
Wprowadzenie do agregacji danych w ElasticSearch

Oprócz zaawansowanego wyszukiwanie pełnoteksowego w ElasticSearch mamy także możliwość grupowania i zliczania dokumentów.
Co ważne operacje zliczania mogą być wykonywane równolegle z operacjami przeszukiwania indeksu. Dzięki czemu możemy zmniejszyć ilość zapytań do wyszukiwarki.
Projekt indeksu
Jeśli myślimy na poważnie o wykorzystaniu możliwości agregowania danych przez ElasticSearch to powinniśmy już na poziomie projektowania indeksu wziąć pod uwagę po jakich polach będziemy przeprowadzać operacje agregacji. Wiąże się to z ograniczeniami ElasticSearch-a, który nie przeprowadzi agregacji po pewnych typach pól. Chyba że go o tym wcześniej poinformujemy w schemacie indeksu ;)
Stwórzmy prosty schemat dla sklepu internetowego. W naszym schemacie będziemy mieli następujące pola:
nazwa produktu - pole po którym będziemy chcieli przeszukiwać oraz jego zawartość będzie przechowywana w indeksie,
producent - nazwa producenta, po której będziemy szukać produktów oraz którą będziemy przechowywać w indeksie,
cena - cena produktu, która będzie przechowywana w indeksie oraz po której musi dać się przeszukiwać,
opis - opis produktu, jako że opisu produktu w naszym przypadku niem potrzeby przechowywać w indeksie więc jedynie zaindeksujemy opis,
url - adres url do produktu, nie będziemy przeszukiwać tego pola, a jedynie przechowywać jego zawartość. Pozwoli to przejść bezpośrednio z wyszukiwarki do produktu,
kategoria - tutaj zastosujemy bardzo duże uproszczenie i będziemy przechowywać jedynie nazwę jednej kategorii. Wiem jednak że w sklepach internetowych produkty mogą być przypisane do wielu kategorii. Zaś same kategorie zagłębiają się tworząc struktury drzewiaste.
Skoro mamy już maksymalnie uproszczony model produktu to zobaczmy jak będzie wyglądała definicja mappingu:
PUT products
{
"mappings": {
"product": {
"properties": {
"nazwa": {
"type": "text",
"store": true
},
"producent": {
"type": "text",
"store": true
},
"cena": {
"type": "double"
},
"opis": {
"type": "text"
},
"url": {
"type": "keyword",
"store": true,
"index": false
},
"kategoria": {
"type": "text",
"fielddata": true,
"store": true
}
}
}
}
}
Zanim zaczniemy budować zapytania agregujące chciałbym abyście zwrócili uwagę na pole kategorii. Pole to jest typu text co w domyślnych ustawieniach wyklucza agregację danych po tym polu. Jednak można zmusić ElasticSearch-a, aby włączył agregację dla danego pola. Robimy to poprzez ustawienie parametru fielddata na true.
Mając gotowy schemat indeksu przydadzą się dane na których będziemy mogli uczyć się jak działa agregacja.
PUT products/product/1
{
"nazwa": "Xiaomi Redmi 4X",
"cena": 1200.00,
"producent": "Xiaomi",
"kategoria": "Elektronika"
}
PUT products/product/2
{
"nazwa": "iPad",
"cena": 2900.00,
"producent": "Apple",
"kategoria": "Tablety"
}
PUT products/product/3
{
"nazwa": "iPad Pro",
"cena": 3500.00,
"producent": "Apple",
"kategoria": "Tablety"
}
PUT products/product/4
{
"nazwa": "Tablet Dell Latitude11",
"cena": 1559.00,
"producent": "Lenovo",
"kategoria": "Tablety"
}
PUT products/product/5
{
"nazwa": "Lenovo Tab 10",
"cena": 545.00,
"producent": "Lenovo",
"kategoria": "Tablety"
}
PUT products/product/6
{
"nazwa": "Lenovo Yoga Tab 3",
"cena": 1359.00,
"producent": "Lenovo",
"kategoria": "Tablety"
}
PUT products/product/7
{
"nazwa": "Samsung Galaxy Tab S2",
"cena": 1199.00,
"producent": "Samsung",
"kategoria": "Tablety"
}
PUT products/product/8
{
"nazwa": "iPhone 6S",
"cena": 1299.00,
"producent": "Apple",
"kategoria": "Smartfony"
}
PUT products/product/9
{
"nazwa": "Samsung S8",
"cena": 1999.00,
"producent": "Samsung",
"kategoria": "Smartfony"
}
PUT products/product/10
{
"nazwa": "Huawei Honor 8",
"cena": 629.00,
"producent": "Huawei",
"kategoria": "Smartfony"
}
Wprowadzenie do agregacji danych
Przejdźmy do konkretów, które najlepiej wyjaśnią jak działa agregacja. Zaczniemy od czegoś prostego, będzie to zapytanie grupujące wyniki po polu kategoria:
GET _search
{
"aggs": {
"pogrupowane_po_ketegorii": {
"terms": {
"field": "kategoria"
}
}
}
}
Informację o agregacji w zapytaniu umieszczamy pod kluczem aggs następnie podajemy jak ma się nazywać nasz zbiór. W tym przypadku użyłem jakże pięknej nazwy pogrupowane_po_ketegorii. Następnie określamy rodzaj agregacji, ja zastosowałem bardzo prosty rodzaj terms. W rodzaju definiujemy parametry, dla terms mamy parametr field, który określa po którym polu ma nastąpić grupowanie.
O ile samo zapytanie nie wygląda przerażająco to wynik może już was nieco odstraszyć. Bowiem będzie wyglądał następująco:
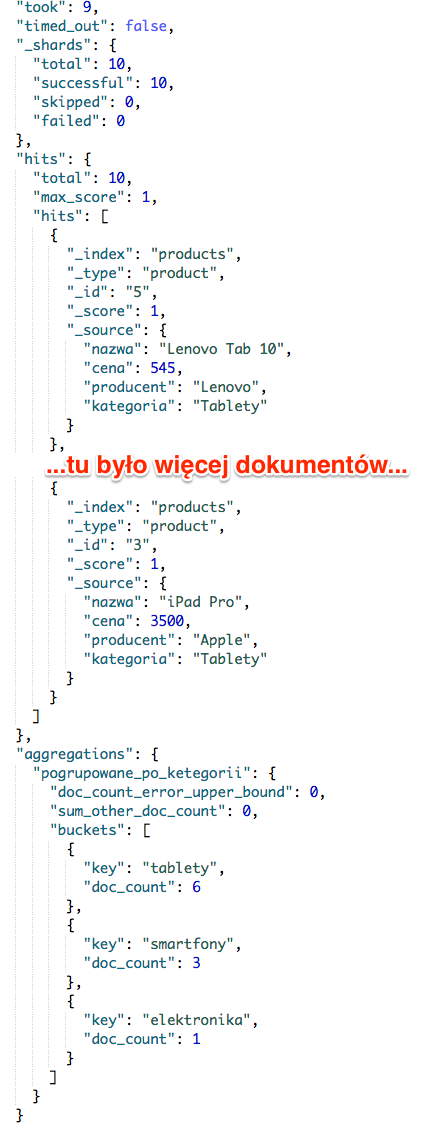
Wynika to z faktu, że oprócz samej agregacji zostały nam zwrócone także dokumentu, które na daną agregację się składają. W związku z czym dokonamy małej modyfikacji, aby wyeliminować zwracanie listy dokumentów. W tym celu dodajemy zapis "size": 0 przed agregacją.
GET _search
{
"size": 0,
"aggs": {
"pogrupowane_po_ketegorii": {
"terms": {
"field": "kategoria"
}
}
}
}
Co powinno się przełożyć na skrócenie zwracanego wyniku do poniższej postaci. W której to najbardziej interesuje nas kluz aggregations.
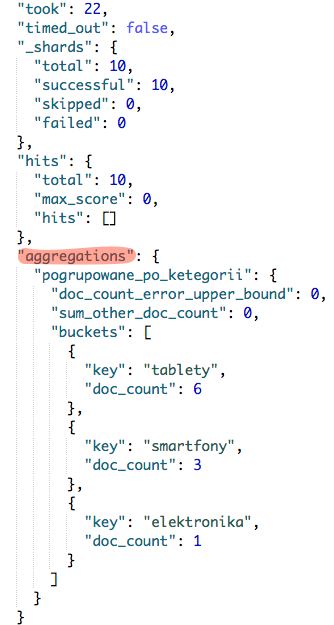
Aby lepiej zrozumieć jak nasze zapytania przekładają się na agregację przygotowałem małe objaśnienie.

Pod kluczem aggregations znajduje się nazwa naszej grupy pogrupowane_po_ketegorii. Następnie pod kluczem buckets znajdziemy zliczenie dokumentów w ramach danej kategorii.
Mam nadzieję, że do tej pory wszystko jest jasne i zrozumiałe bo czas na kolejny mały kroczek. Mechanizm agregacji jest bardzo elastyczny i pozwala nam na robienie wielu grup niezależnych od siebie oraz zagłębiania grup w sobie. Zacznijmy od prostszej opcji czyli dodamy kolejną grupę agregującą dane, tym razem po producencie. Nasze zapytanie będzie wyglądało następująco:
GET _search
{
"size": 0,
"aggs": {
"pogrupowane_po_ketegorii": {
"terms": {
"field": "kategoria"
}
},
"pogrupowane_po_producencie": {
"terms": {
"field": "producent"
}
}
}
}
Jak widać nowa grupa nazywa się pogrupowane_po_producencie i działa dokładnie tak samo jak poprzednia z tą różnicą, że grupowanie następuje po polu producent. Zobaczmy jak przełoży się to na zwrócone wyniki.
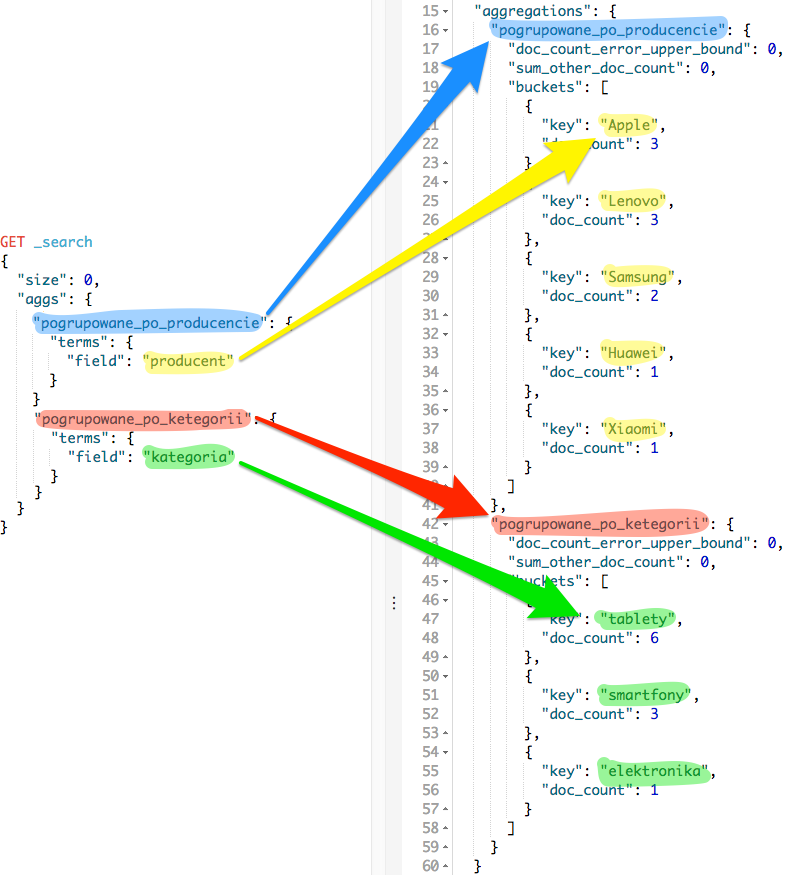
Zagregowane dane są dostępne pod nazwami grupy i ułożone obok siebie, czyli tak jak mogliśmy się spodziewać. Zobaczmy jak będzie wyglądało, gdy agregacje będą zagłębione w sobie:
GET _search
{
"size": 0,
"aggs": {
"pogrupowane_po_ketegorii": {
"terms": {
"field": "kategoria"
},
"aggs": {
"pogrupowane_po_producencie": {
"terms": {
"field": "producent"
}
}
}
}
}
}
Tak samo jak w przypadku definiowania agregacji pierwszego poziomu, tak samo w przypadku agregacji zagłębionych w sobie używamy klucza aggs. W ten sposób możemy tworzyć dowolne poziomy zagłębień jednak czym więcej zagłębień tym ciężeń nad tym zapanować. Skoro mamy już zapytanie czas przyjrzeć się zwracanym danym:

Standardowo mamy klucz aggregations, który zawiera nazwę grupy pierwszego poziomu pogrupowane_po_ketegorii. W strukturze tej znajdziemy klucz buckets, który zawiera pogrupowane wyniki. Czyli do tej pory jest identycznie jak w dwóch poprzednich przypadkach. Jednak teraz każdy wynik zawiera, dodatkowy klucz o nazwie pogrupowane_po_producencie. Czyli nazwa naszej grupy agregacji drugiego poziomu. I oczywiście w tej strukturze znajdziemy klucz buckets, który zawiera pogrupowane wyniki. W ten właśnie sposób możemy grupować i odczytywać pogrupowane dane.
Rodzaje agregacji
Agregując dokumenty musimy określić rodzaj agregacji. Do tej pory zetknęliśmy się tylko z jednym rodzajem agregacji, który nazywa się Bucket. To właśnie on był wykorzystywany do zliczania dokumentów w ramach kategorii i producentów.
Zobaczmy jakie rodzaje agregacji, są nam udostępniane przez ElasticSearch.
Bucket Aggregations
Ten rodzaj agregacji ma jedno zadanie. Jest nim tworzenie zbiorów na podstawie zdefiniowanych przez nas kryteriów. W ramach tego rodzaju agregacji zostaje nam udostępnionych wiele rodzajów kryteriów. Jedno jest nam już znane i nazywa się terms.
Należy wiedzieć, że ten rodzaj agregacji nie dostarcza nam żadnych danych metrycznych. Czyli nie dowiemy się jaka jest minimalna, maksymalna czy średnia wartość z danego pola. Co może na pierwszy rzut oka wydać się dość dziwne, przecież takie informacje to standard przy agregacji danych. Tutaj takich informacji nie znajdziemy, jednak przy połączeniu tego rodzaju agregacji z innym, będziemy w stanie uzyskać interesujące nas informacje.
Warto na sam koniec dodać, że pomimo wąskiej specjalizacji tego rodzaju agregacji mamy jedną bardzo istotną rzecz. Mianowicie każdy zbiór posiada informację ile zawiera w sobie dokumentów. Co często będzie wystarczającą informacją i nie będzie konieczności dodawania agregacji metrycznych.
Metrics Aggregations
Agregacje metryczne są świetnym uzupełnieniem dla Bucket aggregations. Co nie oznacza że nie mogą istnieć samodzielnie. W przypadku tego rodzaju agregacji mamy dostęp do typowych informacji metrycznych, czyli:
- Avg - wyciąganie średniej,
- Min - wartość minimalna,
- Max - wartość maksymalna,
- Sum - suma,
- Stats - zwraca listę statystyk (min, max, sum, count oraz avg) dla danego pola,
Oraz kilku bardziej specyficznych jak Geo Bounds Aggregation, który na podstawie współrzędnych geograficznych. Potrafi podać kwadrat w którym znajdują się współrzędne z danego zbioru.
Matrix Aggregations
Zacznijmy od faktu, że jest to jak na razie eksperymentalny typ agregacji i należy podchodzić do tego jako ciekawostki.
W zamyśle twórców, ten rodzaj agregacji ma służyć do prezentacji relacji pomiędzy dwoma polami. Co może być bardzo interesującym rozwiązaniem, ale z oceną poczekam do wersji finalnej ;)
Pipeline Aggregations
Ostatnim rodzajem agregacji jest Pipeline Aggregations i chyba jest to najbardziej złożony rodzaj agregacji. Kiedy zrozumiecie w pełni zasady tworzenia tych agregacji, uzyskacie ogromne możliwości.
Zacznijmy od tego, że ten rodzaj agregacji pracuje na wynikach innych agregacji. Co można zobrazować w ten sposób:
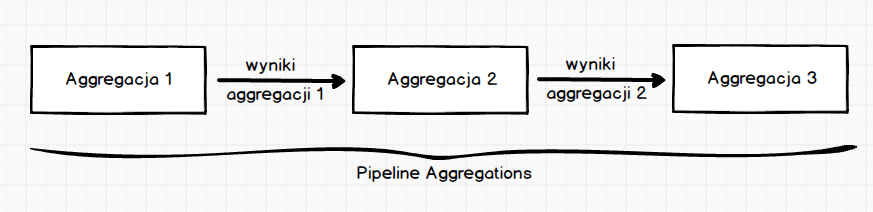
Dzięki takiemu podejściu jesteśmy w stanie stworzyć lejek, który będzie w stanie zawężać coraz bardziej wyniki. Daje nam to ogromne możliwości, jednak przejrzystość zapisu rozbudowanych lejków pozostawia wiele do życzenia.
Podsumowanie
Wpis ten jedynie dotknął tematu agregacji danych przez ElasticSearch-a. Jednak na jego podstawie możemy stwierdzić, że możliwości jakie są udostępniane przez wyszukiwarkę są ogromne. Mamy możliwość tworzenia zbiorów na podstawie różnych kryteriów, dowolnego ich zagłębiania oraz łączenia z metrykami. To już daje nam ogromne możliwości, a jeśli zgłębimy temat Pipeline Aggregations to będziemy w stanie wyczarować cuda ;)
I tym optymistycznym akcentem zakończę na dziś temat agregacji. Możecie jednak być pewni, że do niego wrócę przy okazji omawiania dokładniej Pipeline Aggregations.