiciu frazy przez analizer na tokeny, otrzymamy dwa tokeny: ipad i pro. Wyszukiwarka mając nasze zapytanie stwierdzi, że ma znaleźć token ipad LUB pro. Co możemy zapisać:
GET produkty/_search
{
"query": {
"match": {
"nazwa": {
"query": "iPad Pro",
"operator": "or"
}
}
}
}
Pole nazwa już nie zawiera jedynie tekstu, a teraz jest obiektem. W obiekcie tym fraza przez nas szukana iPad Pro została przypisana do klucza query. Druga modyfikacja jest istotniejsza, dodany został parametr operator, który może przyjąć dwie wartości: or lub and.
Teraz wiedząc już jak działa parametr operator, możemy śmiało zmodyfikować nasze zapytanie następująco:
GET produkty/_search
{
"query": {
"match": {
"nazwa": {
"query": "iPad Pro",
"operator": "and"
}
}
}
}
Wprowadzona modyfikacja spowoduje, że znaleziony zostanie tylko jeden produkt. Czy jest to lepsze rozwiązanie ? Ciężko powiedzieć, wszystko zależy jakie wymagania stawiasz przed wyszukiwarką.
Ten sam efekt możesz uzyskać w nieco inny sposób, a mowa tu o parametrze minimum_should_match. Parametr ten określa ile tokenów z naszej wyszukiwanej frazy musi zostać znalezionych, domyślnie ustawiona jest wartość 1. Więc poniżesz zapytanie niczym nie będzie się różniło od tego w którym mamy zapis "nazwa": "iPad Pro"
GET produkty/_search
{
"query": {
"match": {
"nazwa": {
"query": "iPad Pro",
"minimum_should_match": 1
}
}
}
}
Ustawiając parametr minimum_should_match na wartość 2 wymusimy znalezienie tylko takich produktów, które zawierają minimum dwa tokeny.
GET produkty/_search
{
"query": {
"match": {
"nazwa": {
"query": "iPad Pro",
"minimum_should_match": 2
}
}
}
}
Tym samym zostanie znaleziony tylko jeden produkt. Jednak należy uważać z tym parametrem, gdyż ustawienie wartości większej niż ilość tokenów we frazie spowoduje nie znalezienie żadnego produktu.
GET produkty/_search
{
"query": {
"match": {
"nazwa": {
"query": "iPad Pro",
"minimum_should_match": 3
}
}
}
}
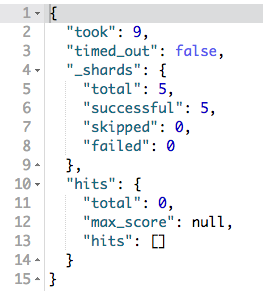
I dla takiego zapytania nie znaleziono żadnego produktu.
Multi Match
Ten sposób wyszukiwania jest rozwinięciem wyszukiwania typu Match. Pozwala na jednoczesne przeszukiwanie wielu pól.
GET produkty/_search
{
"query": {
"multi_match": {
"fields": [
"nazwa",
"opis"
],
"query": "smartfon iPhone 6S"
}
}
}
Wynikiem działania takiego zapytania będzie poniższa lista produktów.
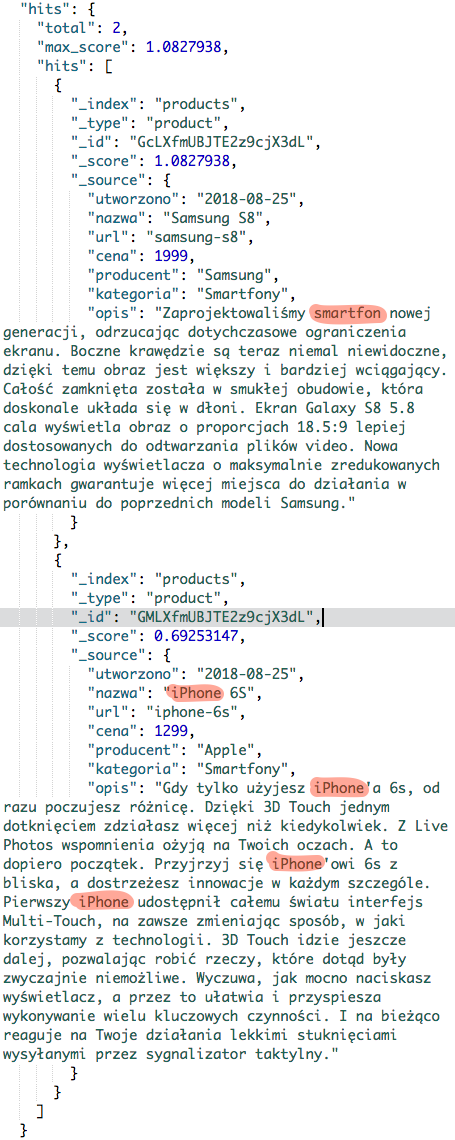
Powyżej zaznaczyłem tokeny, które zostały znalezione w poszczególnych produktach. Jednak możemy mieć odczucie, że w wynikach jest pewien brak naturalności. Wynika to z wyliczanej wartości _score dla każdego produktu. Nie będziemy teraz dokładnie w to wnikali, tym zajmiemy się w osobnym wpisie. Na ten moment niech wystarczy nam wiedza, że mamy możliwość wpłynąć na te wyniki.
Na potrzeby naszego przykładu założymy, że pole tytułu jest dla nas bardziej priorytetowe niż pole opis. Co w większości wypadków będzie się pokrywało z rzeczywistością. Zobaczmy jak takie zapytanie będzie wyglądało:
GET produkty/_search
{
"query": {
"multi_match": {
"query": "smartfon iPhone 6S",
"fields": [
"nazwa^2",
"opis"
]
}
}
}
Przy polu nazwa został dodany zapis ^2, który mówi, że to pole jest dwa razy ważniejsze niż inne. W ten prosty sposób jesteśmy w stanie ustawić poziomy ważności poszczególnych pól w wyszukiwaniach typu Multi Match.
Niestety wyszukiwanie to ma pewne ograniczenie. Mianowicie ustawienie wyszukiwania po polu typu nested nie przyniesie oczekiwanych rezultatów. Spójrzmy na chwilę na indeks, w którym pole producent jest typu nested.
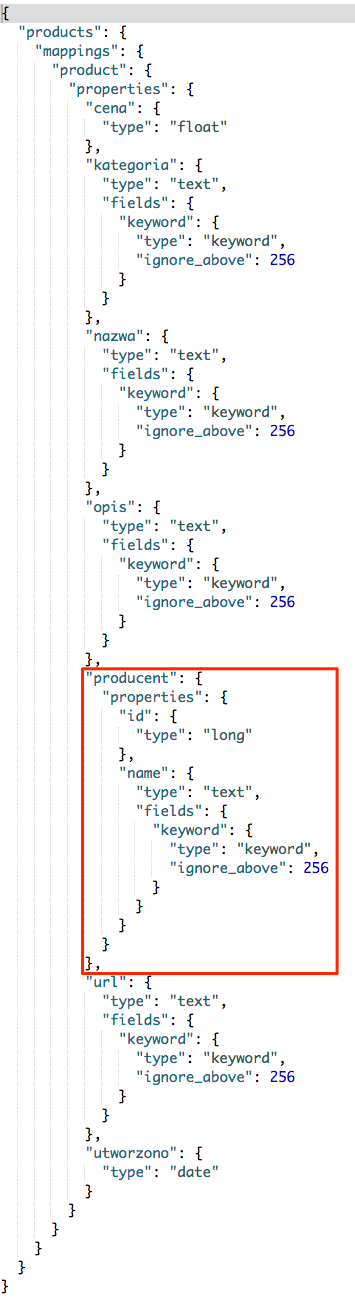
Zaś sama definicja tego pola wygląda następująco:
"producent": {
"type": "nested",
"properties": {
"id": {
"type": "integer",
"store": true,
"index": true
},
"name": {
"type": "text"
}
}
}
Wiedząc jak zbudowany mamy indeks, możemy stworzyć zapytanie szukające produktów po nazwie producenta. Żeby uniknąć wątpliwości będziemy szukali tylko po tym jednym polu. A nasze zapytanie będzie wyglądało następująco:
GET produkty/_search
{
"query": {
"multi_match": {
"query": "Apple",
"fields": [
"producent.nazwa"
]
}
}
}
I niestety pomimo tego, że wydaje nam się, że zostaną znalezione produkty to tak się nie stanie. Wynika to z sposobu indeksowania dokumentów, w przypadku typu nested jest od indeksowany osobno w ukrytych dokumentach. Dokumentów tych nie możemy przeszukiwać bezpośrednio, ale istnieją dwa sposoby na rozwiązanie tego problemu. Pierwszy to dodanie w definicji pola producent parametru include_in_parent ustawionego na true.
"producent": {
"type": "nested",
"include_in_parent": true,
"properties": {
"id": {
"type": "integer",
"store": true,
"index": true
},
"name": {
"type": "text"
}
}
}
Ta modyfikacja niestety wymaga od nas utworzenia indeksu na nowo i zaindeksowaniu wszystkich produktów. Kiedy już to zrobimy to nasze zapytanie powinno zacząć działać zgodnie z oczekiwaniami.
Jako że przygotowałem dane testowe i nie chciałem żebyście musieli bawić się w modyfikowanie indeksu (choć zachęcam do eksperymentów). To do testów mamy drugi indeks zawierający parametr include_in_parent. Indeks nazywa się produkty_producenci i możemy na nim przetestować zapytanie:
GET produkty_producenci/_search
{
"query": {
"multi_match": {
"query": "Apple",
"fields": [
"producent.nazwa"
]
}
}
}
Drugi sposób na rozwiązanie tego problemu to osobny sposób przeszukiwania. Zapytanie będzie wyglądało następująco:
GET produkty/_search
{
"query": {
"nested": {
"path": "producent",
"query": {
"multi_match": {
"query": "Apple",
"fields": [
"producent.name"
]
}
}
}
}
}
Nastąpiła jedna zmiana, zapytanie zostało opakowane w strukturę nested. Struktura jest bardzo prosta, sprowadza się do parametru path wskazującego pole typu nested. Zaś w parametrze query umieszczamy zapytanie czy to Multi Match, czy też inne.
Match Phrase
W związku z faktem rozbijania wyszukiwanej frazy na tokeny w zapytaniach pełnotekstowych. Powstał taki rodzaj wyszukiwania, który pozwalał by na wyszukiwanie całych fraz przy zachowaniu plusów wyszukiwania pełnotestowego. Tym mechanizmem jest właśnie wyszukiwanie typu Match Phrase.
Krótko mówiąc, wpisując frazę Lenovo tab będzie wyszukiwana cała fraza. Tym samym poniżesz zapytanie zwróci nam tylko jeden produkt.
GET produkty/_search
{
"query": {
"match_phrase": {
"nazwa": "Lenovo tab"
}
}
}
Fajnie, ale mogliśmy to samo osiągnąć poprzez dodanie parametru operator w wyszukiwaniu typu Match. Gdzie korzyści ?? Otóż korzyści zobaczymy, gdy dodamy parametr slop (domyślnie ustawiona jest wartość 0). Parametr ten pozwala określić ile możliwych jest pominięć lub przestawień słów. Ustawiając wartość 1 w naszym zapytaniu dopuszczamy wyniki typu Lenovo Yoga Tab, Tab Lenovo itp. itd.
Zapytanie z uwzględnieniem parametru slop będzie wyglądało następująco:
GET produkty/_search
{
"query": {
"match_phrase": {
"nazwa": {
"query": "Lenovo tab",
"slop": 1
}
}
}
}
A w wynikach zobaczymy już dwa produkty.

Match Phrase Prefix
Ten rodzaj wyszukiwania jest niejako wariacją wyszukiwania Match Phrase oraz Prefix. W działaniu niczym się nie różni od wyszukiwania Match Phrase z tą różnicą, że ostatni token jest traktowany jako prefix. Więc wpisanie frazy Lenovo t, spowoduje że zostaną dopasowane takie wariacje jak: Lenovo tablet, Lenovo tab, Lenovo telefon… Na szczęście istnieje parametr max_expansions, który ogranicza generowanie takich wariantów do domyślnej wartości 50. Oczywiście możemy to zmienić na dowolną liczbę.
Zapytanie wygląda bardzo podobnie do pozostałych:
GET produkty/_search
{
"query": {
"match_phrase_prefix": {
"nazwa": {
"query": "Lenovo t"
}
}
}
}
Zostanie nam zwrócony tylko jeden produkt, co nie jest dla nas zaskoczeniem. Mamy tylko jeden produkt, gdzie wyszukiwana fraza zgadza się z nazwą, a utworzony token t jest prefiksem tokena tab.
Podejście to świetnie się sprawdzi w prostych autocompleter-ach. Zwłaszcza, gdy dodamy do zapytania slop jak poniżej.
GET produkty/_search
{
"query": {
"match_phrase_prefix": {
"nazwa": {
"query": "Lenovo t",
"slop": 1
}
}
}
}
Takie zapytanie zwróci dwa produkty, co jest świetnym prognostykiem dla mechanizmu auto uzupełniania. Użytkownik wpisując np. lenovo t dostanie podpowiedzi produktu Lenovo Tab 10 oraz Lenovo Yoga Tab 3.
Query String
Czasem zaawansowane wyszukiwarki różnych serwisów udostępniają proste mechanizmy określające warunki wyszukiwania. Z reguły jest to możliwość ujęcie jakiegoś fragmentu wyszukiwanej frazy w cudzysłów przez co mówimy, że szukamy dokładnie takiej frazy. Zdarza się także, że możemy dodawać takie słowa kluczowe jak AND lub OR oraz nawiasy grupujące wyrażenia. Określanie wyszukiwania po określonych polach, zastępowanie znaków przez znak * oraz wiele innych ustawień znanych tylko zaawansowanym użytkownikom danej wyszukiwarki.
ElasticSearch udostępnia ten mechanizm właśnie poprzez zapytania Query String. Jednak niech was nie kusi żeby ten mechanizm wystawiać użytkownikom końcowym. Po pierwsze nie wy kontrolujecie działanie tego mechanizmu, i na pytanie czy może to działać inaczej odpowiedź z reguły będzie negatywna. Po drugie, albo będziecie zmuszeni przygotować jakąś instrukcję użytkownikom, albo ich nauczyć tak zaawansowanej wyszukiwarki używać. Jeśli żaden z argumentów was nie przekonał to ostatni, w razie błędu rzucany jest wyjątek :(
Żeby nie mówić tylko, fajne rozwiązanie, ale nie używajcie to jeśli macie wewnętrzne systemy to warto wystawić coś takiego użytkownikom. Zobaczcie jak fajnie pisze się zapytania:
GET produkty/_search
{
"query": {
"query_string": {
"query": "+samsung -s8"
}
}
}
Zapytanie możemy przetłumaczyć następująco: pokaż mi wszystko co ma token samsung, ale wyeliminuj produkty z tokenem s8. Na koniec jeszcze jedno proste zapytanie, które szuka telefonu Samsung s8 lub iPhona
GET produkty/_search
{
"query": {
"query_string": {
"query": "+(samsung s8) OR iphone"
}
}
}
Więcej przykładów znajdziecie jak zawsze w dokumentacji.
Simple Query String
Spodobała Ci się opcja zaawansowanego przeszukiwania z Query String, ale masz obawy o to co będą wpisywali użytkownicy i nieszczęsne wyjątki rzucane przez niepoprawną składnię. To jest rozwiązanie twoich problemów ;)
Niestety minus jest taki, że liczba możliwości została zawężona. Jednak dla przeciętnego śmiertelnika i tak jest imponująca, a dodatkowo możliwe jest nałożenie własnych ograniczeń.
Więcej znajdziecie w dokumentacji.
Wyszukiwanie złożone
Pod tą piękną nazwą ukryłem tylko jeden rodzaj zapytań, choć kwalifikuje się tu także wiele innych, jak wyszukiwanie ze względu na geolokalizację czy pisanie własnych skryptów. O bardziej wyspecjalizowanych rodzajach wyszukiwania porozmawiamy innym razem ;)
Bool
Ten rodzaj wyszukiwania sam w sobie niczego nie wyszukuje, ale dostarcza nam logikę umożliwiającą łączenie różnego rodzaju wyszukiwań.
Zacznijmy od poznania struktury tego typu wyszukiwania i jak możemy łączyć poszczególne elementy.
POST produkty/_search
{
"query": {
"bool" : {
"must" : {},
"filter": {},
"must_not" : {},
"should" : {}
}
}
}
Logika zapytania udostępnia nam następujące klucze, które mają określony wpływ na zapytania znajdujące się w danym kluczu.
must
Zwraca dokumenty czyli w naszym przypadku produkty, które spełniły warunki zawarte pod tym kluczem.
POST produkty/_search
{
"query": {
"bool": {
"must": {
"match": {
"kategoria": "tablety"
}
}
}
}
}
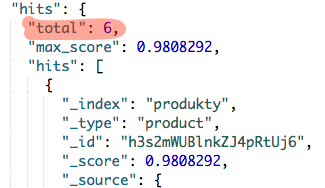
Mamy tutaj bardzo proste wyszukiwanie produktów, które należą do kategorii “Tablety”. Wynik wyszukiwania to 6 produktów:
Teraz dodajmy jeszcze jeden warunek, który zawęzi nam tę listę tylko do produktów z przedziału od 1000 pln do 1500 pln.
POST produkty/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"kategoria": "tablety"
}
},
{
"range": {
"cena": {
"gte": 1000,
"lte": 1500
}
}
}
]
}
}
}
Przyjrzyjmy się przez chwilę jak zmieniła się struktura zapytania. Otóż must jako parametru nie przyjmuje już obiektu, ale tablicę obiektów co pozwala nam w prosty sposób dodać nieskończoną liczbę warunków.
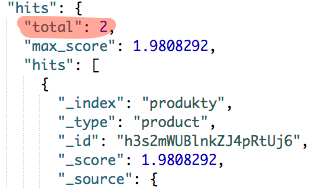
Rezultat powyższego zapytania powinien zwrócić nam 2 produkty.
filter
Filtr działa identycznie jak must z tą różnicą, że nie wpływa na _score. Więc jeśli zastosujemy jedynie ten klucz to _score będzie miał wartość 0. Zobaczmy czy teoria pokrywa się z praktyką i przeniesiemy zapytanie z must do filter.
POST produkty/_search
{
"query": {
"bool": {
"filter": {
"match": {
"kategoria": "tablety"
}
}
}
}
}
Wynik takiego zapytania pozostanie bez zmian i także zostanie zwróconych 6 produktów. Jednak tym razem interesuje nas wartość _score, która dla każdego produktu wynosi zero.
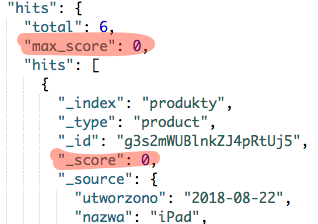
Dodatkowo możemy podejrzeć wartość max_score mówiąca o maksymalnej wartości _score w liście produktów. I tutaj także mamy wartość zero co świadczy o tym, że żaden z dokumentów nie ma większej wartości.
must_not
Ten klucz służy do wykluczania dokumentów (produktów) ze zbioru. Zostańmy przy przeszukiwaniu kategorii tabletów, ale nie interesuje nas producent Apple.
POST produkty/_search
{
"query": {
"bool": {
"must": {
"match": {
"kategoria": "tablety"
}
},
"must_not": {
"nested": {
"path": "producent",
"query": {
"match": {
"producent.name": "Apple"
}
}
}
}
}
}
}
Lub nieco prościej, gdy wykorzystamy drugi indeks mający włączone obiekty typu nested do indeksu.
POST produkty_producent/_search
{
"query": {
"bool": {
"must": {
"match": {
"kategoria": "tablety"
}
},
"must_not": {
"match": {
"producent.name": "Apple"
}
}
}
}
}
Niezależnie od wybranej opcji otrzymamy 4 produkty w wynikach wyszukiwania. Czyli dwa produkty mniej niż w przypadku wyszukiwania w samej kategorii tablety.
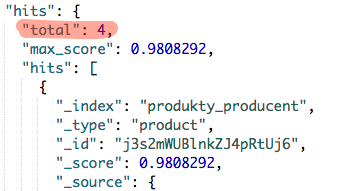
should
Ostatni klucz wymusza spełnienie tylko jednego z wielu warunków. Upraszczając możemy powiedzieć, że interesują nas produkty producenta Apple lub Samsunga.
POST produkty_producent/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"producent.name": "Apple"
}
},
{
"match": {
"producent.name": "Samsung"
}
}
]
}
}
}
Użyliśmy zapisu tablicowego, dzięki czemu mogliśmy zawszeć wiele warunków. Teraz wystarczy że dokument (produkt) spełni tylko jeden z nich, a zostanie zwrócony w wynikach wyszukiwania. Takich produktów powinniśmy otrzymać 5.
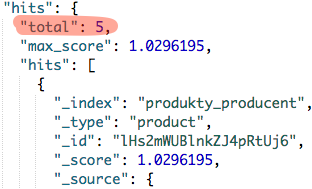
must + should
Znamy już wszystkie konstrukcje jakie możemy używać w wyszukiwaniach typu Bool. Podczas jednoczesnego używania konstrukcji must oraz should w zapytaniu możemy być nieco zdziwieni wynikiem jaki otrzymamy.
Zacznijmy od przykładu, a później omówię co tam się wydarzyło.
POST produkty_producent/_search
{
"query": {
"bool": {
"must": {
"match": {
"kategoria": "tablety"
}
},
"should": {
"match": {
"producent.name": "Apple"
}
}
}
}
}
Mamy tutaj dwie konstrukcje must, która wyszukuje produkty z kategorii tablety. Druga konstrukcja should, powinna nam ograniczyć listę produktów, tylko do produktów producenta Apple. Jednak tak się nie stanie, i gdy zostanie zwrócony nam wynik zapytania, to otrzymamy 6 produktów.
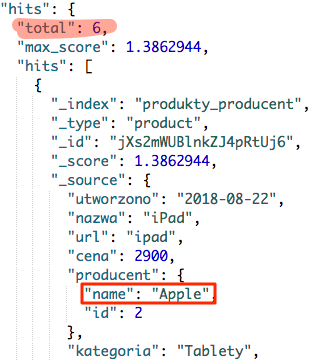
Zwróć jednak uwagę jakiego producenta produkty są pierwsze, czy aby nie jest to Apple ?? Dla porównania wynik zapytania wykorzystującego tylko konstrukcję must.
Zapytanie
POST produkty_producent/_search
{
"query": {
"bool": {
"must": {
"match": {
"kategoria": "tablety"
}
}
}
}
}
Wynik
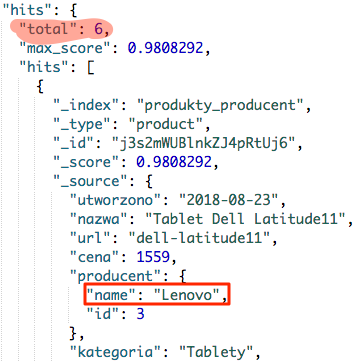
Od razu widać, że kolejność uległa zmianie. I właśnie do tego celu wykorzystuj łączenie obu tych konstrukcji, nie próbuj stosować tego typu ograniczenia licząc, że zostaną wyszukane produkty spełniające oba parametry. Do tego celu wykorzystuj konstrukcję must lub filter w zależności, czy ma ona wpływać na _score danego produktu.
Zapytanie ograniczające po kategorii i producencie powinno wyglądać następująco.
POST produkty_producent/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"kategoria": "tablety"
}
},
{
"match": {
"producent.name": "Apple"
}
}
]
}
}
}
Zagłębianie zapytań
Ostatnim aspektem o jakim chcę Ci powiedzieć w kontekście wyszukiwań typu Bool, jest możliwość ich dowolnego zagłębiania.
POST produkty_producent/_search
{
"query": {
"bool": {
"must": {
"bool": {
"must": {
"match": {
"kategoria": "tablety"
}
}
}
}
}
}
}
Powyższy przykład jest dość abstrakcyjny, jednak wystarczająco dobrze oddaje sens działania zagłębień. Każda konstrukcja must, should, filter oraz not_must pozwala na dodanie sposobu wyszukiwania innego wyszukiwania typy Bool. Dzięki temu tworzymy drzewo zapytań, które możemy zbudować w dowolny sposób.
Podsumowanie
Omówione tutaj sposoby wyszukiwania to takie z którymi możecie spotkać się najczęściej. Odpowiednie ich zrozumienie jest konieczne do pójścia głębiej i poznawania bardziej zaawansowanych mechanizmów Elastic Search-a.
Wiem że wpis nie wyczerpał tematu i pozostało wiele sposobów wyszukiwania o których warto było by wspomnieć. Niemniej mam nadzieję, że te które zostały tutaj omówione byliście w stanie zrozumieć i przetestować.
Jeśli macie jakieś wątpliwości, problemy lub zauważyliście błąd to śmiało piszcie w komentarzach pod wpisem :) Postaram się wszystko wyjaśnić, a ewentualne błędy poprawić.